 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Classification through Weak Supervision in Context-specific Conversational Agent Development for Teacher Education
Oct 23, 2020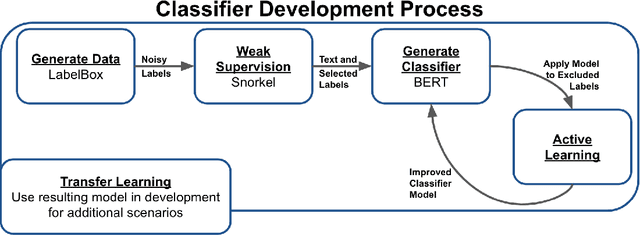

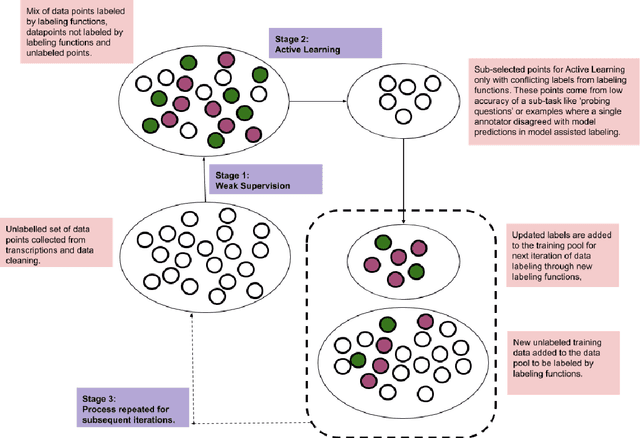

Machine learning techniques applied to the Natural Language Processing (NLP) component of conversational agent development show promising results for improved accuracy and quality of feedback that a conversational agent can provide. The effort required to develop an educational scenario specific conversational agent is time consuming as it requires domain experts to label and annotate noisy data sources such as classroom videos. Previous approaches to modeling annotations have relied on labeling thousands of examples and calculating inter-annotator agreement and majority votes in order to model the necessary scenarios. This method, while proven successful, ignores individual annotator strengths in labeling a data point and under-utilizes examples that do not have a majority vote for labeling. We propose using a multi-task weak supervision method combined with active learning to address these concerns. This approach requires less labeling than traditional methods and shows significant improvements in precision, efficiency, and time-requirements than the majority vote method (Ratner 2019). We demonstrate the validity of this method on the Google Jigsaw data set and then propose a scenario to apply this method using the Instructional Quality Assessment(IQA) to define the categories for labeling. We propose using probabilistic modeling of annotator labeling to generate active learning examples to further label the data. Active learning is able to iteratively improve the training performance and accuracy of the original classification model. This approach combines state-of-the art labeling techniques of weak supervision and active learning to optimize results in the educational domain and could be further used to lessen the data requirements for expanded scenarios within the education domain through transfer learning.
Geometry matters: Exploring language examples at the decision boundary
Oct 14, 2020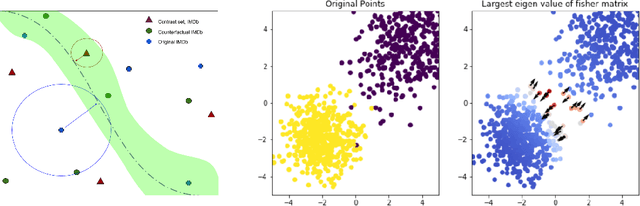


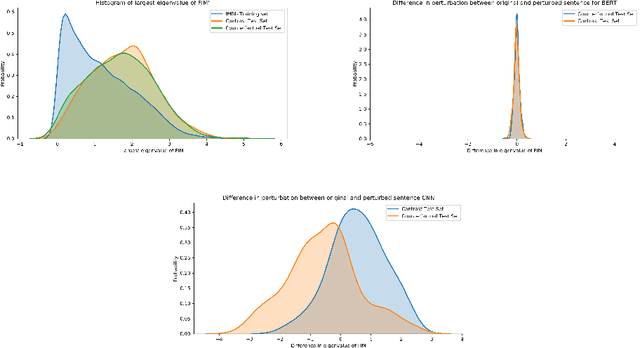
A growing body of recent evidence has highlighted the limitations of natural language processing (NLP) datasets and classifiers. These include the presence of annotation artifacts in datasets, classifiers relying on shallow features like a single word (e.g., if a movie review has the word "romantic", the review tends to be positive), or unnecessary words (e.g., learning a proper noun to classify a movie as positive or negative). The presence of such artifacts has subsequently led to the development of challenging datasets to force the model to generalize better. While a variety of heuristic strategies, such as counterfactual examples and contrast sets, have been proposed, the theoretical justification about what makes these examples difficult is often lacking or unclear. In this paper, using tools from information geometry, we propose a theoretical way to quantify the difficulty of an example in NLP. Using our approach, we explore difficult examples for two popular NLP architectures. We discover that both BERT and CNN are susceptible to single word substitutions in high difficulty examples. Consequently, examples with low difficulty scores tend to be robust to multiple word substitutions. Our analysis shows that perturbations like contrast sets and counterfactual examples are not necessarily difficult for the model, and they may not be accomplishing the intended goal. Our approach is simple, architecture agnostic, and easily extendable to other datasets. All the code used will be made publicly available, including a tool to explore the difficult examples for other datasets.
learn2learn: A Library for Meta-Learning Research
Aug 28, 2020Meta-learning researchers face two fundamental issues in their empirical work: prototyping and reproducibility. Researchers are prone to make mistakes when prototyping new algorithms and tasks because modern meta-learning methods rely on unconventional functionalities of machine learning frameworks. In turn, reproducing existing results becomes a tedious endeavour -- a situation exacerbated by the lack of standardized implementations and benchmarks. As a result, researchers spend inordinate amounts of time on implementing software rather than understanding and developing new ideas. This manuscript introduces learn2learn, a library for meta-learning research focused on solving those prototyping and reproducibility issues. learn2learn provides low-level routines common across a wide-range of meta-learning techniques (e.g. meta-descent, meta-reinforcement learning, few-shot learning), and builds standardized interfaces to algorithms and benchmarks on top of them. In releasing learn2learn under a free and open source license, we hope to foster a community around standardized software for meta-learning research.