 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Networks for Brain Graph Learning: A Survey
Jun 01, 2024



Exploring the complex structure of the human brain is crucial for understanding its functionality and diagnosing brain disorders. Thanks to advancements in neuroimaging technology, a novel approach has emerged that involves modeling the human brain as a graph-structured pattern, with different brain regions represented as nodes and the functional relationships among these regions as edges. Moreover, graph neural networks (GNNs) have demonstrated a significant advantage in mining graph-structured data. Developing GNNs to learn brain graph representations for brain disorder analysis has recently gained increasing attention. However, there is a lack of systematic survey work summarizing current research methods in this domain. In this paper, we aim to bridge this gap by reviewing brain graph learning works that utilize GNNs. We first introduce the process of brain graph modeling based on common neuroimaging data. Subsequently, we systematically categorize current works based on the type of brain graph generated and the targeted research problems. To make this research accessible to a broader range of interested researchers, we provide an overview of representative methods and commonly used datasets, along with their implementation sources. Finally, we present our insights on future research directions. The repository of this survey is available at \url{https://github.com/XuexiongLuoMQ/Awesome-Brain-Graph-Learning-with-GNNs}.
Disentangled and Side-aware Unsupervised Domain Adaptation for Cross-dataset Subjective Tinnitus Diagnosis
May 03, 2022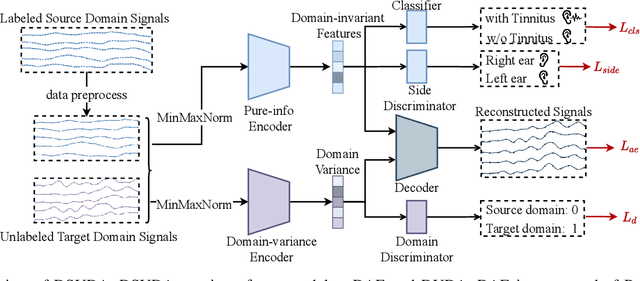
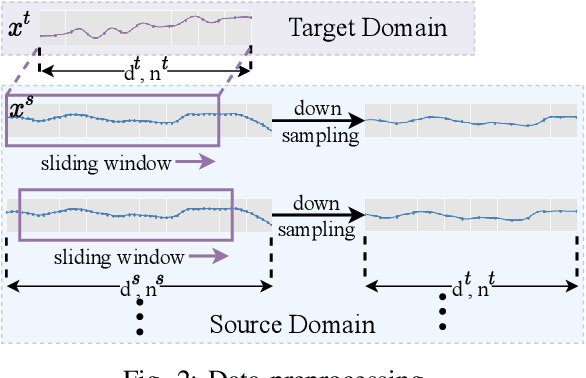
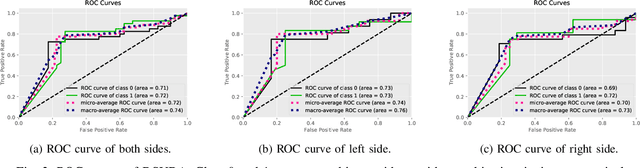
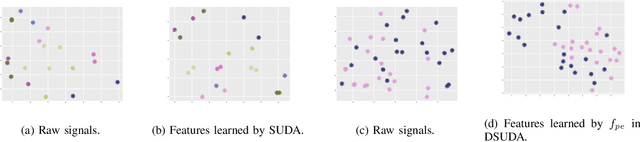
EEG-based tinnitus classification is a valuable tool for tinnitus diagnosis, research, and treatments. Most current works are limited to a single dataset where data patterns are similar. But EEG signals are highly non-stationary, resulting in model's poor generalization to new users, sessions or datasets. Thus, designing a model that can generalize to new datasets is beneficial and indispensable. To mitigate distribution discrepancy across datasets, we propose to achieve Disentangled and Side-aware Unsupervised Domain Adaptation (DSUDA) for cross-dataset tinnitus diagnosis. A disentangled auto-encoder is developed to decouple class-irrelevant information from the EEG signals to improve the classifying ability. The side-aware unsupervised domain adaptation module adapts the class-irrelevant information as domain variance to a new dataset and excludes the variance to obtain the class-distill features for the new dataset classification. It also align signals of left and right ears to overcome inherent EEG pattern difference. We compare DSUDA with state-of-the-art methods, and our model achieves significant improvements over competitors regarding comprehensive evaluation criteria. The results demonstrate our model can successfully generalize to a new dataset and effectively diagnose tinnitus.
Deep Reinforcement Learning Guided Graph Neural Networks for Brain Network Analysis
Mar 18, 2022
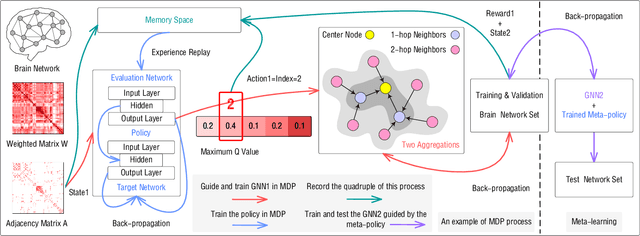

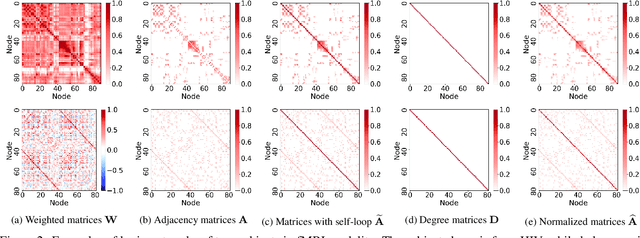
Modern neuroimaging techniques, such as diffusion tensor imaging (DTI) and functional magnetic resonance imaging (fMRI), enable us to model the human brain as a brain network or connectome. Capturing brain networks' structural information and hierarchical patterns is essential for understanding brain functions and disease states. Recently, the promising network representation learning capability of graph neural networks (GNNs) has prompted many GNN-based methods for brain network analysis to be proposed. Specifically, these methods apply feature aggregation and global pooling to convert brain network instances into meaningful low-dimensional representations used for downstream brain network analysis tasks. However, existing GNN-based methods often neglect that brain networks of different subjects may require various aggregation iterations and use GNN with a fixed number of layers to learn all brain networks. Therefore, how to fully release the potential of GNNs to promote brain network analysis is still non-trivial. To solve this problem, we propose a novel brain network representation framework, namely BN-GNN, which searches for the optimal GNN architecture for each brain network. Concretely, BN-GNN employs deep reinforcement learning (DRL) to train a meta-policy to automatically determine the optimal number of feature aggregations (reflected in the number of GNN layers) required for a given brain network. Extensive experiments on eight real-world brain network datasets demonstrate that our proposed BN-GNN improves the performance of traditional GNNs on different brain network analysis tasks.