 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemultivariateGPT: a decoder-only transformer for multivariate categorical and numeric data
May 27, 2025Real-world processes often generate data that are a mix of categorical and numeric values that are recorded at irregular and informative intervals. Discrete token-based approaches are limited in numeric representation capacity while methods like neural ordinary differential equations are not well suited for categorical data or informative sampling and require augmentation to handle certain classes of trajectories. Here, we present multivariateGPT, a single architecture for modeling sequences of mixed categorical (including tokenized text) and numeric data. This is accomplished with an autoregressive sequence decomposition, embedding scheme, and loss function that extend the next token prediction task to likelihood estimation of the joint distribution of next token class and value. We demonstrate how this approach can efficiently learn to generalize patterns in simple physical systems and model complex time series including electrocardiograms and multivariate electronic health record data. This work extends the utility of transformer based models to additional classes of data.
LAMP: Extracting Locally Linear Decision Surfaces from LLM World Models
May 17, 2025We introduce \textbf{LAMP} (\textbf{L}inear \textbf{A}ttribution \textbf{M}apping \textbf{P}robe), a method that shines light onto a black-box language model's decision surface and studies how reliably a model maps its stated reasons to its predictions through a locally linear model approximating the decision surface. LAMP treats the model's own self-reported explanations as a coordinate system and fits a locally linear surrogate that links those weights to the model's output. By doing so, it reveals which stated factors steer the model's decisions, and by how much. We apply LAMP to three tasks: \textit{sentiment analysis}, \textit{controversial-topic detection}, and \textit{safety-prompt auditing}. Across these tasks, LAMP reveals that many LLMs exhibit locally linear decision landscapes. In addition, these surfaces correlate with human judgments on explanation quality and, on a clinical case-file data set, aligns with expert assessments. Since LAMP operates without requiring access to model gradients, logits, or internal activations, it serves as a practical and lightweight framework for auditing proprietary language models, and enabling assessment of whether a model behaves consistently with the explanations it provides.
Trajectory Flow Matching with Applications to Clinical Time Series Modeling
Oct 28, 2024Modeling stochastic and irregularly sampled time series is a challenging problem found in a wide range of applications, especially in medicine. Neural stochastic differential equations (Neural SDEs) are an attractive modeling technique for this problem, which parameterize the drift and diffusion terms of an SDE with neural networks. However, current algorithms for training Neural SDEs require backpropagation through the SDE dynamics, greatly limiting their scalability and stability. To address this, we propose Trajectory Flow Matching (TFM), which trains a Neural SDE in a simulation-free manner, bypassing backpropagation through the dynamics. TFM leverages the flow matching technique from generative modeling to model time series. In this work we first establish necessary conditions for TFM to learn time series data. Next, we present a reparameterization trick which improves training stability. Finally, we adapt TFM to the clinical time series setting, demonstrating improved performance on three clinical time series datasets both in terms of absolute performance and uncertainty prediction.
Making Logic Learnable With Neural Networks
Feb 18, 2020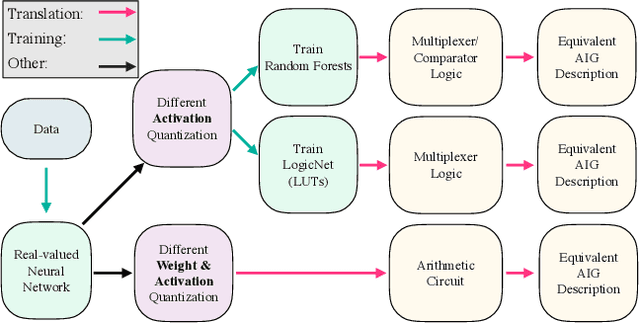
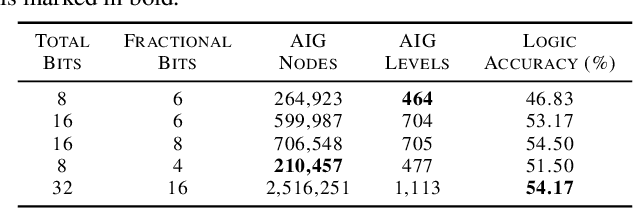

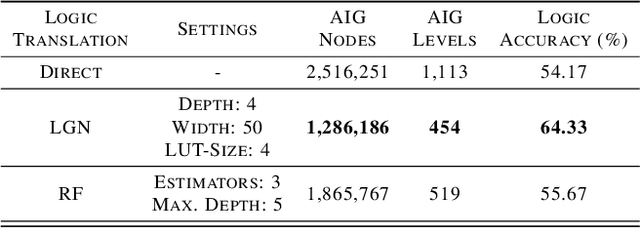
While neural networks are good at learning unspecified functions from training samples, they cannot be directly implemented in hardware and are often not interpretable or formally verifiable. On the other hand, logic circuits are implementable, verifiable, and interpretable but are not able to learn from training data in a generalizable way. We propose a novel logic learning pipeline that combines the advantages of neural networks and logic circuits. Our pipeline first trains a neural network on a classification task, and then translates this, first to random forests or look-up tables, and then to AND-Inverter logic. We show that our pipeline maintains greater accuracy than naive translations to logic, and minimizes the logic such that it is more interpretable and has decreased hardware cost. We show the utility of our pipeline on a network that is trained on biomedical data from patients presenting with gastrointestinal bleeding with the prediction task of determining if patients need immediate hospital-based intervention. This approach could be applied to patient care to provide risk stratification and guide clinical decision-making.