 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Robustness of Discrete Prompts
Feb 11, 2023



Discrete prompts have been used for fine-tuning Pre-trained Language Models for diverse NLP tasks. In particular, automatic methods that generate discrete prompts from a small set of training instances have reported superior performance. However, a closer look at the learnt prompts reveals that they contain noisy and counter-intuitive lexical constructs that would not be encountered in manually-written prompts. This raises an important yet understudied question regarding the robustness of automatically learnt discrete prompts when used in downstream tasks. To address this question, we conduct a systematic study of the robustness of discrete prompts by applying carefully designed perturbations into an application using AutoPrompt and then measure their performance in two Natural Language Inference (NLI) datasets. Our experimental results show that although the discrete prompt-based method remains relatively robust against perturbations to NLI inputs, they are highly sensitive to other types of perturbations such as shuffling and deletion of prompt tokens. Moreover, they generalize poorly across different NLI datasets. We hope our findings will inspire future work on robust discrete prompt learning.
Comparing Intrinsic Gender Bias Evaluation Measures without using Human Annotated Examples
Jan 28, 2023Numerous types of social biases have been identified in pre-trained language models (PLMs), and various intrinsic bias evaluation measures have been proposed for quantifying those social biases. Prior works have relied on human annotated examples to compare existing intrinsic bias evaluation measures. However, this approach is not easily adaptable to different languages nor amenable to large scale evaluations due to the costs and difficulties when recruiting human annotators. To overcome this limitation, we propose a method to compare intrinsic gender bias evaluation measures without relying on human-annotated examples. Specifically, we create multiple bias-controlled versions of PLMs using varying amounts of male vs. female gendered sentences, mined automatically from an unannotated corpus using gender-related word lists. Next, each bias-controlled PLM is evaluated using an intrinsic bias evaluation measure, and the rank correlation between the computed bias scores and the gender proportions used to fine-tune the PLMs is computed. Experiments on multiple corpora and PLMs repeatedly show that the correlations reported by our proposed method that does not require human annotated examples are comparable to those computed using human annotated examples in prior work.
Vis2Hap: Vision-based Haptic Rendering by Cross-modal Generation
Jan 17, 2023



To assist robots in teleoperation tasks, haptic rendering which allows human operators access a virtual touch feeling has been developed in recent years. Most previous haptic rendering methods strongly rely on data collected by tactile sensors. However, tactile data is not widely available for robots due to their limited reachable space and the restrictions of tactile sensors. To eliminate the need for tactile data, in this paper we propose a novel method named as Vis2Hap to generate haptic rendering from visual inputs that can be obtained from a distance without physical interaction. We take the surface texture of objects as key cues to be conveyed to the human operator. To this end, a generative model is designed to simulate the roughness and slipperiness of the object's surface. To embed haptic cues in Vis2Hap, we use height maps from tactile sensors and spectrograms from friction coefficients as the intermediate outputs of the generative model. Once Vis2Hap is trained, it can be used to generate height maps and spectrograms of new surface textures, from which a friction image can be obtained and displayed on a haptic display. The user study demonstrates that our proposed Vis2Hap method enables users to access a realistic haptic feeling similar to that of physical objects. The proposed vision-based haptic rendering has the potential to enhance human operators' perception of the remote environment and facilitate robotic manipulation.
On the Curious Case of $\ell_2$ norm of Sense Embeddings
Oct 26, 2022We show that the $\ell_2$ norm of a static sense embedding encodes information related to the frequency of that sense in the training corpus used to learn the sense embeddings. This finding can be seen as an extension of a previously known relationship for word embeddings to sense embeddings. Our experimental results show that, in spite of its simplicity, the $\ell_2$ norm of sense embeddings is a surprisingly effective feature for several word sense related tasks such as (a) most frequent sense prediction, (b) Word-in-Context (WiC), and (c) Word Sense Disambiguation (WSD). In particular, by simply including the $\ell_2$ norm of a sense embedding as a feature in a classifier, we show that we can improve WiC and WSD methods that use static sense embeddings.
