 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederatedFactory: Generative One-Shot Learning for Extremely Non-IID Distributed Scenarios
Mar 17, 2026Federated Learning (FL) enables distributed optimization without compromising data sovereignty. Yet, where local label distributions are mutually exclusive, standard weight aggregation fails due to conflicting optimization trajectories. Often, FL methods rely on pretrained foundation models, introducing unrealistic assumptions. We introduce FederatedFactory, a zero-dependency framework that inverts the unit of federation from discriminative parameters to generative priors. By exchanging generative modules in a single communication round, our architecture supports ex nihilo synthesis of universally class balanced datasets, eliminating gradient conflict and external prior bias entirely. Evaluations across diverse medical imagery benchmarks, including MedMNIST and ISIC2019, demonstrate that our approach recovers centralized upper-bound performance. Under pathological heterogeneity, it lifts baseline accuracy from a collapsed 11.36% to 90.57% on CIFAR-10 and restores ISIC2019 AUROC to 90.57%. Additionally, this framework facilitates exact modular unlearning through the deterministic deletion of specific generative modules.
The Observer Effect in World Models: Invasive Adaptation Corrupts Latent Physics
Feb 12, 2026Determining whether neural models internalize physical laws as world models, rather than exploiting statistical shortcuts, remains challenging, especially under out-of-distribution (OOD) shifts. Standard evaluations often test latent capability via downstream adaptation (e.g., fine-tuning or high-capacity probes), but such interventions can change the representations being measured and thus confound what was learned during self-supervised learning (SSL). We propose a non-invasive evaluation protocol, PhyIP. We test whether physical quantities are linearly decodable from frozen representations, motivated by the linear representation hypothesis. Across fluid dynamics and orbital mechanics, we find that when SSL achieves low error, latent structure becomes linearly accessible. PhyIP recovers internal energy and Newtonian inverse-square scaling on OOD tests (e.g., $ρ> 0.90$). In contrast, adaptation-based evaluations can collapse this structure ($ρ\approx 0.05$). These findings suggest that adaptation-based evaluation can obscure latent structures and that low-capacity probes offer a more accurate evaluation of physical world models.
Hybrid Many-Objective Optimization in Probabilistic Mission Design for Compliant and Effective UAV Routing
Dec 24, 2024Advanced Aerial Mobility encompasses many outstanding applications that promise to revolutionize modern logistics and pave the way for various public services and industry uses. However, throughout its history, the development of such systems has been impeded by the complexity of legal restrictions and physical constraints. While airspaces are often tightly shaped by various legal requirements, Unmanned Aerial Vehicles (UAV) must simultaneously consider, among others, energy demands, signal quality, and noise pollution. In this work, we address this challenge by presenting a novel architecture that integrates methods of Probabilistic Mission Design (ProMis) and Many-Objective Optimization for UAV routing. Hereby, our framework is able to comply with legal requirements under uncertainty while producing effective paths that minimize various physical costs a UAV needs to consider when traversing human-inhabited spaces. To this end, we combine hybrid probabilistic first-order logic for spatial reasoning with mixed deterministic-stochastic route optimization, incorporating physical objectives such as energy consumption and radio interference with a logical, probabilistic model of legal requirements. We demonstrate the versatility and advantages of our system in a large-scale empirical evaluation over real-world, crowd-sourced data from a map extract from the city of Paris, France, showing how a network of effective and compliant paths can be formed.
LLM as a code generator in Agile Model Driven Development
Oct 24, 2024



Leveraging Large Language Models (LLM) like GPT4 in the auto generation of code represents a significant advancement, yet it is not without its challenges. The ambiguity inherent in natural language descriptions of software poses substantial obstacles to generating deployable, structured artifacts. This research champions Model Driven Development (MDD) as a viable strategy to overcome these challenges, proposing an Agile Model Driven Development (AMDD) approach that employs GPT4 as a code generator. This approach enhances the flexibility and scalability of the code auto generation process and offers agility that allows seamless adaptation to changes in models or deployment environments. We illustrate this by modeling a multi agent Unmanned Vehicle Fleet (UVF) system using the Unified Modeling Language (UML), significantly reducing model ambiguity by integrating the Object Constraint Language (OCL) for code structure meta modeling, and the FIPA ontology language for communication semantics meta modeling. Applying GPT4 auto generation capabilities yields Java and Python code that is compatible with the JADE and PADE frameworks, respectively. Our thorough evaluation of the auto generated code verifies its alignment with expected behaviors and identifies enhancements in agent interactions. Structurally, we assessed the complexity of code derived from a model constrained solely by OCL meta models, against that influenced by both OCL and FIPA ontology meta models. The results indicate that the ontology constrained meta model produces inherently more complex code, yet its cyclomatic complexity remains within manageable levels, suggesting that additional meta model constraints can be incorporated without exceeding the high risk threshold for complexity.
