 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Accurate and Realistic Virtual Try-on Through Shape Matching and Multiple Warps
Mar 27, 2020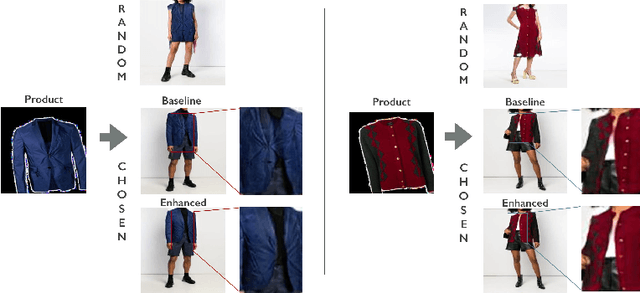
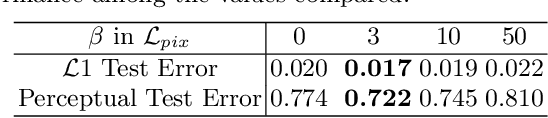
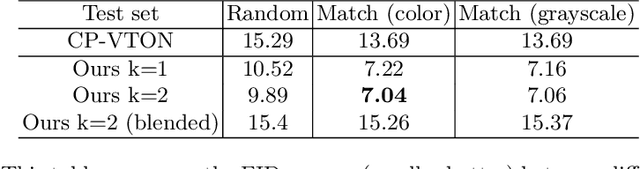
A virtual try-on method takes a product image and an image of a model and produces an image of the model wearing the product. Most methods essentially compute warps from the product image to the model image and combine using image generation methods. However, obtaining a realistic image is challenging because the kinematics of garments is complex and because outline, texture, and shading cues in the image reveal errors to human viewers. The garment must have appropriate drapes; texture must be warped to be consistent with the shape of a draped garment; small details (buttons, collars, lapels, pockets, etc.) must be placed appropriately on the garment, and so on. Evaluation is particularly difficult and is usually qualitative. This paper uses quantitative evaluation on a challenging, novel dataset to demonstrate that (a) for any warping method, one can choose target models automatically to improve results, and (b) learning multiple coordinated specialized warpers offers further improvements on results. Target models are chosen by a learned embedding procedure that predicts a representation of the products the model is wearing. This prediction is used to match products to models. Specialized warpers are trained by a method that encourages a second warper to perform well in locations where the first works poorly. The warps are then combined using a U-Net. Qualitative evaluation confirms that these improvements are wholesale over outline, texture shading, and garment details.
Exposing and Correcting the Gender Bias in Image Captioning Datasets and Models
Dec 02, 2019


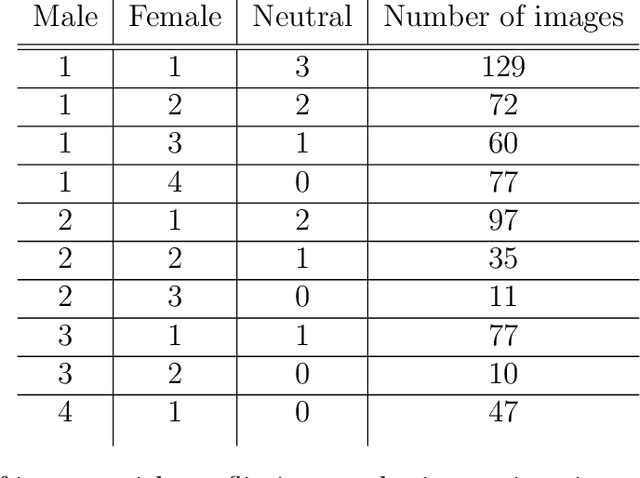
The task of image captioning implicitly involves gender identification. However, due to the gender bias in data, gender identification by an image captioning model suffers. Also, the gender-activity bias, owing to the word-by-word prediction, influences other words in the caption prediction, resulting in the well-known problem of label bias. In this work, we investigate gender bias in the COCO captioning dataset and show that it engenders not only from the statistical distribution of genders with contexts but also from the flawed annotation by the human annotators. We look at the issues created by this bias in the trained models. We propose a technique to get rid of the bias by splitting the task into 2 subtasks: gender-neutral image captioning and gender classification. By this decoupling, the gender-context influence can be eradicated. We train the gender-neutral image captioning model, which gives comparable results to a gendered model even when evaluating against a dataset that possesses a similar bias as the training data. Interestingly, the predictions by this model on images with no humans, are also visibly different from the one trained on gendered captions. We train gender classifiers using the available bounding box and mask-based annotations for the person in the image. This allows us to get rid of the context and focus on the person to predict the gender. By substituting the genders into the gender-neutral captions, we get the final gendered predictions. Our predictions achieve similar performance to a model trained with gender, and at the same time are devoid of gender bias. Finally, our main result is that on an anti-stereotypical dataset, our model outperforms a popular image captioning model which is trained with gender.
Effectively Unbiased FID and Inception Score and where to find them
Nov 16, 2019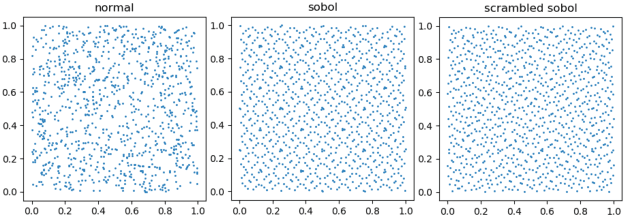

