 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Neural Model Performance through Natural Language Feedback on Their Explanations
Apr 18, 2021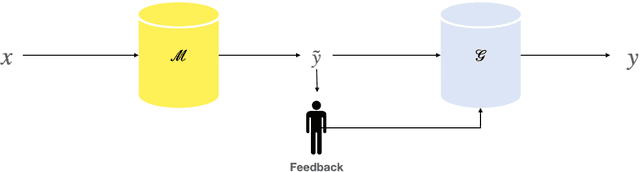
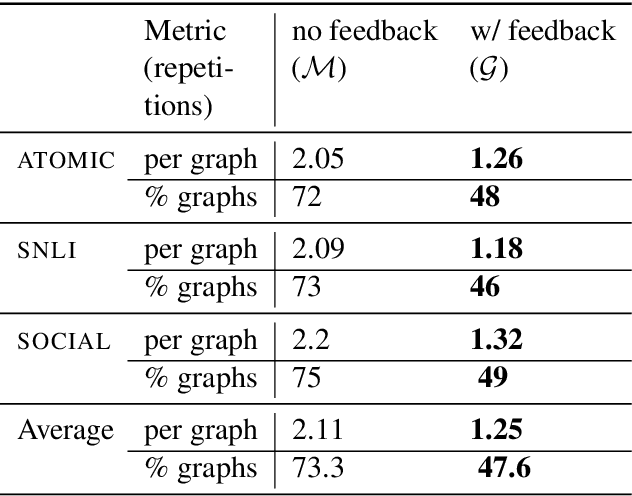
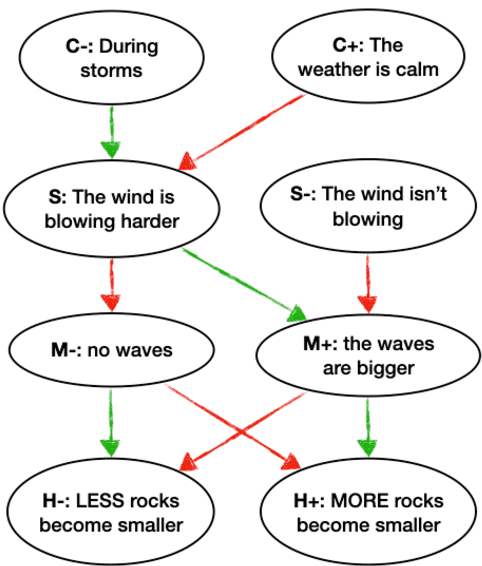
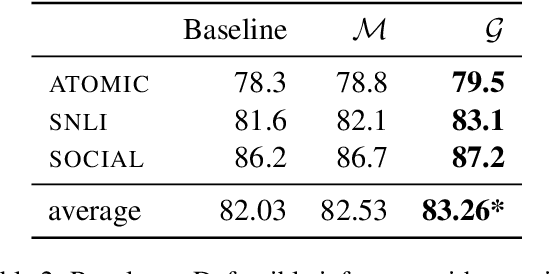
A class of explainable NLP models for reasoning tasks support their decisions by generating free-form or structured explanations, but what happens when these supporting structures contain errors? Our goal is to allow users to interactively correct explanation structures through natural language feedback. We introduce MERCURIE - an interactive system that refines its explanations for a given reasoning task by getting human feedback in natural language. Our approach generates graphs that have 40% fewer inconsistencies as compared with the off-the-shelf system. Further, simply appending the corrected explanation structures to the output leads to a gain of 1.2 points on accuracy on defeasible reasoning across all three domains. We release a dataset of over 450k graphs for defeasible reasoning generated by our system at https://tinyurl.com/mercurie .
