 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep PatchMatch MVS with Learned Patch Coplanarity, Geometric Consistency and Adaptive Pixel Sampling
Oct 14, 2022
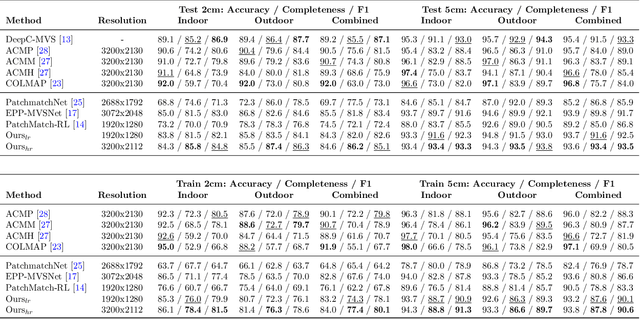
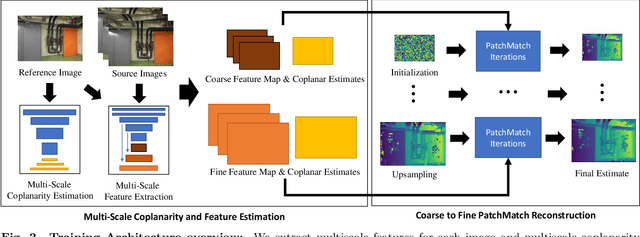

Recent work in multi-view stereo (MVS) combines learnable photometric scores and regularization with PatchMatch-based optimization to achieve robust pixelwise estimates of depth, normals, and visibility. However, non-learning based methods still outperform for large scenes with sparse views, in part due to use of geometric consistency constraints and ability to optimize over many views at high resolution. In this paper, we build on learning-based approaches to improve photometric scores by learning patch coplanarity and encourage geometric consistency by learning a scaled photometric cost that can be combined with reprojection error. We also propose an adaptive pixel sampling strategy for candidate propagation that reduces memory to enable training on larger resolution with more views and a larger encoder. These modifications lead to 6-15% gains in accuracy and completeness on the challenging ETH3D benchmark, resulting in higher F1 performance than the widely used state-of-the-art non-learning approaches ACMM and ACMP.
Language Models with Image Descriptors are Strong Few-Shot Video-Language Learners
May 29, 2022
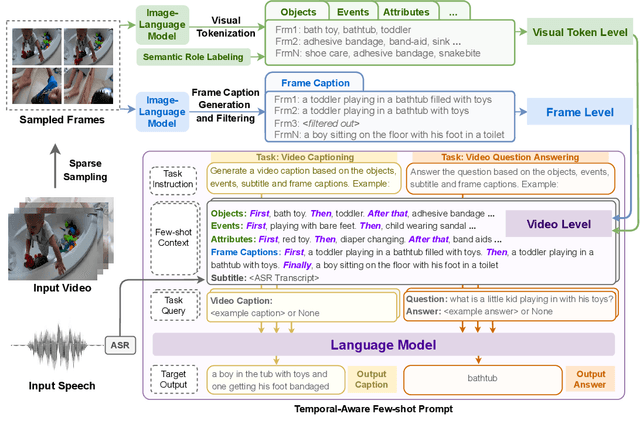
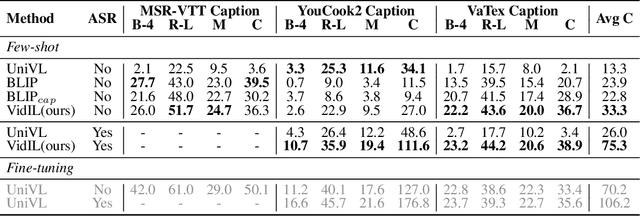

The goal of this work is to build flexible video-language models that can generalize to various video-to-text tasks from few examples, such as domain-specific captioning, question answering, and future event prediction. Existing few-shot video-language learners focus exclusively on the encoder, resulting in the absence of a video-to-text decoder to handle generative tasks. Video captioners have been pretrained on large-scale video-language datasets, but they rely heavily on finetuning and lack the ability to generate text for unseen tasks in a few-shot setting. We propose VidIL, a few-shot Video-language Learner via Image and Language models, which demonstrates strong performance on few-shot video-to-text tasks without the necessity of pretraining or finetuning on any video datasets. We use the image-language models to translate the video content into frame captions, object, attribute, and event phrases, and compose them into a temporal structure template. We then instruct a language model, with a prompt containing a few in-context examples, to generate a target output from the composed content. The flexibility of prompting allows the model to capture any form of text input, such as automatic speech recognition (ASR) transcripts. Our experiments demonstrate the power of language models in understanding videos on a wide variety of video-language tasks, including video captioning, video question answering, video caption retrieval, and video future event prediction. Especially, on video future event prediction, our few-shot model significantly outperforms state-of-the-art supervised models trained on large-scale video datasets. Code and resources are publicly available for research purposes at https://github.com/MikeWangWZHL/VidIL .
