 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAUTE RL: Almost Surely Safe Reinforcement Learning Using State Augmentation
Paper and Code
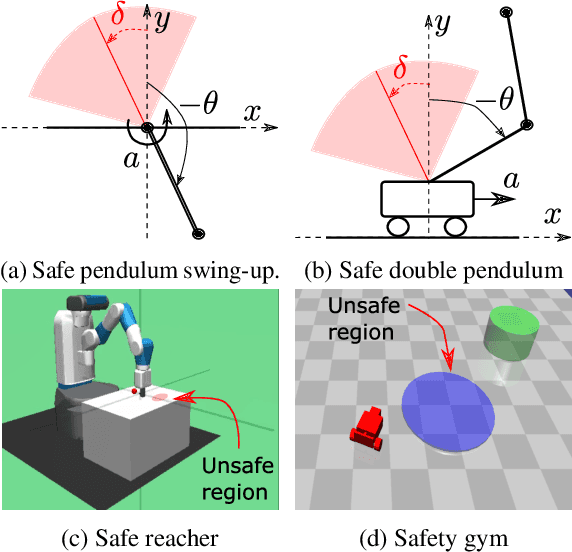
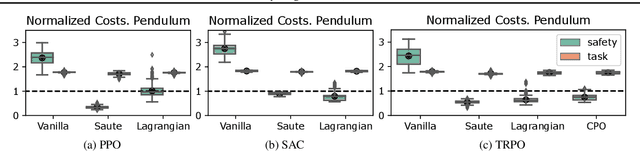
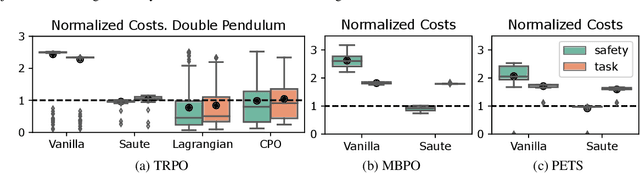
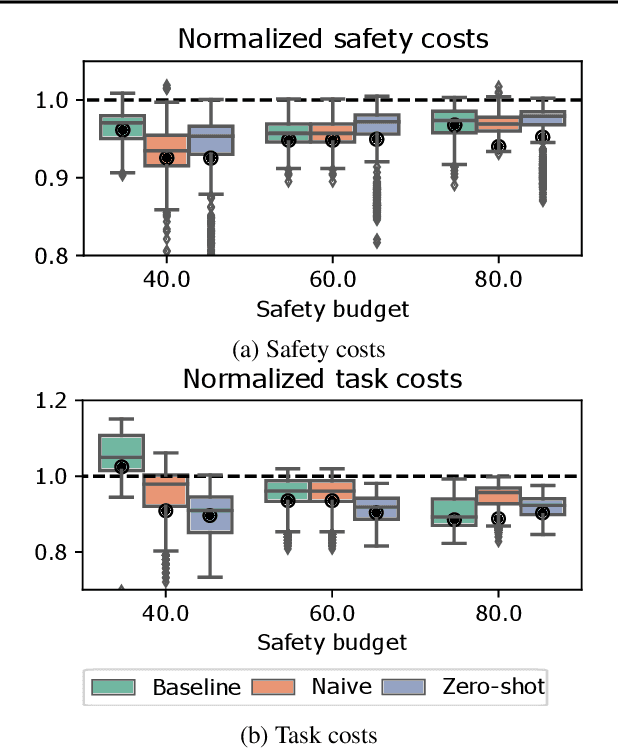
Satisfying safety constraints almost surely (or with probability one) can be critical for deployment of Reinforcement Learning (RL) in real-life applications. For example, plane landing and take-off should ideally occur with probability one. We address the problem by introducing Safety Augmented (Saute) Markov Decision Processes (MDPs), where the safety constraints are eliminated by augmenting them into the state-space and reshaping the objective. We show that Saute MDP satisfies the Bellman equation and moves us closer to solving Safe RL with constraints satisfied almost surely. We argue that Saute MDP allows to view Safe RL problem from a different perspective enabling new features. For instance, our approach has a plug-and-play nature, i.e., any RL algorithm can be "sauteed". Additionally, state augmentation allows for policy generalization across safety constraints. We finally show that Saute RL algorithms can outperform their state-of-the-art counterparts when constraint satisfaction is of high importance.