CURIE: An Iterative Querying Approach for Reasoning About Situations
Apr 05, 2021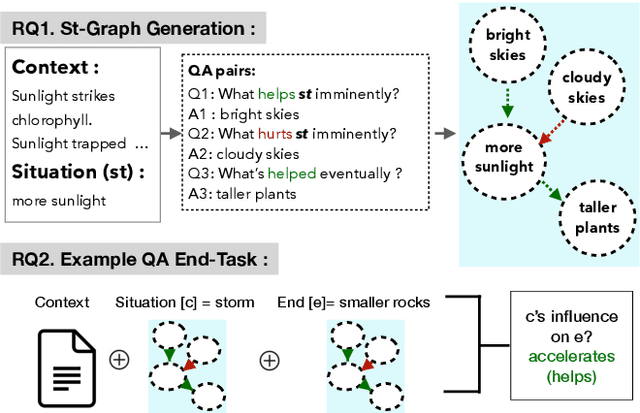
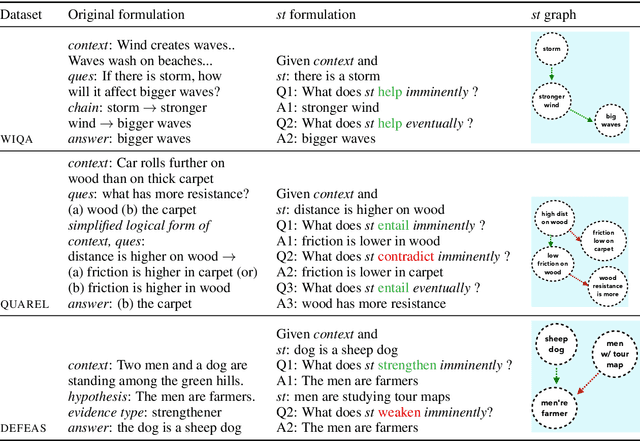
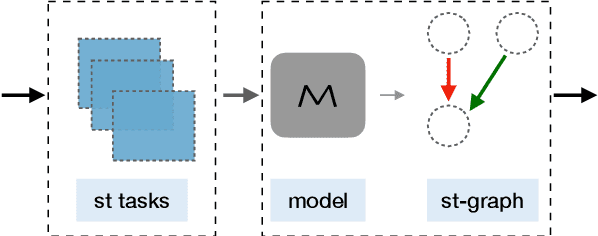
Recently, models have been shown to predict the effects of unexpected situations, e.g., would cloudy skies help or hinder plant growth? Given a context, the goal of such situational reasoning is to elicit the consequences of a new situation (st) that arises in that context. We propose a method to iteratively build a graph of relevant consequences explicitly in a structured situational graph (st-graph) using natural language queries over a finetuned language model (M). Across multiple domains, CURIE generates st-graphs that humans find relevant and meaningful in eliciting the consequences of a new situation. We show that st-graphs generated by CURIE improve a situational reasoning end task (WIQA-QA) by 3 points on accuracy by simply augmenting their input with our generated situational graphs, especially for a hard subset that requires background knowledge and multi-hop reasoning.
SelfExplain: A Self-Explaining Architecture for Neural Text Classifiers
Mar 23, 2021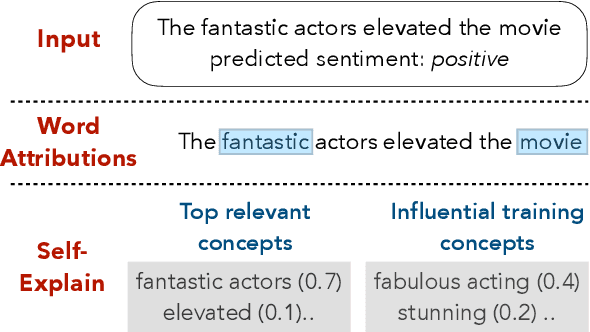
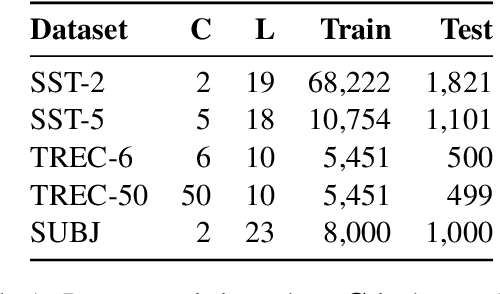
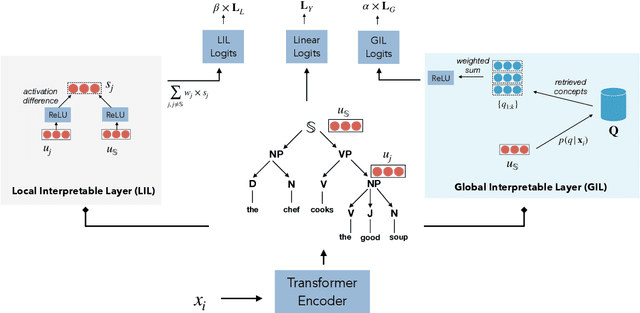
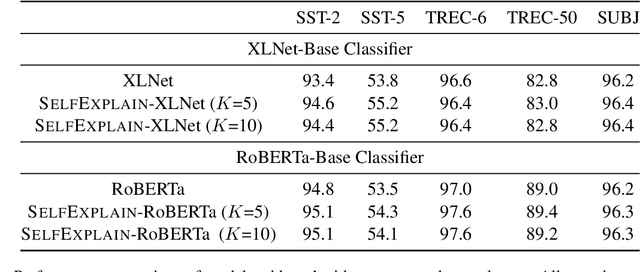
We introduce SelfExplain, a novel self-explaining framework that explains a text classifier's predictions using phrase-based concepts. SelfExplain augments existing neural classifiers by adding (1) a globally interpretable layer that identifies the most influential concepts in the training set for a given sample and (2) a locally interpretable layer that quantifies the contribution of each local input concept by computing a relevance score relative to the predicted label. Experiments across five text-classification datasets show that SelfExplain facilitates interpretability without sacrificing performance. Most importantly, explanations from SelfExplain are perceived as more understandable, adequately justifying and trustworthy by human judges compared to existing widely-used baselines.