Automated Federated Learning via Informed Pruning
May 16, 2024



Federated learning (FL) represents a pivotal shift in machine learning (ML) as it enables collaborative training of local ML models coordinated by a central aggregator, all without the need to exchange local data. However, its application on edge devices is hindered by limited computational capabilities and data communication challenges, compounded by the inherent complexity of Deep Learning (DL) models. Model pruning is identified as a key technique for compressing DL models on devices with limited resources. Nonetheless, conventional pruning techniques typically rely on manually crafted heuristics and demand human expertise to achieve a balance between model size, speed, and accuracy, often resulting in sub-optimal solutions. In this study, we introduce an automated federated learning approach utilizing informed pruning, called AutoFLIP, which dynamically prunes and compresses DL models within both the local clients and the global server. It leverages a federated loss exploration phase to investigate model gradient behavior across diverse datasets and losses, providing insights into parameter significance. Our experiments showcase notable enhancements in scenarios with strong non-IID data, underscoring AutoFLIP's capacity to tackle computational constraints and achieve superior global convergence.
Coding by Design: GPT-4 empowers Agile Model Driven Development
Oct 06, 2023Generating code from a natural language using Large Language Models (LLMs) such as ChatGPT, seems groundbreaking. Yet, with more extensive use, it's evident that this approach has its own limitations. The inherent ambiguity of natural language presents challenges for complex software designs. Accordingly, our research offers an Agile Model-Driven Development (MDD) approach that enhances code auto-generation using OpenAI's GPT-4. Our work emphasizes "Agility" as a significant contribution to the current MDD method, particularly when the model undergoes changes or needs deployment in a different programming language. Thus, we present a case-study showcasing a multi-agent simulation system of an Unmanned Vehicle Fleet. In the first and second layer of our approach, we constructed a textual representation of the case-study using Unified Model Language (UML) diagrams. In the next layer, we introduced two sets of constraints that minimize model ambiguity. Object Constraints Language (OCL) is applied to fine-tune the code constructions details, while FIPA ontology is used to shape communication semantics and protocols. Ultimately, leveraging GPT-4, our last layer auto-generates code in both Java and Python. The Java code is deployed within the JADE framework, while the Python code is deployed in PADE framework. Concluding our research, we engaged in a comprehensive evaluation of the generated code. From a behavioural standpoint, the auto-generated code aligned perfectly with the expected UML sequence diagram. Structurally, we compared the complexity of code derived from UML diagrams constrained solely by OCL to that influenced by both OCL and FIPA-ontology. Results indicate that ontology-constrained model produce inherently more intricate code, but it remains manageable and low-risk for further testing and maintenance.