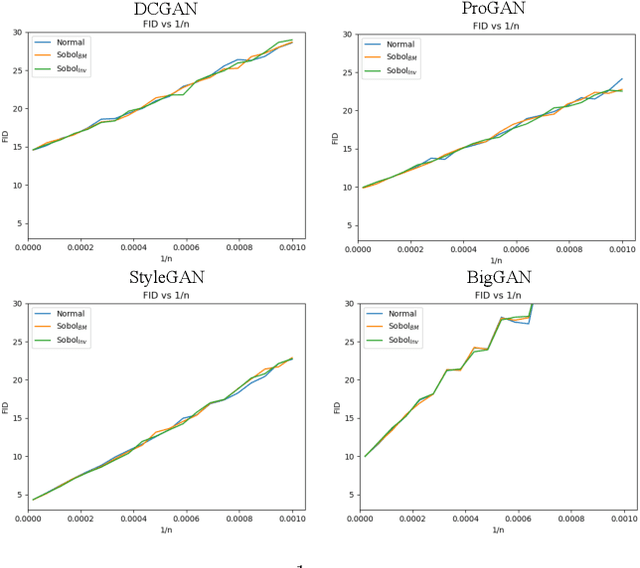
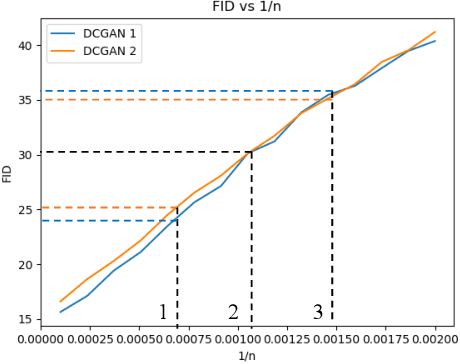
This paper shows that two commonly used evaluation metrics for generative models, the Fr\'echet Inception Distance (FID) and the Inception Score (IS), are biased -- the expected value of the score computed for a finite sample set is not the true value of the score. Worse, the paper shows that the bias term depends on the particular model being evaluated, so model A may get a better score than model B simply because model A's bias term is smaller. This effect cannot be fixed by evaluating at a fixed number of samples. This means all comparisons using FID or IS as currently computed are unreliable. We then show how to extrapolate the score to obtain an effectively bias-free estimate of scores computed with an infinite number of samples, which we term $\overline{\textrm{FID}}_\infty$ and $\overline{\textrm{IS}}_\infty$. In turn, this effectively bias-free estimate requires good estimates of scores with a finite number of samples. We show that using Quasi-Monte Carlo integration notably improves estimates of FID and IS for finite sample sets. Our extrapolated scores are simple, drop-in replacements for the finite sample scores. Additionally, we show that using low discrepancy sequence in GAN training offers small improvements in the resulting generator.
Improving Style Transfer with Calibrated Metrics
Oct 21, 2019
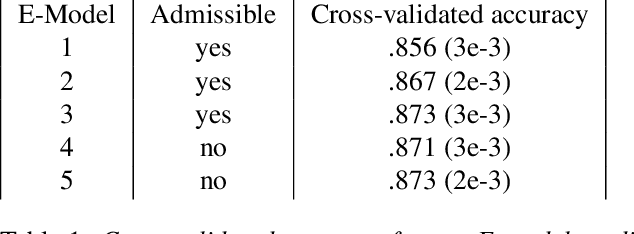


