 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslating Classical Poetry into Modern Prose
Jun 01, 2026We introduce Padyam2Gadyam, a dataset for the task of poem-to-prose translation from 13th-17th Century Telugu Classical Poetry to contemporary Telugu and English prose. The dataset consists of 600 poems and their human-verified Telugu and English prose translations. We evaluated 5 contemporary Large Language Models (LLMs) on their ability to do poem-to-prose translation into Telugu and English. Our results indicate that while there are differences across LLMs, their overall performance leave a large room for improvement in both languages. Through qualitative analysis, we discuss the the capabilities and limitations of contemporary MT evaluation approaches for this task.
Multi-Turn Multi-Agent Dialogue for Collaborative Reconstruction Improves VLM Performance on Spatial Reasoning, But Only Barely
May 29, 2026Robots operating in diverse environments rely on visual input to interpret objects and spatial layouts. In human-collaborative tasks, they are expected to communicate this understanding through language. Vision-language models (VLMs) support robotic tasks involving visual interpretation, question answering, and instruction following, but their capabilities in collaborative dialogue tasks requiring spatial reasoning remain underexplored. We study this gap through a collaborative structure-building task that combines visual interpretation, grounding, language-guided interaction, and action generation. We develop a framework in which VLMs use dialogue to reconstruct a target structure from visual and textual inputs. We evaluate open-weight and closed VLMs across interaction settings, input modalities, and image representations. Results show that spatial reasoning over visual representations remains difficult for the evaluated VLMs. Detailed text representations of the target yield higher reconstruction success across modality conditions, while decomposed image representations improve performance. These findings reveal limits in visual spatial grounding and grounded instruction generation for collaborative VLM agents.
CommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
Mind the Gap: Evaluating LLM Understanding of Human-Taught Road Safety Principles
Nov 17, 2025Following road safety norms is non-negotiable not only for humans but also for the AI systems that govern autonomous vehicles. In this work, we evaluate how well multi-modal large language models (LLMs) understand road safety concepts, specifically through schematic and illustrative representations. We curate a pilot dataset of images depicting traffic signs and road-safety norms sourced from school text books and use it to evaluate models capabilities in a zero-shot setting. Our preliminary results show that these models struggle with safety reasoning and reveal gaps between human learning and model interpretation. We further provide an analysis of these performance gaps for future research.
From Templates to Natural Language: Generalization Challenges in Instruction-Tuned LLMs for Spatial Reasoning
May 20, 2025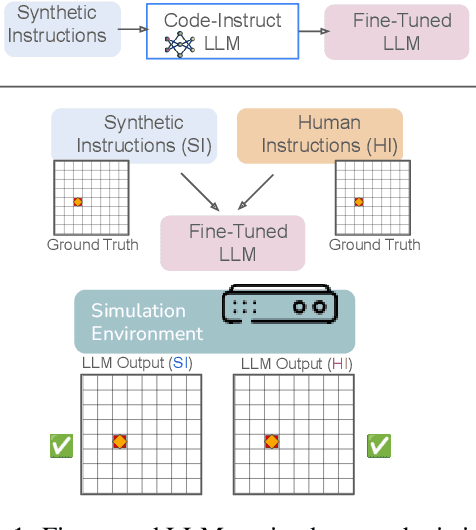
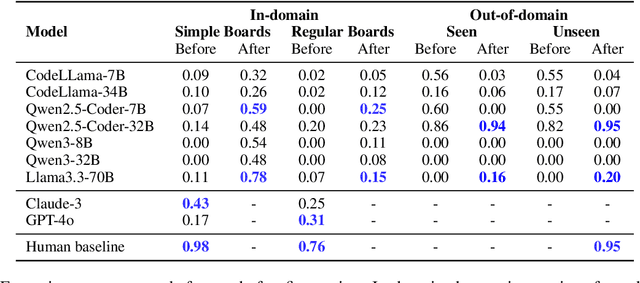


Instruction-tuned large language models (LLMs) have shown strong performance on a variety of tasks; however, generalizing from synthetic to human-authored instructions in grounded environments remains a challenge for them. In this work, we study generalization challenges in spatial grounding tasks where models interpret and translate instructions for building object arrangements on a $2.5$D grid. We fine-tune LLMs using only synthetic instructions and evaluate their performance on a benchmark dataset containing both synthetic and human-written instructions. Our results reveal that while models generalize well on simple tasks, their performance degrades significantly on more complex tasks. We present a detailed error analysis of the gaps in instruction generalization.
clem:todd: A Framework for the Systematic Benchmarking of LLM-Based Task-Oriented Dialogue System Realisations
May 08, 2025The emergence of instruction-tuned large language models (LLMs) has advanced the field of dialogue systems, enabling both realistic user simulations and robust multi-turn conversational agents. However, existing research often evaluates these components in isolation-either focusing on a single user simulator or a specific system design-limiting the generalisability of insights across architectures and configurations. In this work, we propose clem todd (chat-optimized LLMs for task-oriented dialogue systems development), a flexible framework for systematically evaluating dialogue systems under consistent conditions. clem todd enables detailed benchmarking across combinations of user simulators and dialogue systems, whether existing models from literature or newly developed ones. It supports plug-and-play integration and ensures uniform datasets, evaluation metrics, and computational constraints. We showcase clem todd's flexibility by re-evaluating existing task-oriented dialogue systems within this unified setup and integrating three newly proposed dialogue systems into the same evaluation pipeline. Our results provide actionable insights into how architecture, scale, and prompting strategies affect dialogue performance, offering practical guidance for building efficient and effective conversational AI systems.
Towards No-Code Programming of Cobots: Experiments with Code Synthesis by Large Code Models for Conversational Programming
Sep 18, 2024



While there has been a lot of research recently on robots in household environments, at the present time, most robots in existence can be found on shop floors, and most interactions between humans and robots happen there. ``Collaborative robots'' (cobots) designed to work alongside humans on assembly lines traditionally require expert programming, limiting ability to make changes, or manual guidance, limiting expressivity of the resulting programs. To address these limitations, we explore using Large Language Models (LLMs), and in particular, their abilities of doing in-context learning, for conversational code generation. As a first step, we define RATS, the ``Repetitive Assembly Task'', a 2D building task designed to lay the foundation for simulating industry assembly scenarios. In this task, a `programmer' instructs a cobot, using natural language, on how a certain assembly is to be built; that is, the programmer induces a program, through natural language. We create a dataset that pairs target structures with various example instructions (human-authored, template-based, and model-generated) and example code. With this, we systematically evaluate the capabilities of state-of-the-art LLMs for synthesising this kind of code, given in-context examples. Evaluating in a simulated environment, we find that LLMs are capable of generating accurate `first order code' (instruction sequences), but have problems producing `higher-order code' (abstractions such as functions, or use of loops).