Alleviating Search Bias in Bayesian Evolutionary Optimization with Many Heterogeneous Objectives
Aug 25, 2022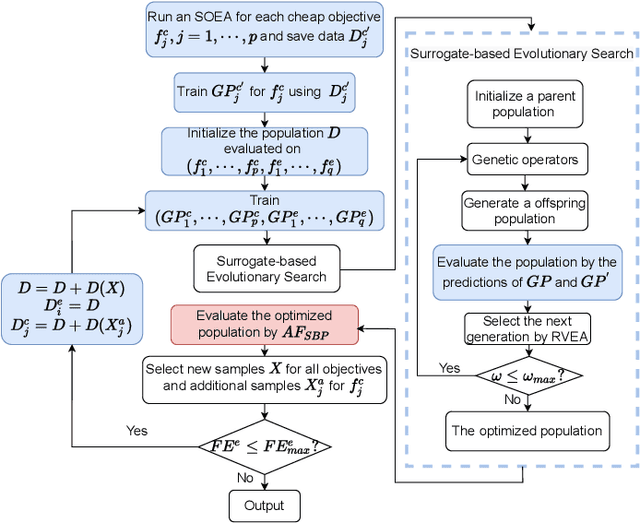
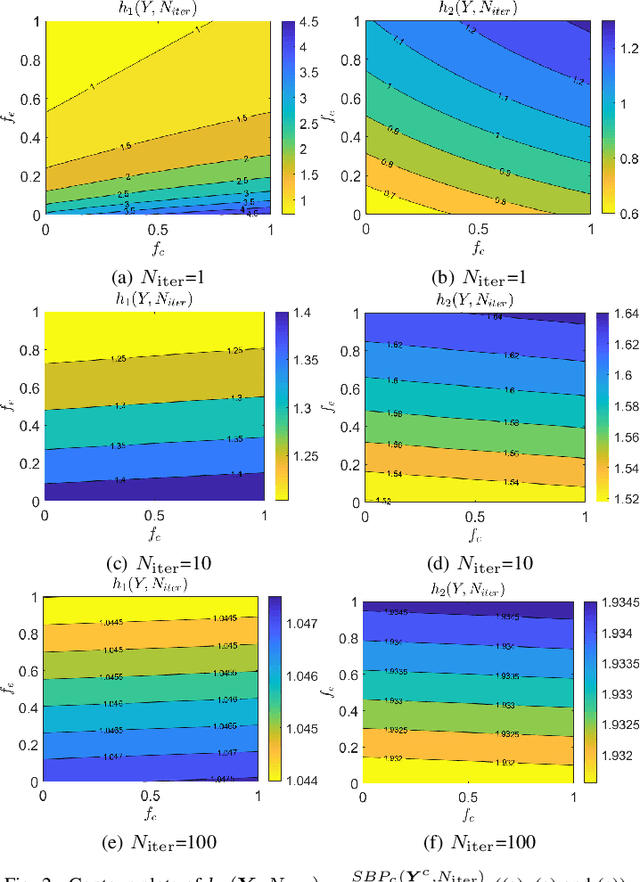
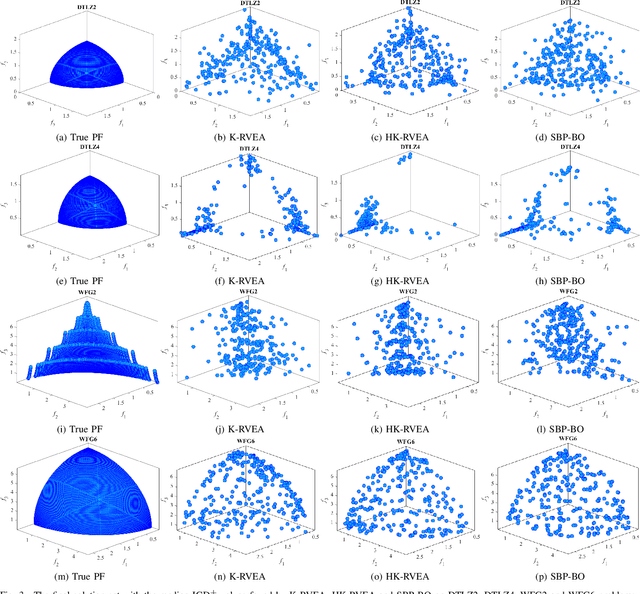
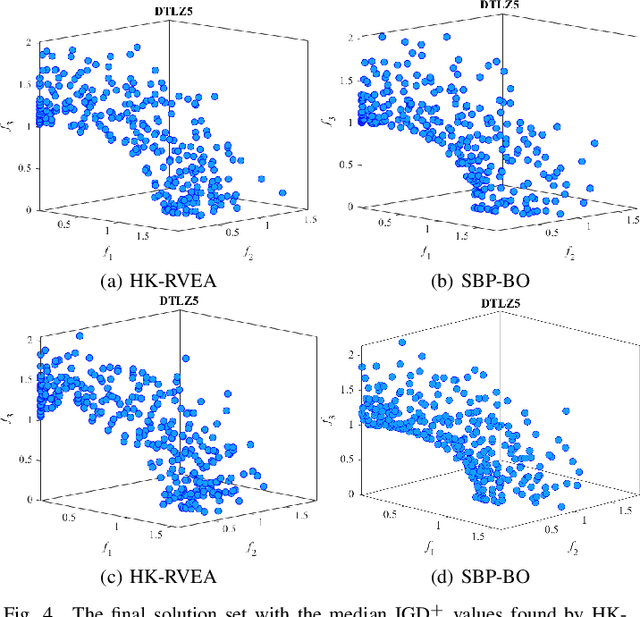
Multi-objective optimization problems whose objectives have different evaluation costs are commonly seen in the real world. Such problems are now known as multi-objective optimization problems with heterogeneous objectives (HE-MOPs). So far, however, only a few studies have been reported to address HE-MOPs, and most of them focus on bi-objective problems with one fast objective and one slow objective. In this work, we aim to deal with HE-MOPs having more than two black-box and heterogeneous objectives. To this end, we develop a multi-objective Bayesian evolutionary optimization approach to HE-MOPs by exploiting the different data sets on the cheap and expensive objectives in HE-MOPs to alleviate the search bias caused by the heterogeneous evaluation costs for evaluating different objectives. To make the best use of two different training data sets, one with solutions evaluated on all objectives and the other with those only evaluated on the fast objectives, two separate Gaussian process models are constructed. In addition, a new acquisition function that mitigates search bias towards the