Style transfer methods produce a transferred image which is a rendering of a content image in the manner of a style image. We seek to understand how to improve style transfer. To do so requires quantitative evaluation procedures, but the current evaluation is qualitative, mostly involving user studies. We describe a novel quantitative evaluation procedure. Our procedure relies on two statistics: the Effectiveness (E) statistic measures the extent that a given style has been transferred to the target, and the Coherence (C) statistic measures the extent to which the original image's content is preserved. Our statistics are calibrated to human preference: targets with larger values of E (resp C) will reliably be preferred by human subjects in comparisons of style (resp. content). We use these statistics to investigate the relative performance of a number of Neural Style Transfer(NST) methods, revealing several intriguing properties. Admissible methods lie on a Pareto frontier (i.e. improving E reduces C or vice versa). Three methods are admissible: Universal style transfer produces very good C but weak E; modifying the optimization used for Gatys' loss produces a method with strong E and strong C; and a modified cross-layer method has slightly better E at strong cost in C. While the histogram loss improves the E statistics of Gatys' method, it does not make the method admissible. Surprisingly, style weights have relatively little effect in improving EC scores, and most variability in the transfer is explained by the style itself (meaning experimenters can be misguided by selecting styles).
Counterfactual Depth from a Single RGB Image
Sep 03, 2019

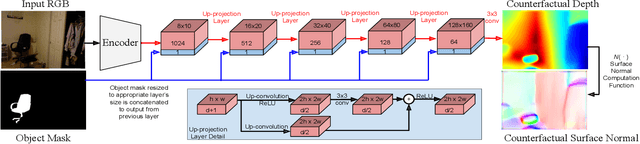
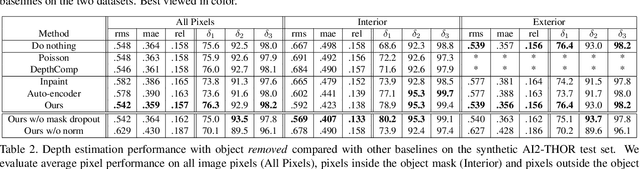
We describe a method that predicts, from a single RGB image, a depth map that describes the scene when a masked object is removed - we call this "counterfactual depth" that models hidden scene geometry together with the observations. Our method works for the same reason that scene completion works: the spatial structure of objects is simple. But we offer a much higher resolution representation of space than current scene completion methods, as we operate at pixel-level precision and do not rely on a voxel representation. Furthermore, we do not require RGBD inputs. Our method uses a standard encoder-decoder architecture, and with a decoder modified to accept an object mask. We describe a small evaluation dataset that we have collected, which allows inference about what factors affect reconstruction most strongly. Using this dataset, we show that our depth predictions for masked objects are better than other baselines.
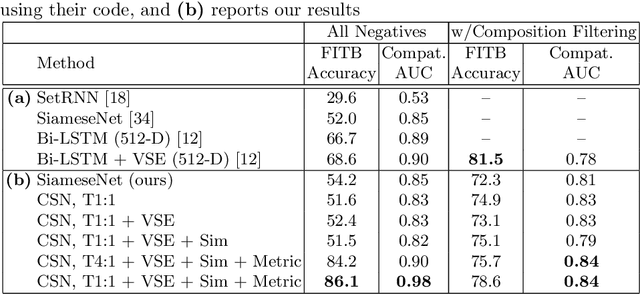
Using Discriminative Methods to Learn Fashion Compatibility Across Datasets
Jun 17, 2019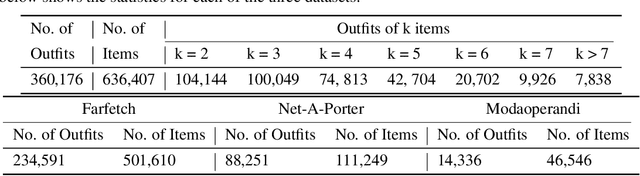
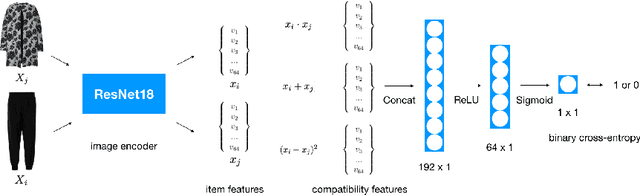
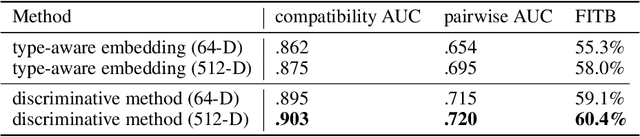