A Dataset for Tracking Entities in Open Domain Procedural Text
Oct 31, 2020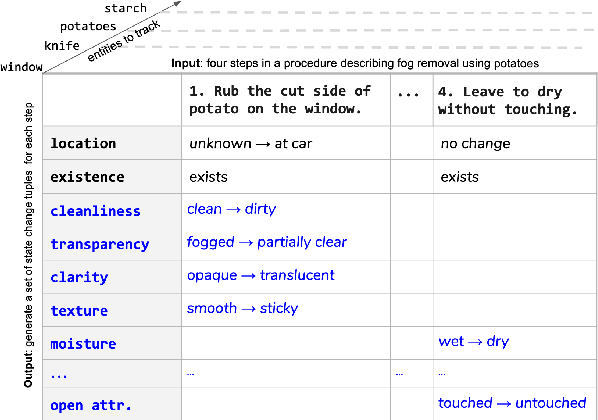
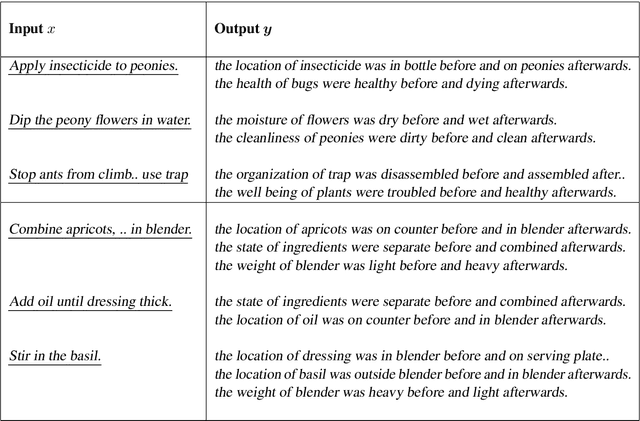
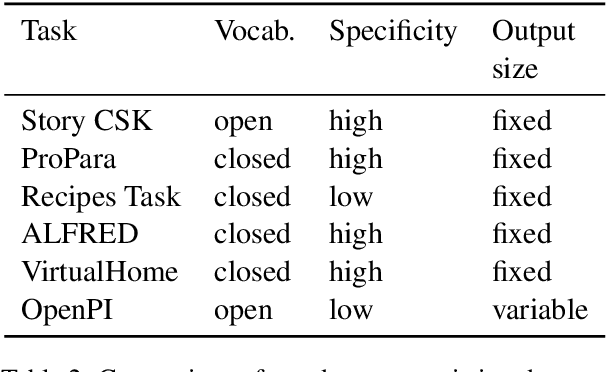

We present the first dataset for tracking state changes in procedural text from arbitrary domains by using an unrestricted (open) vocabulary. For example, in a text describing fog removal using potatoes, a car window may transition between being foggy, sticky,opaque, and clear. Previous formulations of this task provide the text and entities involved,and ask how those entities change for just a small, pre-defined set of attributes (e.g., location), limiting their fidelity. Our solution is a new task formulation where given just a procedural text as input, the task is to generate a set of state change tuples(entity, at-tribute, before-state, after-state)for each step,where the entity, attribute, and state values must be predicted from an open vocabulary. Using crowdsourcing, we create OPENPI1, a high-quality (91.5% coverage as judged by humans and completely vetted), and large-scale dataset comprising 29,928 state changes over 4,050 sentences from 810 procedural real-world paragraphs from WikiHow.com. A current state-of-the-art generation model on this task achieves 16.1% F1 based on BLEU metric, leaving enough room for novel model architectures.