fast objectives is suggested, thereby achieving a balance between convergence and diversity. We demonstrate the effectiveness of the proposed algorithm by testing it on widely used multi-/many-objective benchmark problems whose objectives are assumed to be heterogeneously expensive.
Recent Advances in Bayesian Optimization
Jun 07, 2022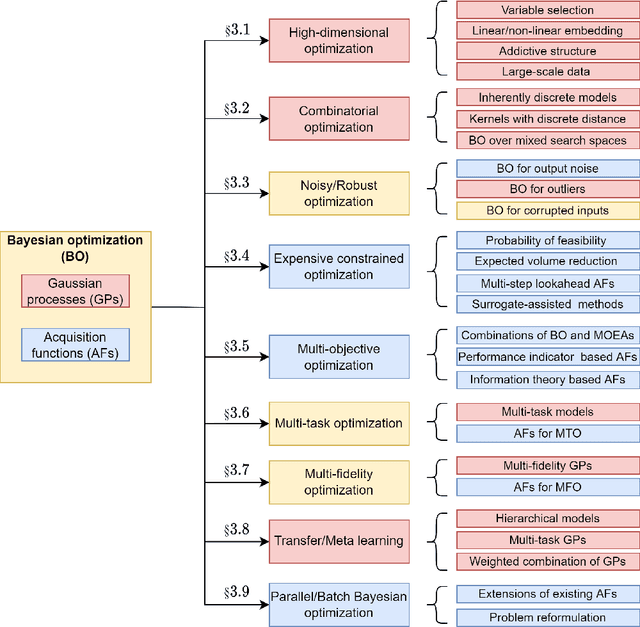
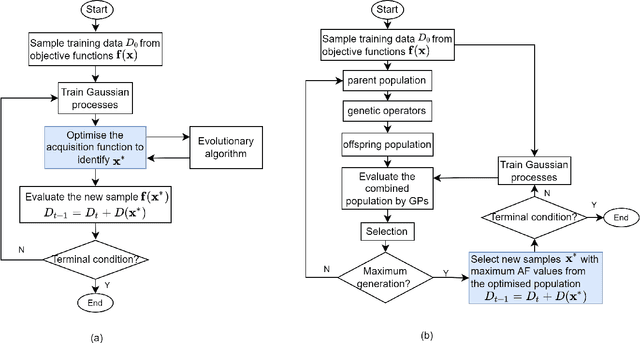
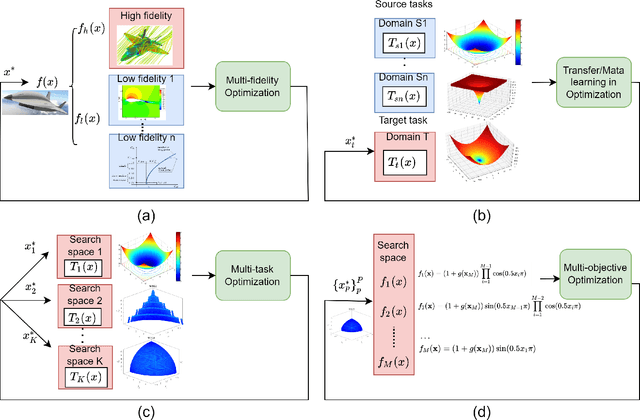
Bayesian optimization has emerged at the forefront of expensive black-box optimization due to its data efficiency. Recent years have witnessed a proliferation of studies on the development of new Bayesian optimization algorithms and their applications. Hence, this paper attempts to provide a comprehensive and updated survey of recent advances in Bayesian optimization and identify interesting open problems. We categorize the existing work on Bayesian optimization into nine main groups according to the motivations and focus of the proposed algorithms. For each category, we present the main advances with respect to the construction of surrogate models and adaptation of the acquisition functions. Finally, we discuss the open questions and suggest promising future research directions, in particular with regard to heterogeneity, privacy preservation, and fairness in distributed and federated optimization systems.