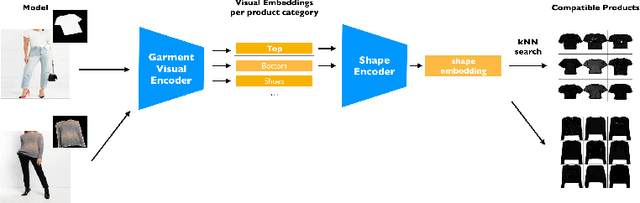
Determining whether a pair of garments are compatible with each other is a challenging matching problem. Past works explored various embedding methods for learning such a relationship. This paper introduces using discriminative methods to learn compatibility, by formulating the task as a simple binary classification problem. We evaluate our approach using an established dataset of outfits created by non-experts and demonstrated an improvement of ~2.5% on established metrics over the state-of-the-art method. We introduce three new datasets of professionally curated outfits and show the consistent performance of our approach on expert-curated datasets. To facilitate comparing across outfit datasets, we propose a new metric which, unlike previously used metrics, is not biased by the average size of outfits. We also demonstrate that compatibility between two types of items can be query indirectly, and such query strategy yield improvements.
Why do These Match? Explaining the Behavior of Image Similarity Models
May 26, 2019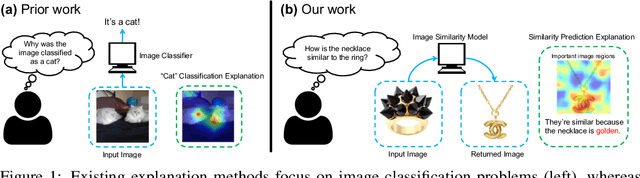
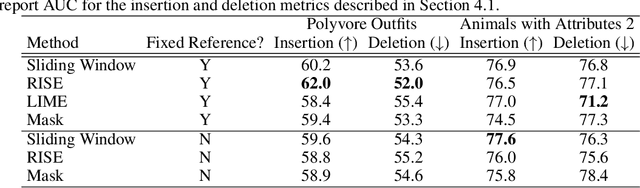
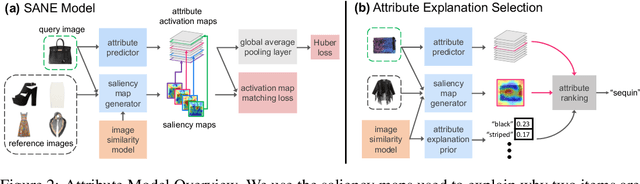
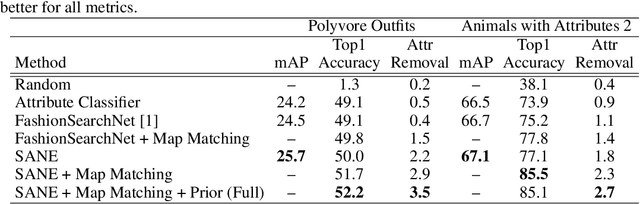
Explaining a deep learning model can help users understand its behavior and allow researchers to discern its shortcomings. Recent work has primarily focused on explaining models for tasks like image classification or visual question answering. In this paper, we introduce an explanation approach for image similarity models, where a model's output is a semantic feature representation rather than a classification. In this task, an explanation depends on both of the input images, so standard methods do not apply. We propose an explanation method that pairs a saliency map identifying important image regions with an attribute that best explains the match. We find that our explanations are more human-interpretable than saliency maps alone, and can also improve performance on the classic task of attribute recognition. The ability of our approach to generalize is demonstrated on two datasets from very different domains, Polyvore Outfits and Animals with Attributes 2.
Max-Sliced Wasserstein Distance and its use for GANs
Apr 11, 2019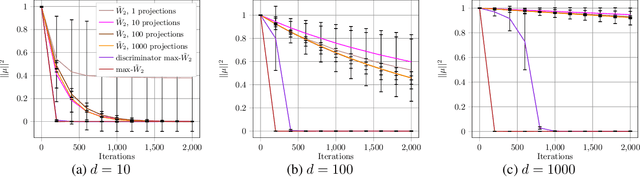