EIGEN: Event Influence GENeration using Pre-trained Language Models
Oct 22, 2020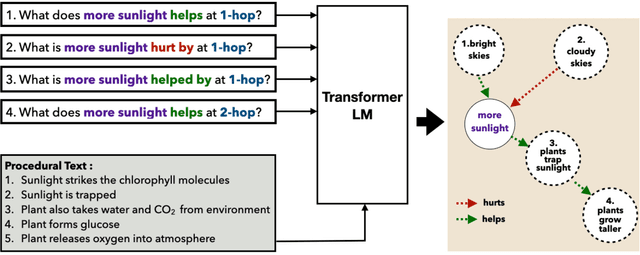
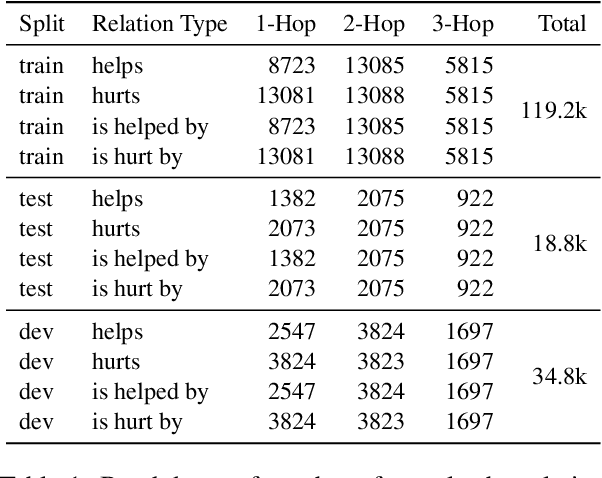

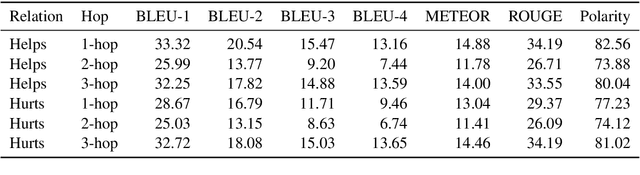
Reasoning about events and tracking their influences is fundamental to understanding processes. In this paper, we present EIGEN - a method to leverage pre-trained language models to generate event influences conditioned on a context, nature of their influence, and the distance in a reasoning chain. We also derive a new dataset for research and evaluation of methods for event influence generation. EIGEN outperforms strong baselines both in terms of automated evaluation metrics (by 10 ROUGE points) and human judgments on closeness to reference and relevance of generations. Furthermore, we show that the event influences generated by EIGEN improve the performance on a "what-if" Question Answering (WIQA) benchmark (over 3% F1), especially for questions that require background knowledge and multi-hop reasoning.
What-if I ask you to explain: Explaining the effects of perturbations in procedural text
May 04, 2020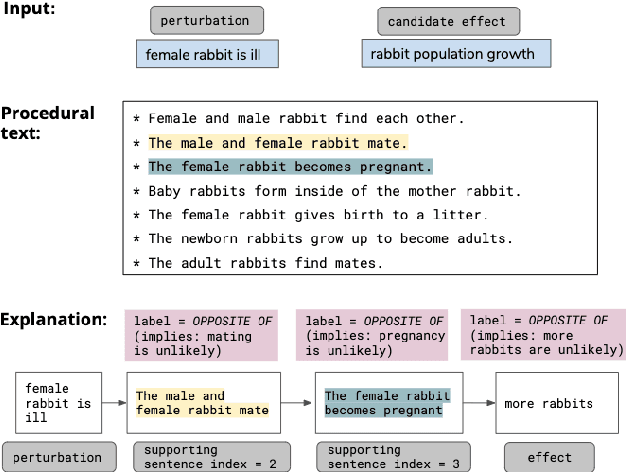
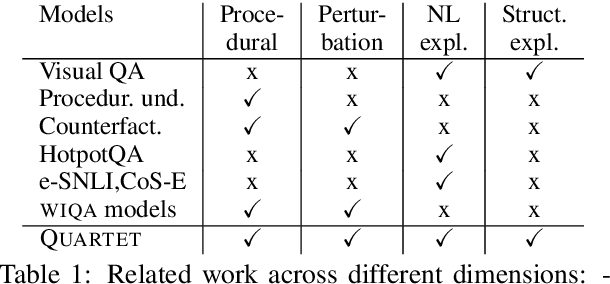

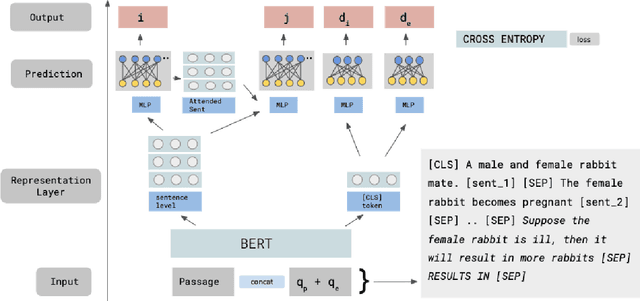
We address the task of explaining the effects of perturbations in procedural text, an important test of process comprehension. Consider a passage describing a rabbit's life-cycle: humans can easily explain the effect on the rabbit population if a female rabbit becomes ill -- i.e., the female rabbit would not become pregnant, and as a result not have babies leading to a decrease in rabbit population. We present QUARTET, a system that constructs such explanations from paragraphs, by modeling the explanation task as a multitask learning problem. QUARTET provides better