GRIT: General Robust Image Task Benchmark
May 02, 2022
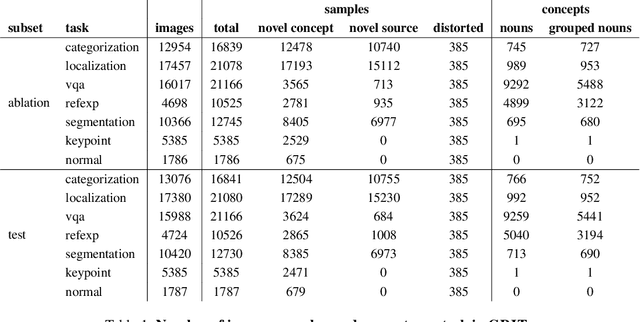
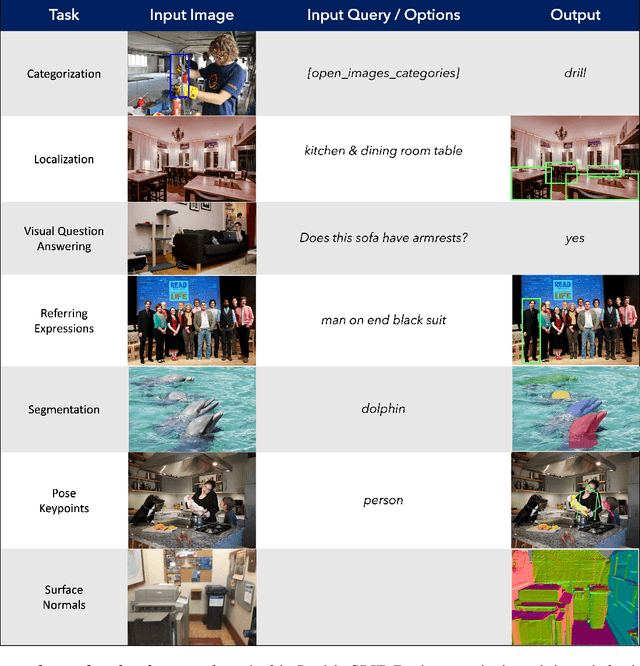
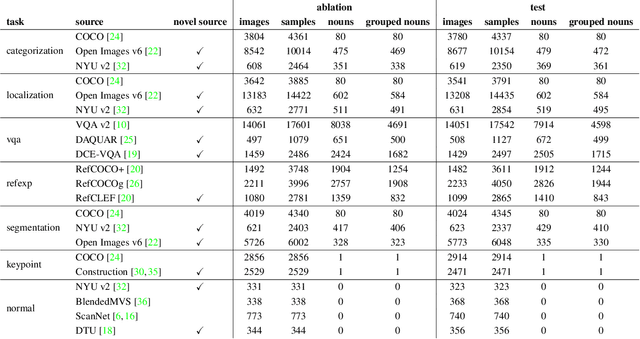
Computer vision models excel at making predictions when the test distribution closely resembles the training distribution. Such models have yet to match the ability of biological vision to learn from multiple sources and generalize to new data sources and tasks. To facilitate the development and evaluation of more general vision systems, we introduce the General Robust Image Task (GRIT) benchmark. GRIT evaluates the performance, robustness, and calibration of a vision system across a variety of image prediction tasks, concepts, and data sources. The seven tasks in GRIT are selected to cover a range of visual skills: object categorization, object localization, referring expression grounding, visual question answering, segmentation, human keypoint detection, and surface normal estimation. GRIT is carefully designed to enable the evaluation of robustness under image perturbations, image source distribution shift, and concept distribution shift. By providing a unified platform for thorough assessment of skills and concepts learned by a vision model, we hope GRIT catalyzes the development of performant and robust general purpose vision systems.
