 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Artificial Intelligence with Human Expertise: An In-depth Analysis of ChatGPT's Capabilities in Generating Metamorphic Relations
Mar 28, 2025Context: This paper provides an in-depth examination of the generation and evaluation of Metamorphic Relations (MRs) using GPT models developed by OpenAI, with a particular focus on the capabilities of GPT-4 in software testing environments. Objective: The aim is to examine the quality of MRs produced by GPT-3.5 and GPT-4 for a specific System Under Test (SUT) adopted from an earlier study, and to introduce and apply an improved set of evaluation criteria for a diverse range of SUTs. Method: The initial phase evaluates MRs generated by GPT-3.5 and GPT-4 using criteria from a prior study, followed by an application of an enhanced evaluation framework on MRs created by GPT-4 for a diverse range of nine SUTs, varying from simple programs to complex systems incorporating AI/ML components. A custom-built GPT evaluator, alongside human evaluators, assessed the MRs, enabling a direct comparison between automated and human evaluation methods. Results: The study finds that GPT-4 outperforms GPT-3.5 in generating accurate and useful MRs. With the advanced evaluation criteria, GPT-4 demonstrates a significant ability to produce high-quality MRs across a wide range of SUTs, including complex systems incorporating AI/ML components. Conclusions: GPT-4 exhibits advanced capabilities in generating MRs suitable for various applications. The research underscores the growing potential of AI in software testing, particularly in the generation and evaluation of MRs, and points towards the complementarity of human and AI skills in this domain.
Can ChatGPT advance software testing intelligence? An experience report on metamorphic testing
Oct 30, 2023While ChatGPT is a well-known artificial intelligence chatbot being used to answer human's questions, one may want to discover its potential in advancing software testing. We examine the capability of ChatGPT in advancing the intelligence of software testing through a case study on metamorphic testing (MT), a state-of-the-art software testing technique. We ask ChatGPT to generate candidates of metamorphic relations (MRs), which are basically necessary properties of the object program and which traditionally require human intelligence to identify. These MR candidates are then evaluated in terms of correctness by domain experts. We show that ChatGPT can be used to generate new correct MRs to test several software systems. Having said that, the majority of MR candidates are either defined vaguely or incorrect, especially for systems that have never been tested with MT. ChatGPT can be used to advance software testing intelligence by proposing MR candidates that can be later adopted for implementing tests; but human intelligence should still inevitably be involved to justify and rectify their correctness.
Precise Learning of Source Code Contextual Semantics via Hierarchical Dependence Structure and Graph Attention Networks
Nov 20, 2021
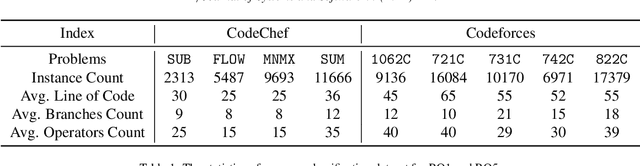
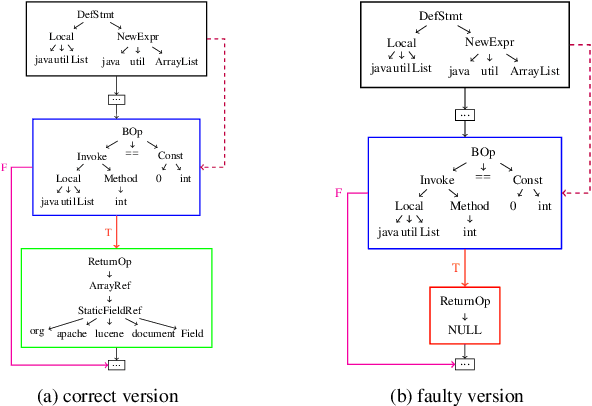
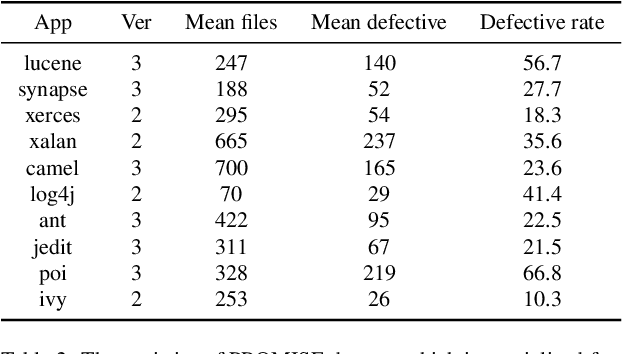
Deep learning is being used extensively in a variety of software engineering tasks, e.g., program classification and defect prediction. Although the technique eliminates the required process of feature engineering, the construction of source code model significantly affects the performance on those tasks. Most recent works was mainly focused on complementing AST-based source code models by introducing contextual dependencies extracted from CFG. However, all of them pay little attention to the representation of basic blocks, which are the basis of contextual dependencies. In this paper, we integrated AST and CFG and proposed a novel source code model embedded with hierarchical dependencies. Based on that, we also designed a neural network that depends on the graph attention mechanism.Specifically, we introduced the syntactic structural of the basic block, i.e., its corresponding AST, in source code model to provide sufficient information and fill the gap. We have evaluated this model on three practical software engineering tasks and compared it with other state-of-the-art methods. The results show that our model can significantly improve the performance. For example, compared to the best performing baseline, our model reduces the scale of parameters by 50\% and achieves 4\% improvement on accuracy on program classification task.
* 17pages, published on Journal of Systems and Software