explanations (based on the sentences in the procedural text) compared to several strong baselines on a recent process comprehension benchmark. We also present a surprising secondary effect: our model also achieves a new SOTA with a 7% absolute F1 improvement on a downstream QA task. This illustrates that good explanations do not have to come at the expense of end task performance.
StructSum: Incorporating Latent and Explicit Sentence Dependencies for Single Document Summarization
Mar 01, 2020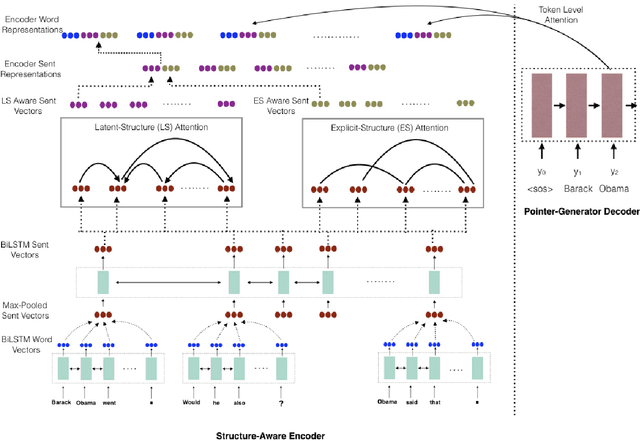
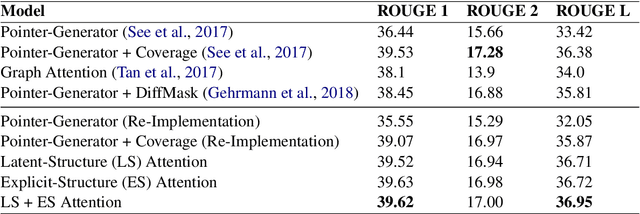
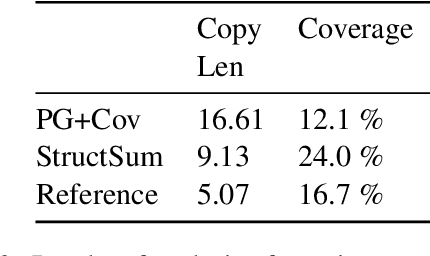
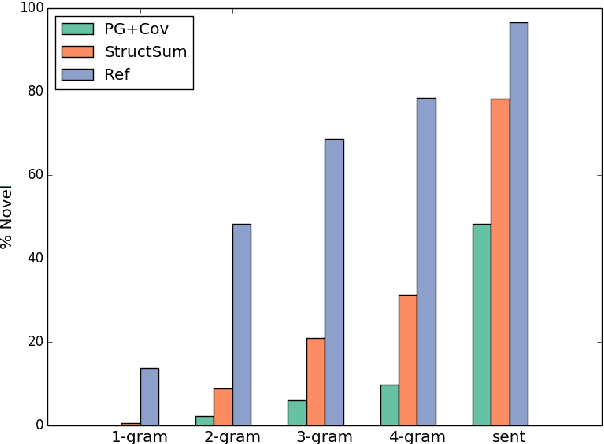
Traditional preneural approaches to single document summarization relied on modeling the intermediate structure of a document before generating the summary. In contrast, the current state of the art neural summarization models do not preserve any intermediate structure, resorting to encoding the document as a sequence of tokens. The goal of this work is two-fold: to improve the quality of generated summaries and to learn interpretable document representations for summarization. To this end, we propose incorporating latent and explicit sentence dependencies into single-document summarization models. We use structure-aware encoders to induce latent sentence relations, and inject explicit coreferring mention graph across sentences to incorporate explicit structure. On the CNN/DM dataset, our model outperforms standard baselines and provides intermediate latent structures for analysis. We present an extensive analysis of our summaries and show that modeling document structure reduces copying long sequences and incorporates richer content from the source document while maintaining comparable summary lengths and an increased degree of abstraction.