Transfer Learning Based Co-surrogate Assisted Evolutionary Bi-objective Optimization for Objectives with Non-uniform Evaluation Times
Aug 30, 2021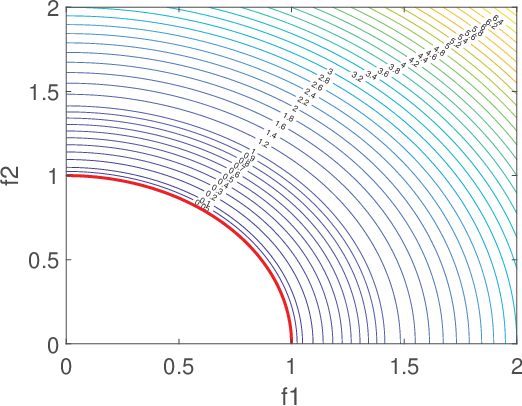
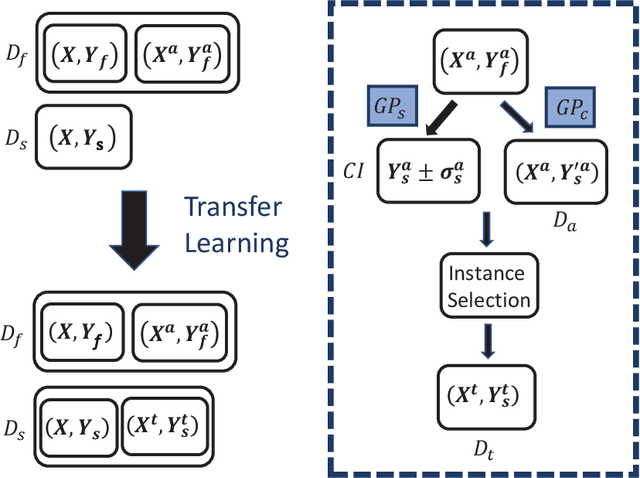
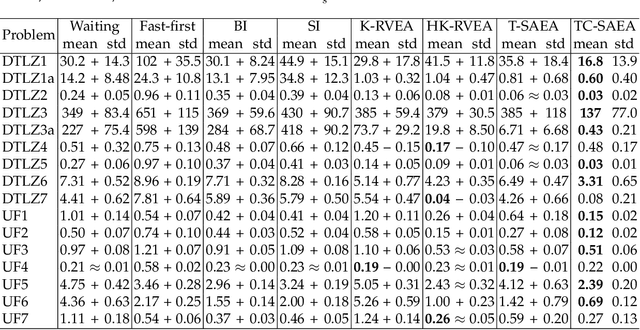
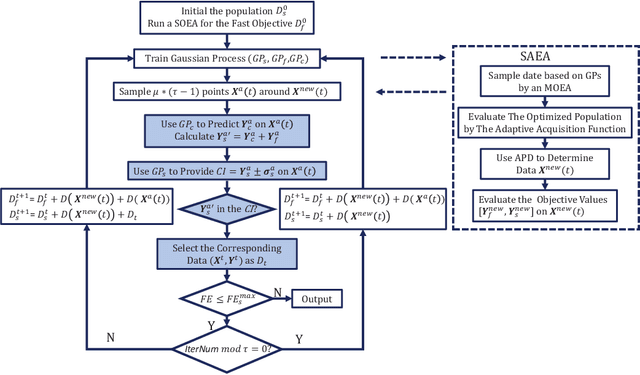
Most existing multiobjetive evolutionary algorithms (MOEAs) implicitly assume that each objective function can be evaluated within the same period of time. Typically. this is untenable in many real-world optimization scenarios where evaluation of different objectives involves different computer simulations or physical experiments with distinct time complexity. To address this issue, a transfer learning scheme based on surrogate-assisted evolutionary algorithms (SAEAs) is proposed, in which a co-surrogate is adopted to model the functional relationship between the fast and slow objective functions and a transferable instance selection method is introduced to acquire useful knowledge from the search process of the fast objective. Our experimental results on DTLZ and UF test suites demonstrate that the proposed algorithm is competitive for solving bi-objective optimization where objectives have non-uniform evaluation times.