Webly Supervised Concept Expansion for General Purpose Vision Models
Feb 04, 2022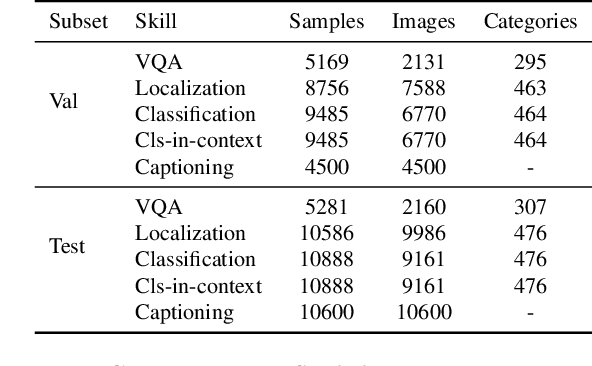
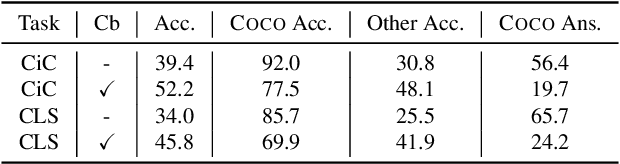
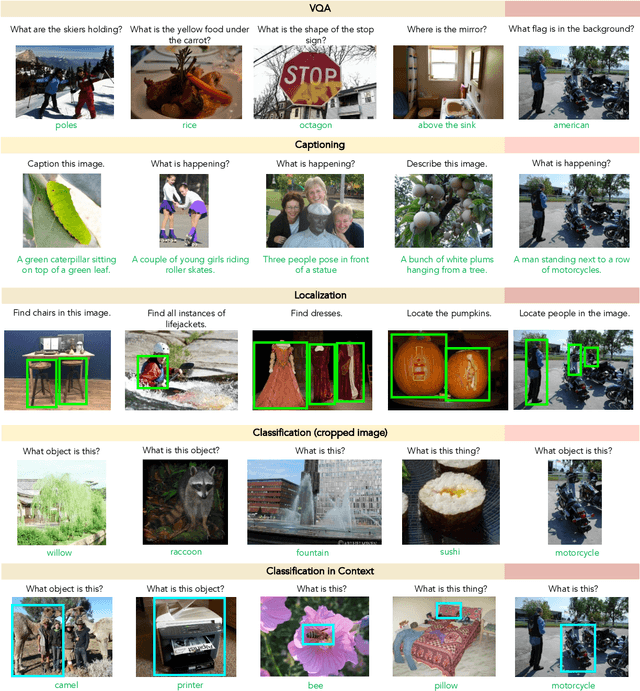
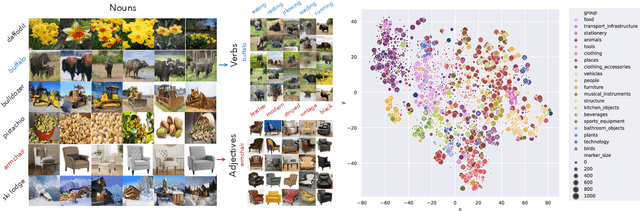
General purpose vision (GPV) systems are models that are designed to solve a wide array of visual tasks without requiring architectural changes. Today, GPVs primarily learn both skills and concepts from large fully supervised datasets. Scaling GPVs to tens of thousands of concepts by acquiring data to learn each concept for every skill quickly becomes prohibitive. This work presents an effective and inexpensive alternative: learn skills from fully supervised datasets, learn concepts from web image search results, and leverage a key characteristic of GPVs -- the ability to transfer visual knowledge across skills. We use a dataset of 1M+ images spanning 10k+ visual concepts to demonstrate webly-supervised concept expansion for two existing GPVs (GPV-1 and VL-T5) on 3 benchmarks - 5 COCO based datasets (80 primary concepts), a newly curated series of 5 datasets based on the OpenImages and VisualGenome repositories (~500 concepts) and the Web-derived dataset (10k+ concepts). We also propose a new architecture, GPV-2 that supports a variety of tasks -- from vision tasks like classification and localization to vision+language tasks like QA and captioning to more niche ones like human-object interaction recognition. GPV-2 benefits hugely from web data, outperforms GPV-1 and VL-T5 across these benchmarks, and does well in a 0-shot setting at action and attribute recognition.
