 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Determinantal Q-Learning
Jun 09, 2020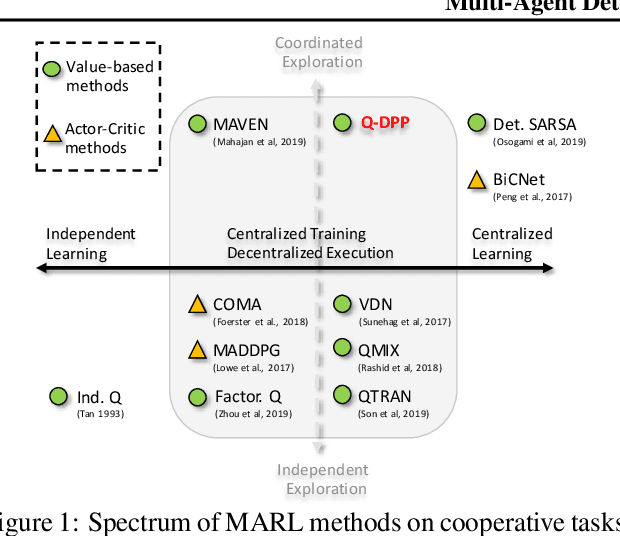
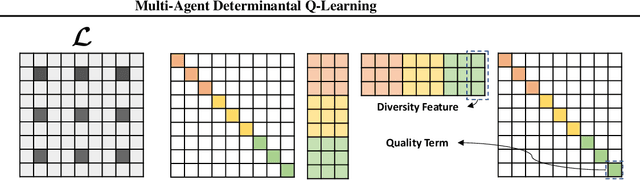
Centralized training with decentralized execution has become an important paradigm in multi-agent learning. Though practical, current methods rely on restrictive assumptions to decompose the centralized value function across agents for execution. In this paper, we eliminate this restriction by proposing multi-agent determinantal Q-learning. Our method is established on Q-DPP, an extension of determinantal point process (DPP) with partition-matroid constraint to multi-agent setting. Q-DPP promotes agents to acquire diverse behavioral models; this allows a natural factorization of the joint Q-functions with no need for \emph{a priori} structural constraints on the value function or special network architectures. We demonstrate that Q-DPP generalizes major solutions including VDN, QMIX, and QTRAN on decentralizable cooperative tasks. To efficiently draw samples from Q-DPP, we adopt an existing sample-by-projection sampler with theoretical approximation guarantee. The sampler also benefits exploration by coordinating agents to cover orthogonal directions in the state space during multi-agent training. We evaluate our algorithm on various cooperative benchmarks; its effectiveness has been demonstrated when compared with the state-of-the-art.