Automatic Preference Based Multi-objective Evolutionary Algorithm on Vehicle Fleet Maintenance Scheduling Optimization
Jan 23, 2021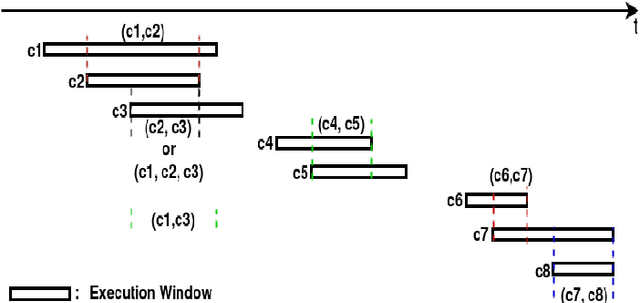
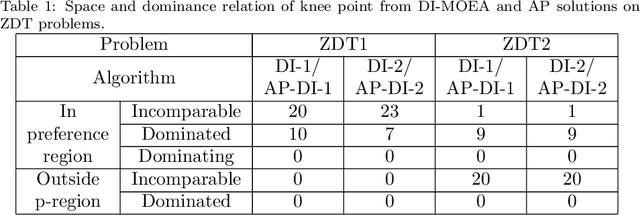
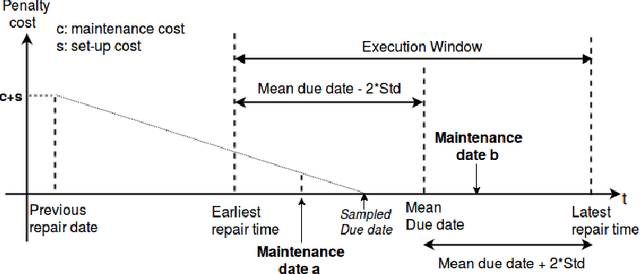
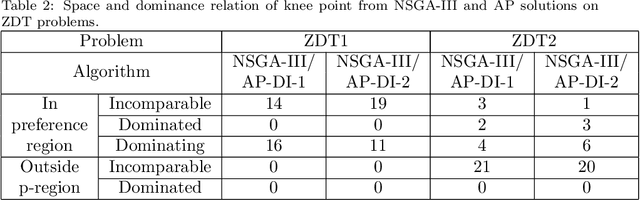
A preference based multi-objective evolutionary algorithm is proposed for generating solutions in an automatically detected knee point region. It is named Automatic Preference based DI-MOEA (AP-DI-MOEA) where DI-MOEA stands for Diversity-Indicator based Multi-Objective Evolutionary Algorithm). AP-DI-MOEA has two main characteristics: firstly, it generates the preference region automatically during the optimization; secondly, it concentrates the solution set in this preference region. Moreover, the real-world vehicle fleet maintenance scheduling optimization (VFMSO) problem is formulated, and a customized multi-objective evolutionary algorithm (MOEA) is proposed to optimize maintenance schedules of vehicle fleets based on the predicted failure distribution of the components of cars. Furthermore, the customized MOEA for VFMSO is combined with AP-DI-MOEA to find maintenance schedules in the automatically generated preference region. Experimental results on multi-objective benchmark problems and our three-objective real-world application problems show that the newly proposed algorithm can generate the preference region accurately and that it can obtain better solutions in the preference region. Especially, in many cases, under the same budget, the Pareto optimal solutions obtained by AP-DI-MOEA dominate solutions obtained by MOEAs that pursue the entire Pareto front.