PatchMatch-RL: Deep MVS with Pixelwise Depth, Normal, and Visibility
Aug 19, 2021
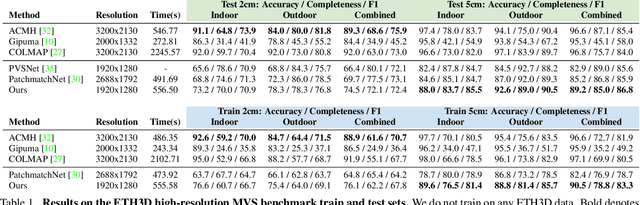
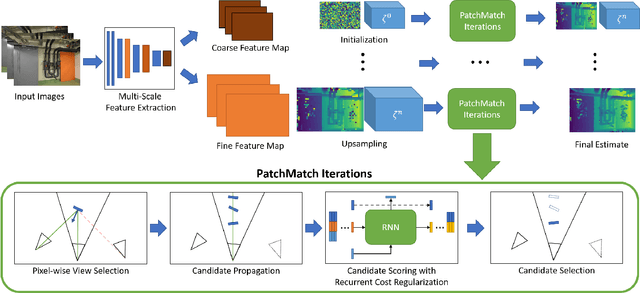
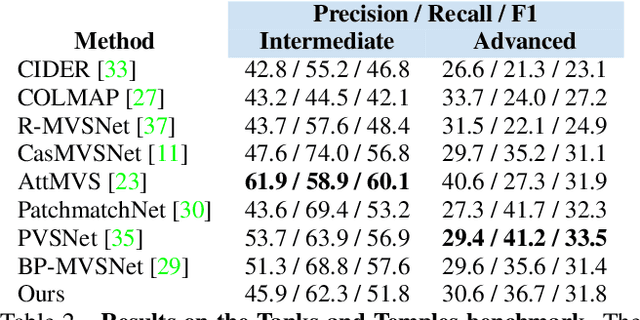
Recent learning-based multi-view stereo (MVS) methods show excellent performance with dense cameras and small depth ranges. However, non-learning based approaches still outperform for scenes with large depth ranges and sparser wide-baseline views, in part due to their PatchMatch optimization over pixelwise estimates of depth, normals, and visibility. In this paper, we propose an end-to-end trainable PatchMatch-based MVS approach that combines advantages of trainable costs and regularizations with pixelwise estimates. To overcome the challenge of the non-differentiable PatchMatch optimization that involves iterative sampling and hard decisions, we use reinforcement learning to minimize expected photometric cost and maximize likelihood of ground truth depth and normals. We incorporate normal estimation by using dilated patch kernels, and propose a recurrent cost regularization that applies beyond frontal plane-sweep algorithms to our pixelwise depth/normal estimates. We evaluate our method on widely used MVS benchmarks, ETH3D and Tanks and Temples (TnT), and compare to other state of the art learning based MVS models. On ETH3D, our method outperforms other recent learning-based approaches and performs comparably on advanced TnT.