Debiasing isn't enough! -- On the Effectiveness of Debiasing MLMs and their Social Biases in Downstream Tasks
Oct 06, 2022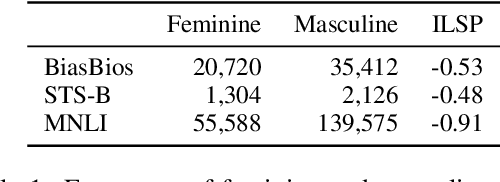
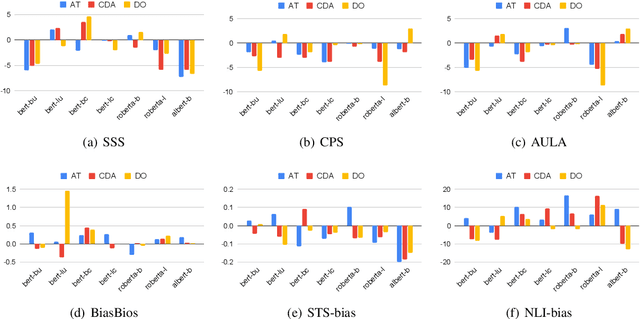
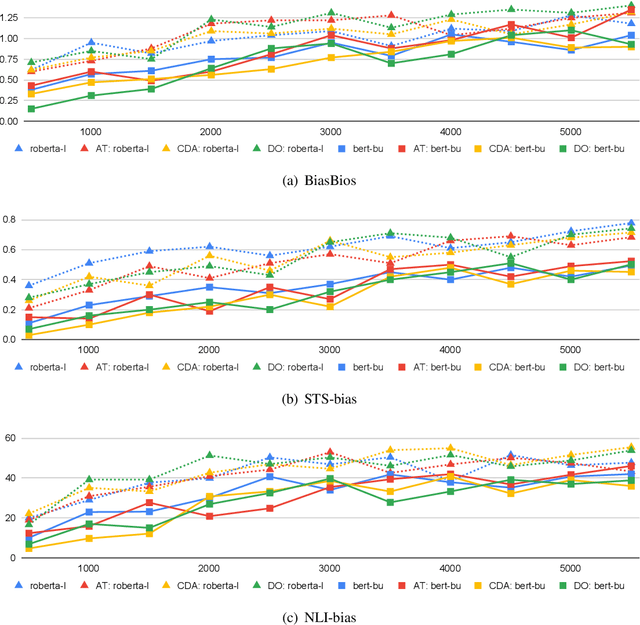
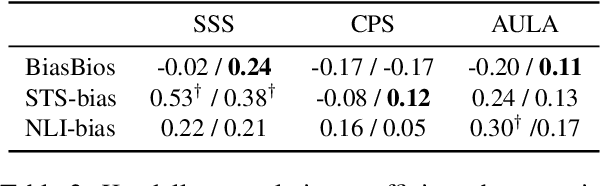
We study the relationship between task-agnostic intrinsic and task-specific extrinsic social bias evaluation measures for Masked Language Models (MLMs), and find that there exists only a weak correlation between these two types of evaluation measures. Moreover, we find that MLMs debiased using different methods still re-learn social biases during fine-tuning on downstream tasks. We identify the social biases in both training instances as well as their assigned labels as reasons for the discrepancy between intrinsic and extrinsic bias evaluation measurements. Overall, our findings highlight the limitations of existing MLM bias evaluation measures and raise concerns on the deployment of MLMs in downstream applications using those measures.