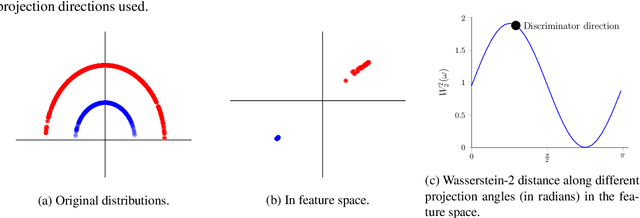

Generative adversarial nets (GANs) and variational auto-encoders have significantly improved our distribution modeling capabilities, showing promise for dataset augmentation, image-to-image translation and feature learning. However, to model high-dimensional distributions, sequential training and stacked architectures are common, increasing the number of tunable hyper-parameters as well as the training time. Nonetheless, the sample complexity of the distance metrics remains one of the factors affecting GAN training. We first show that the recently proposed sliced Wasserstein distance has compelling sample complexity properties when compared to the Wasserstein distance. To further improve the sliced Wasserstein distance we then analyze its `projection complexity' and develop the max-sliced Wasserstein distance which enjoys compelling sample complexity while reducing projection complexity, albeit necessitating a max estimation. We finally illustrate that the proposed distance trains GANs on high-dimensional images up to a resolution of 256x256 easily.
Structural Consistency and Controllability for Diverse Colorization
Sep 06, 2018
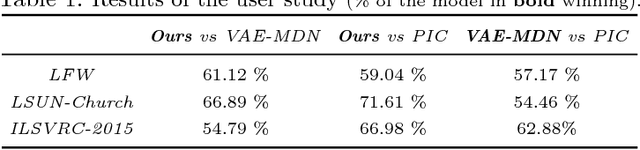

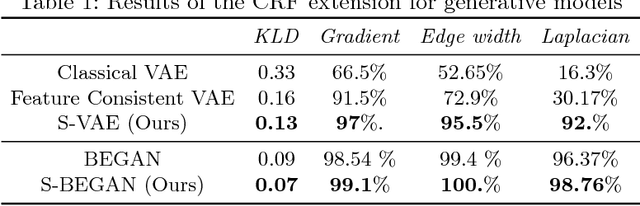
Colorizing a given gray-level image is an important task in the media and advertising industry. Due to the ambiguity inherent to colorization (many shades are often plausible), recent approaches started to explicitly model diversity. However, one of the most obvious artifacts, structural inconsistency, is rarely considered by existing methods which predict chrominance independently for every pixel. To address this issue, we develop a conditional random field based variational auto-encoder formulation which is able to achieve diversity while taking into account structural consistency. Moreover, we introduce a controllability mecha- nism that can incorporate external constraints from diverse sources in- cluding a user interface. Compared to existing baselines, we demonstrate that our method obtains more diverse and globally consistent coloriza- tions on the LFW, LSUN-Church and ILSVRC-2015 datasets.
Learning Type-Aware Embeddings for Fashion Compatibility
Jul 27, 2018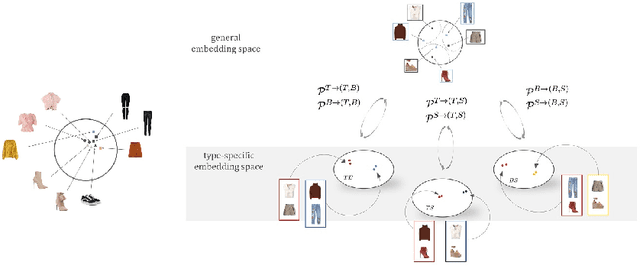


Outfits in online fashion data are composed of items of many different types (e.g. top, bottom, shoes) that share some stylistic relationship with one another. A representation for building outfits requires a method that can learn both notions of similarity (for example, when two tops are interchangeable) and compatibility (items of possibly different type that can go together in an outfit). This paper presents an approach to learning an image embedding that respects item type, and jointly learns notions of item similarity and compatibility in an end-to-end model. To evaluate the learned representation, we crawled 68,306 outfits created by users on the Polyvore website. Our approach obtains 3-5% improvement over the state-of-the-art on outfit compatibility prediction and fill-in-the-blank tasks using our dataset, as well as an established smaller dataset, while supporting a variety of useful queries.