Towards General Purpose Vision Systems
Apr 01, 2021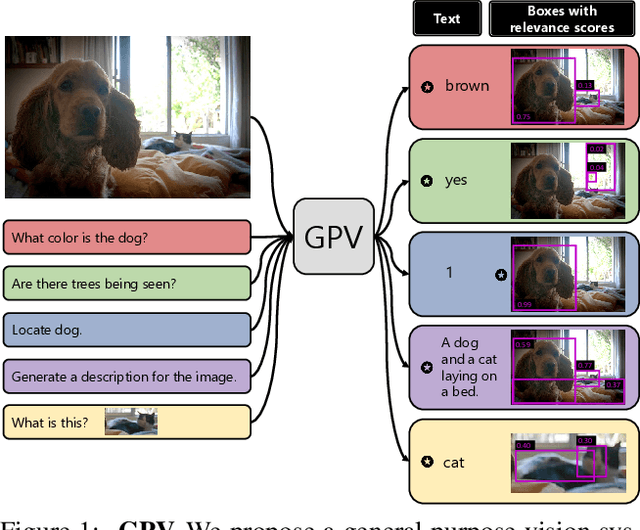
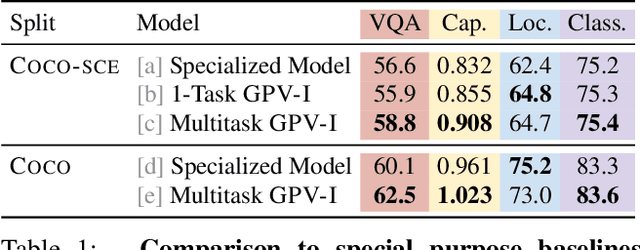
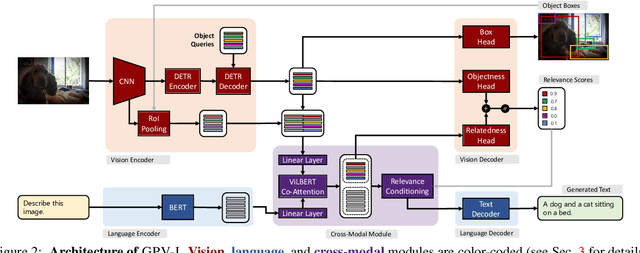

A special purpose learning system assumes knowledge of admissible tasks at design time. Adapting such a system to unforeseen tasks requires architecture manipulation such as adding an output head for each new task or dataset. In this work, we propose a task-agnostic vision-language system that accepts an image and a natural language task description and outputs bounding boxes, confidences, and text. The system supports a wide range of vision tasks such as classification, localization, question answering, captioning, and more. We evaluate the system's ability to learn multiple skills simultaneously, to perform tasks with novel skill-concept combinations, and to learn new skills efficiently and without forgetting.
Learning Curves for Analysis of Deep Networks
Oct 21, 2020
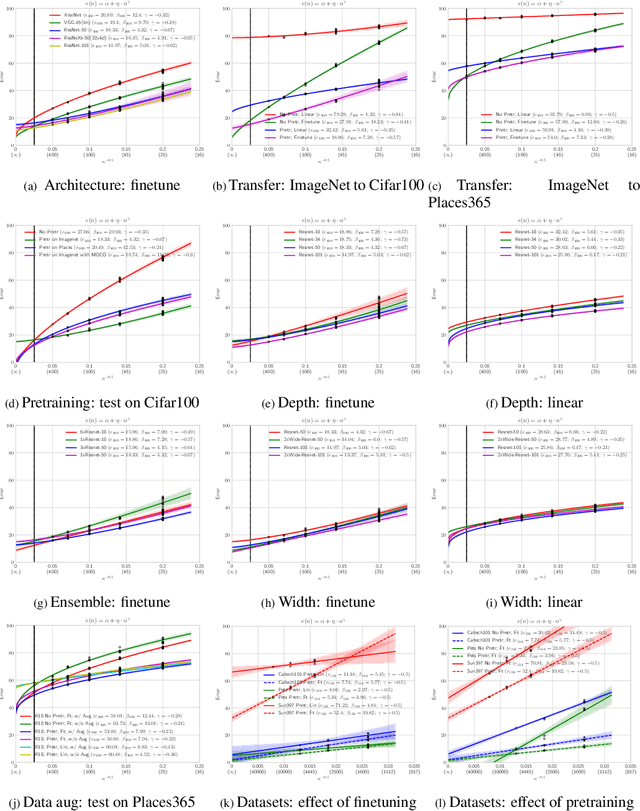

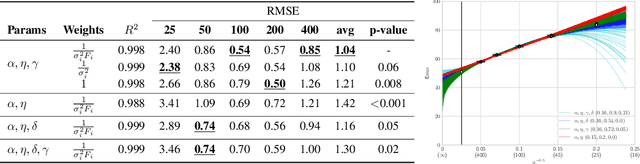
A learning curve models a classifier's test error as a function of the number of training samples. Prior works show that learning curves can be used to select model parameters and extrapolate performance. We investigate how to use learning curves to analyze the impact of design choices, such as pre-training, architecture, and data augmentation. We propose a method to robustly estimate learning curves, abstract their parameters into error and data-reliance, and evaluate the effectiveness of different parameterizations. We also provide several interesting observations based on learning curves for a variety of image classification models.