Learning Dynamic Contextualised Word Embeddings via Template-based Temporal Adaptation
Aug 23, 2022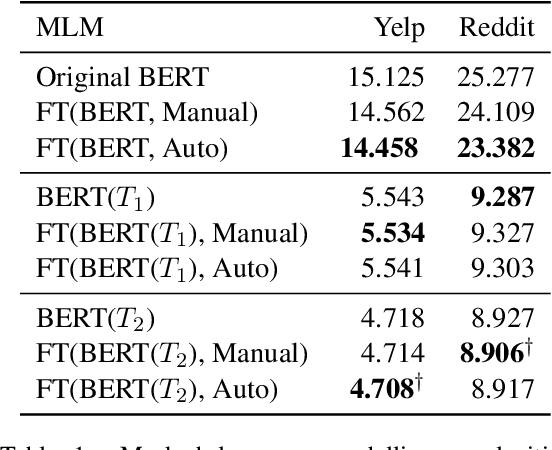

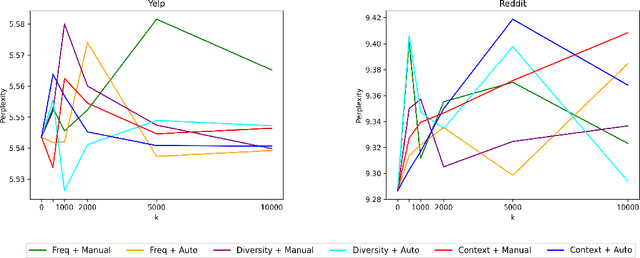
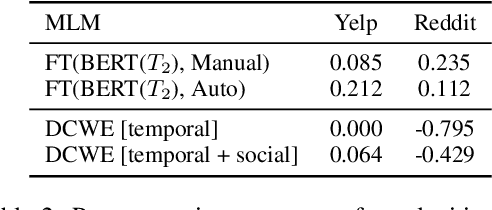
Dynamic contextualised word embeddings represent the temporal semantic variations of words. We propose a method for learning dynamic contextualised word embeddings by time-adapting a pretrained Masked Language Model (MLM) using time-sensitive templates. Given two snapshots $C_1$ and $C_2$ of a corpora taken respectively at two distinct timestamps $T_1$ and $T_2$, we first propose an unsupervised method to select (a) pivot terms related to both $C_1$ and $C_2$, and (b) anchor terms that are associated with a specific pivot term in each individual snapshot. We then generate prompts by filling manually compiled templates using the extracted pivot and anchor terms. Moreover, we propose an automatic method to learn time-sensitive templates from $C_1$ and $C_2$, without requiring any human supervision. Next, we use the generated prompts to adapt a pretrained MLM to $T_2$ by fine-tuning it on the prompts. Experimental results show that our proposed method significantly reduces the perplexity of test sentences selected from $T_2$, thereby outperforming the current state-of-the-art dynamic contextualised word embedding methods.
Random projections and Kernelised Leave One Cluster Out Cross-Validation: Universal baselines and evaluation tools for supervised machine learning for materials properties
Jun 17, 2022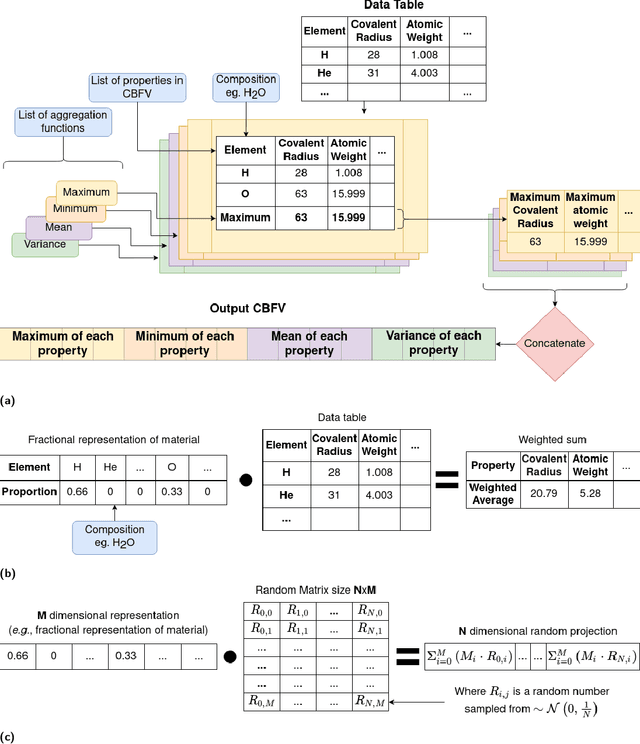
