 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Templates to Natural Language: Generalization Challenges in Instruction-Tuned LLMs for Spatial Reasoning
Paper and Code
May 20, 2025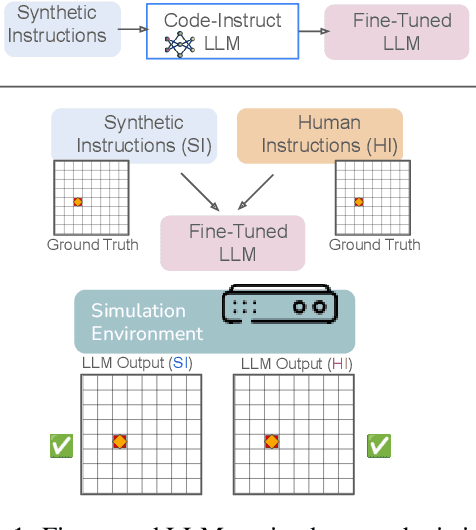
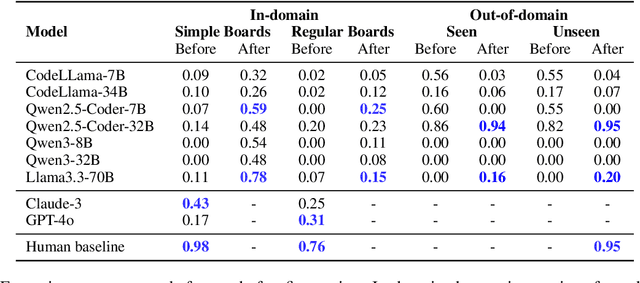


Instruction-tuned large language models (LLMs) have shown strong performance on a variety of tasks; however, generalizing from synthetic to human-authored instructions in grounded environments remains a challenge for them. In this work, we study generalization challenges in spatial grounding tasks where models interpret and translate instructions for building object arrangements on a $2.5$D grid. We fine-tune LLMs using only synthetic instructions and evaluate their performance on a benchmark dataset containing both synthetic and human-written instructions. Our results reveal that while models generalize well on simple tasks, their performance degrades significantly on more complex tasks. We present a detailed error analysis of the gaps in instruction generalization.