Contrastive Learning for Weakly Supervised Phrase Grounding
Jun 17, 2020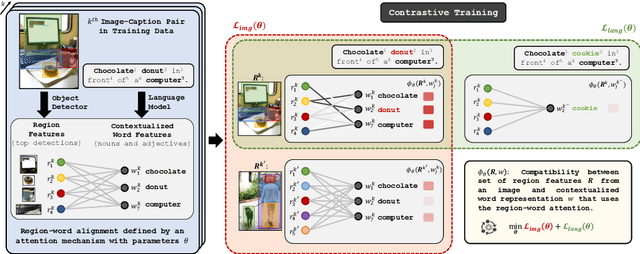
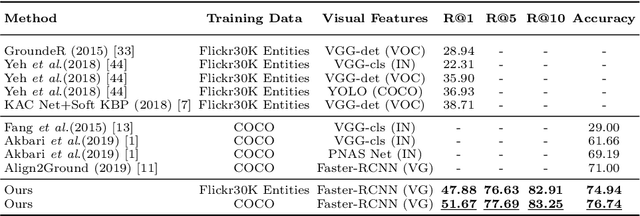
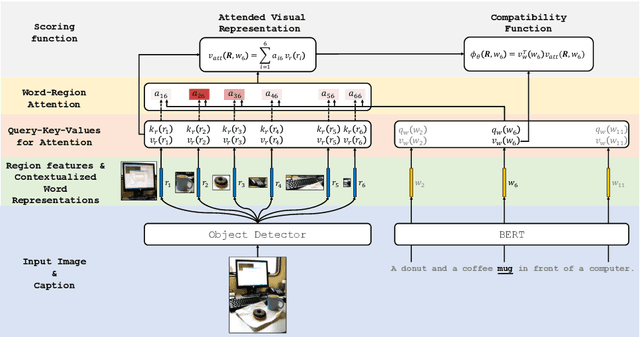

Phrase grounding, the problem of associating image regions to caption words, is a crucial component of vision-language tasks. We show that phrase grounding can be learned by optimizing word-region attention to maximize a lower bound on mutual information between images and caption words. Given pairs of images and captions, we maximize compatibility of the attention-weighted regions and the words in the corresponding caption, compared to non-corresponding pairs of images and captions. A key idea is to construct effective negative captions for learning through language model guided word substitutions. Training with our negatives yields a $\sim10\%$ absolute gain in accuracy over randomly-sampled negatives from the training data. Our weakly supervised phrase grounding model trained on COCO-Captions shows a healthy gain of $5.7\%$ to achieve $76.7\%$ accuracy on Flickr30K Entities benchmark.