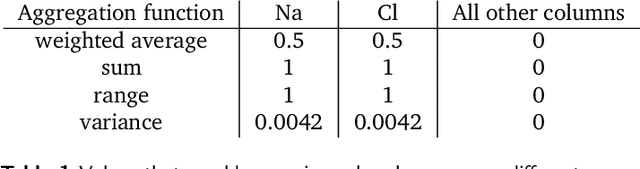
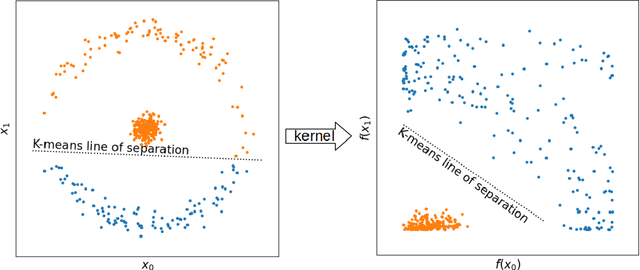
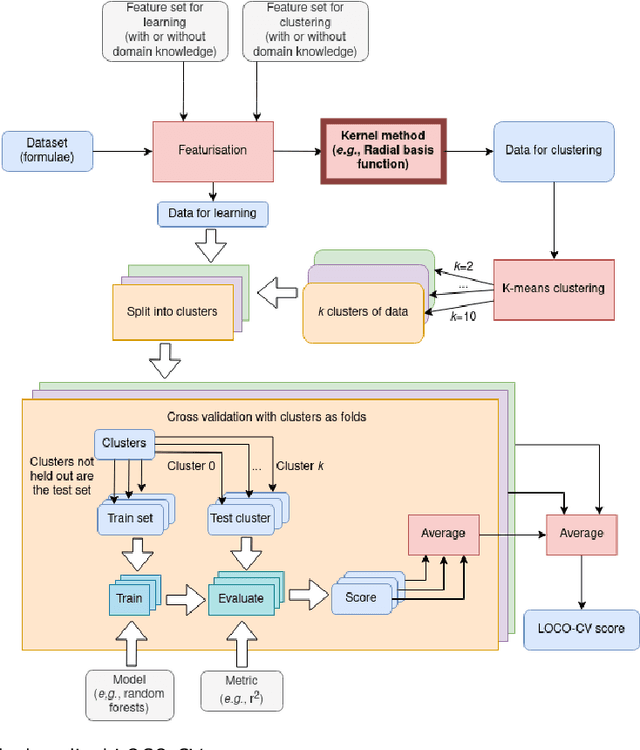
With machine learning being a popular topic in current computational materials science literature, creating representations for compounds has become common place. These representations are rarely compared, as evaluating their performance - and the performance of the algorithms that they are used with - is non-trivial. With many materials datasets containing bias and skew caused by the research process, leave one cluster out cross validation (LOCO-CV) has been introduced as a way of measuring the performance of an algorithm in predicting previously unseen groups of materials. This raises the question of the impact, and control, of the range of cluster sizes on the LOCO-CV measurement outcomes. We present a thorough comparison between composition-based representations, and investigate how kernel approximation functions can be used to better separate data to enhance LOCO-CV applications. We find that domain knowledge does not improve machine learning performance in most tasks tested, with band gap prediction being the notable exception. We also find that the radial basis function improves the linear separability of chemical datasets in all 10 datasets tested and provide a framework for the application of this function in the LOCO-CV process to improve the outcome of LOCO-CV measurements regardless of machine learning algorithm, choice of metric, and choice of compound representation. We recommend kernelised LOCO-CV as a training paradigm for those looking to measure the extrapolatory power of an algorithm on materials data.