Simple and Effective Semi-Supervised Question Answering
Apr 02, 2018
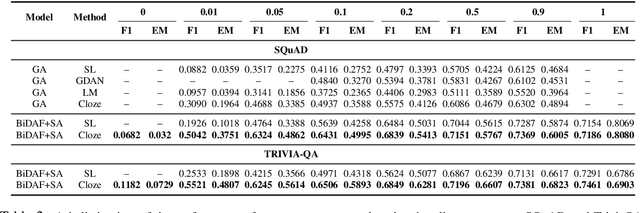
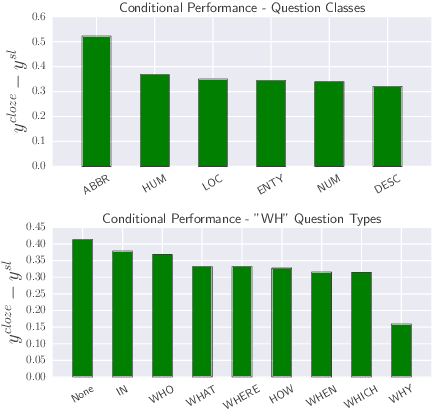
Recent success of deep learning models for the task of extractive Question Answering (QA) is hinged on the availability of large annotated corpora. However, large domain specific annotated corpora are limited and expensive to construct. In this work, we envision a system where the end user specifies a set of base documents and only a few labelled examples. Our system exploits the document structure to create cloze-style questions from these base documents; pre-trains a powerful neural network on the cloze style questions; and further fine-tunes the model on the labeled examples. We evaluate our proposed system across three diverse datasets from different domains, and find it to be highly effective with very little labeled data. We attain more than 50% F1 score on SQuAD and TriviaQA with less than a thousand labelled examples. We are also releasing a set of 3.2M cloze-style questions for practitioners to use while building QA systems.
Gated-Attention Architectures for Task-Oriented Language Grounding
Jan 09, 2018
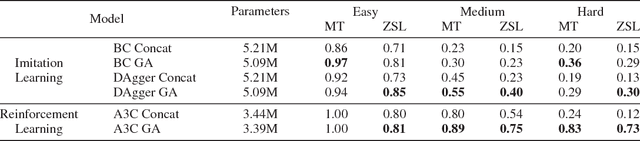
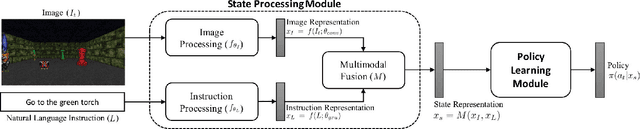
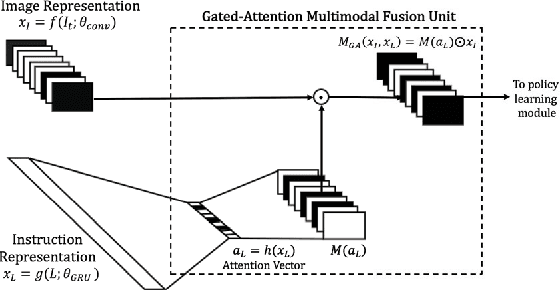
To perform tasks specified by natural language instructions, autonomous agents need to extract semantically meaningful representations of language and map it to visual elements and actions in the environment. This problem is called task-oriented language grounding. We propose an end-to-end trainable neural architecture for task-oriented language grounding in 3D environments which assumes no prior linguistic or perceptual knowledge and requires only raw pixels from the environment and the natural language instruction as input. The proposed model combines the image and text representations using a Gated-Attention mechanism and learns a policy to execute the natural language instruction using standard reinforcement and imitation learning methods. We show the effectiveness of the proposed model on unseen instructions as well as unseen maps, both quantitatively and qualitatively. We also introduce a novel environment based on a 3D game engine to simulate the challenges of task-oriented language grounding over a rich set of instructions and environment states.