Boundary Cues for 3D Object Shape Recovery
Dec 24, 2019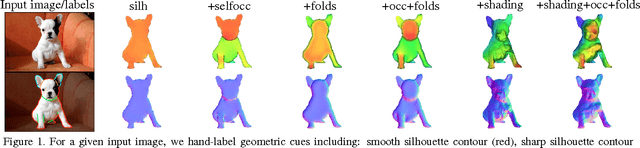
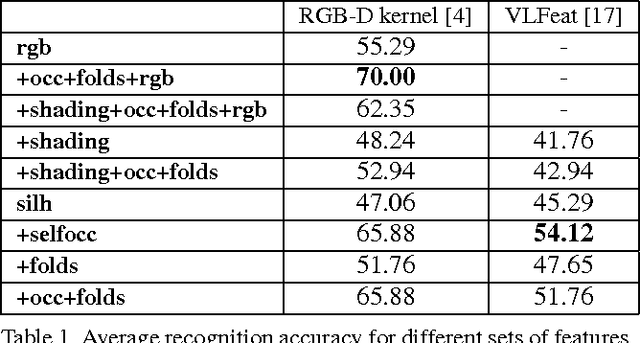


Early work in computer vision considered a host of geometric cues for both shape reconstruction and recognition. However, since then, the vision community has focused heavily on shading cues for reconstruction, and moved towards data-driven approaches for recognition. In this paper, we reconsider these perhaps overlooked "boundary" cues (such as self occlusions and folds in a surface), as well as many other established constraints for shape reconstruction. In a variety of user studies and quantitative tasks, we evaluate how well these cues inform shape reconstruction (relative to each other) in terms of both shape quality and shape recognition. Our findings suggest many new directions for future research in shape reconstruction, such as automatic boundary cue detection and relaxing assumptions in shape from shading (e.g. orthographic projection, Lambertian surfaces).
Dreaming to Distill: Data-free Knowledge Transfer via DeepInversion
Dec 18, 2019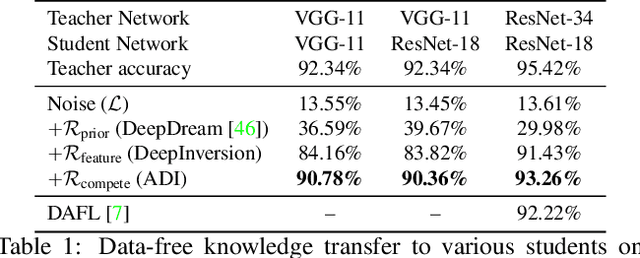
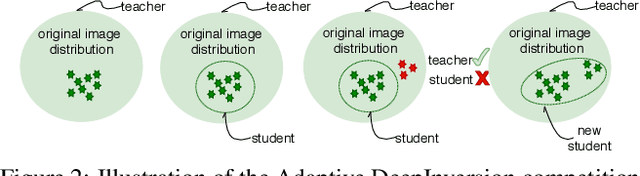
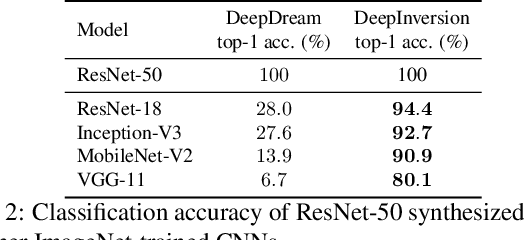

We introduce DeepInversion, a new method for synthesizing images from the image distribution used to train a deep neural network. We 'invert' a trained network (teacher) to synthesize class-conditional input images starting from random noise, without using any additional information about the training dataset. Keeping the teacher fixed, our method optimizes the input while regularizing the distribution of intermediate feature maps using information stored in the batch normalization layers of the teacher. Further, we improve the diversity of synthesized images using Adaptive DeepInversion, which maximizes the Jensen-Shannon divergence between the teacher and student network logits. The resulting synthesized images from networks trained on the CIFAR-10 and ImageNet datasets demonstrate high fidelity and degree of realism, and help enable a new breed of data-free applications - ones that do not require any real images or labeled data. We demonstrate the applicability of our proposed method to three tasks of immense practical importance -- (i) data-free network pruning, (ii) data-free knowledge transfer, and (iii) data-free continual learning.