Gender Bias in Meta-Embeddings
May 19, 2022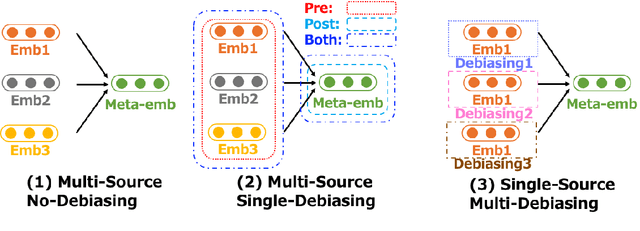
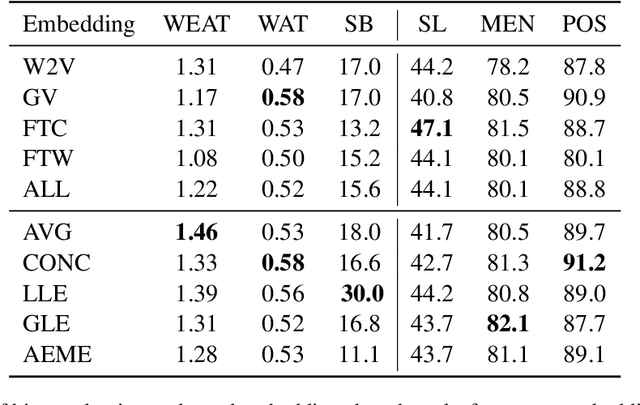
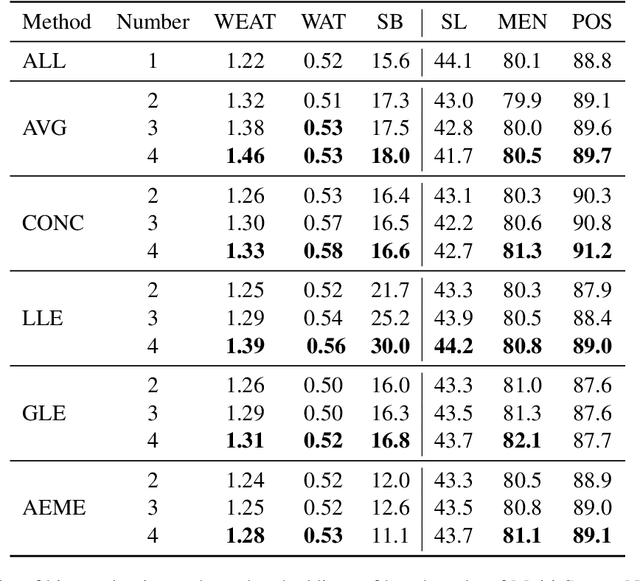
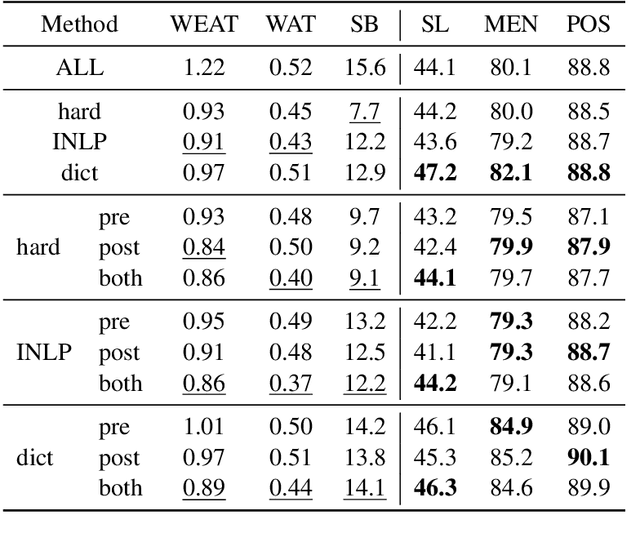
Combining multiple source embeddings to create meta-embeddings is considered effective to obtain more accurate embeddings. Different methods have been proposed to develop meta-embeddings from a given set of source embeddings. However, the source embeddings can contain unfair gender bias, and the bias in the combination of multiple embeddings and debiasing it effectively have not been studied yet. In this paper, we investigate the bias in three types of meta-embeddings: (1) Multi-Source No-Debiasing: meta-embedding from multiple source embeddings without any debiasing. The experimental results show that meta-embedding amplifies the gender bias compared to those of input source embeddings; (2) Multi-Source Single-Debiasing: meta-embedding from multiple source embeddings debiased by a single method and it can be created in three ways: debiasing each source embedding, debiasing the learned meta-embeddings, and debiasing both source embeddings and meta-embeddings. The results show that debiasing both is the best in two out of three bias evaluation benchmarks; (3) Single-Source Multi-Debiasing: meta-embedding from the same source embedding debiased by different methods. It performed more effectively than its source embeddings debiased with a single method in all three bias evaluation benchmarks.
Gender Bias in Masked Language Models for Multiple Languages
May 04, 2022
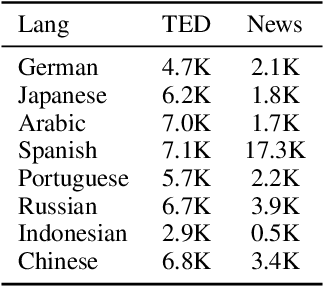
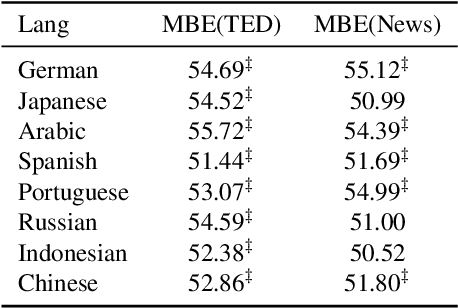
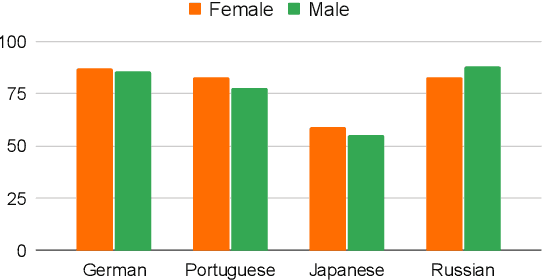
Masked Language Models (MLMs) pre-trained by predicting masked tokens on large corpora have been used successfully in natural language processing tasks for a variety of languages. Unfortunately, it was reported that MLMs also learn discriminative biases regarding attributes such as gender and race. Because most studies have focused on MLMs in English, the bias of MLMs in other languages has rarely been investigated. Manual annotation of evaluation data for languages other than English has been challenging due to the cost and difficulty in recruiting annotators. Moreover, the existing bias evaluation methods require the stereotypical sentence pairs consisting of the same context with attribute words (e.g. He/She is a nurse). We propose Multilingual Bias Evaluation (MBE) score, to evaluate bias in various languages using only English attribute word lists and parallel corpora between the target language and English without requiring manually annotated data. We evaluated MLMs in eight languages using the MBE and confirmed that gender-related biases are encoded in MLMs for all those languages. We manually created datasets for gender bias in Japanese and Russian to evaluate the validity of the MBE. The results show that the bias scores reported by the MBE significantly correlates with that computed from the above manually created datasets and the existing English datasets for gender bias.
Learning to Borrow -- Relation Representation for Without-Mention Entity-Pairs for Knowledge Graph Completion
Apr 28, 2022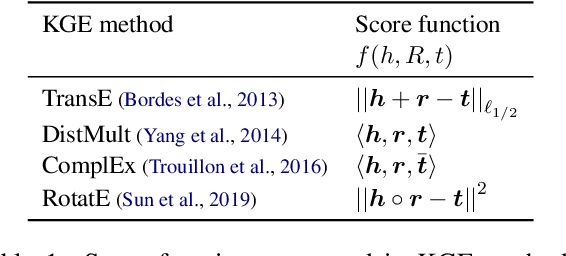
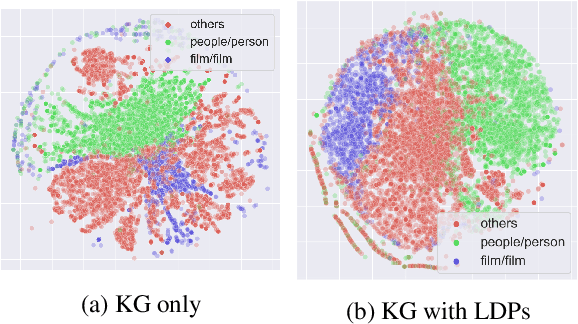
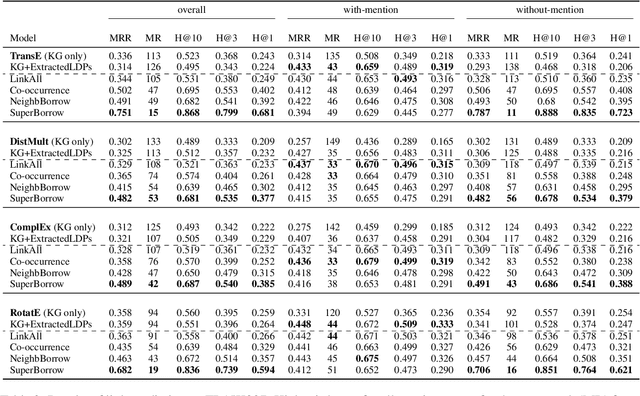
Prior work on integrating text corpora with knowledge graphs (KGs) to improve Knowledge Graph Embedding (KGE) have obtained good performance for entities that co-occur in sentences in text corpora. Such sentences (textual mentions of entity-pairs) are represented as Lexicalised Dependency Paths (LDPs) between two entities. However, it is not possible to represent relations between entities that do not co-occur in a single sentence using LDPs. In this paper, we propose and evaluate several methods to address this problem, where we borrow LDPs from the entity pairs that co-occur in sentences in the corpus (i.e. with mention entity pairs) to represent entity pairs that do not co-occur in any sentence in the corpus (i.e. without mention entity pairs). We propose a supervised borrowing method, SuperBorrow, that learns to score the suitability of an LDP to represent a without-mention entity pair using pre-trained entity embeddings and contextualised LDP representations. Experimental results show that SuperBorrow improves the link prediction performance of multiple widely-used prior KGE methods such as TransE, DistMult, ComplEx and RotatE.