 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-Statistics for Importance-Weighted Variational Inference
Feb 27, 2023



We propose the use of U-statistics to reduce variance for gradient estimation in importance-weighted variational inference. The key observation is that, given a base gradient estimator that requires $m > 1$ samples and a total of $n > m$ samples to be used for estimation, lower variance is achieved by averaging the base estimator on overlapping batches of size $m$ than disjoint batches, as currently done. We use classical U-statistic theory to analyze the variance reduction, and propose novel approximations with theoretical guarantees to ensure computational efficiency. We find empirically that U-statistic variance reduction can lead to modest to significant improvements in inference performance on a range of models, with little computational cost.
Automatically Marginalized MCMC in Probabilistic Programming
Feb 01, 2023



Hamiltonian Monte Carlo (HMC) is a powerful algorithm to sample latent variables from Bayesian models. The advent of probabilistic programming languages (PPLs) frees users from writing inference algorithms and lets users focus on modeling. However, many models are difficult for HMC to solve directly, which often require tricks like model reparameterization. We are motivated by the fact that many of those models could be simplified by marginalization. We propose to use automatic marginalization as part of the sampling process using HMC in a graphical model extracted from a PPL, which substantially improves sampling from real-world hierarchical models.
Variational Marginal Particle Filters
Sep 30, 2021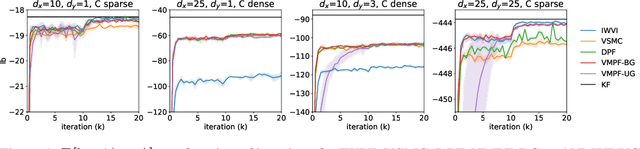
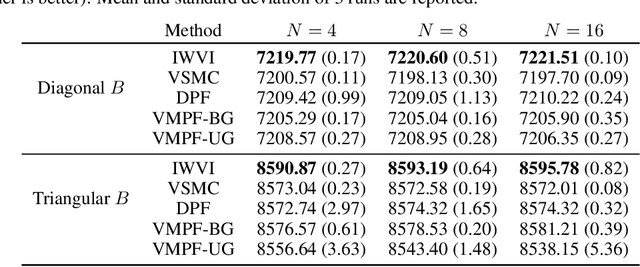
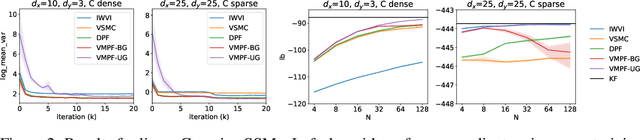
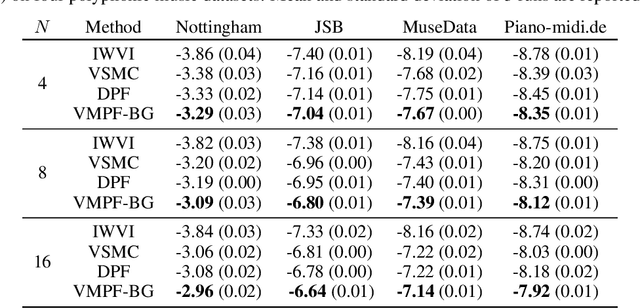
Variational inference for state space models (SSMs) is known to be hard in general. Recent works focus on deriving variational objectives for SSMs from unbiased sequential Monte Carlo estimators. We reveal that the marginal particle filter is obtained from sequential Monte Carlo by applying Rao-Blackwellization operations, which sacrifices the trajectory information for reduced variance and differentiability. We propose the variational marginal particle filter (VMPF), which is a differentiable and reparameterizable variational filtering objective for SSMs based on an unbiased estimator. We find that VMPF with biased gradients gives tighter bounds than previous objectives, and the unbiased reparameterization gradients are sometimes beneficial.
Relaxed Marginal Consistency for Differentially Private Query Answering
Sep 13, 2021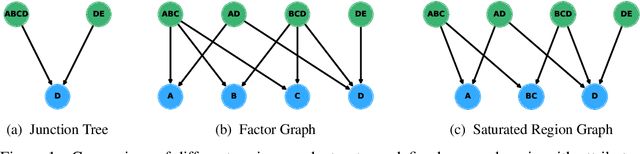
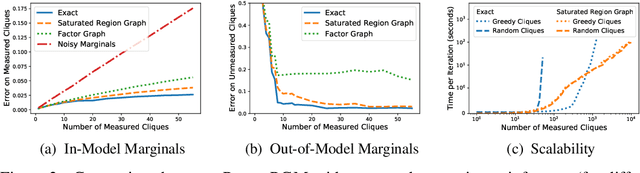
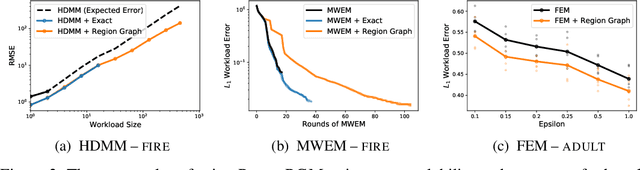
Many differentially private algorithms for answering database queries involve a step that reconstructs a discrete data distribution from noisy measurements. This provides consistent query answers and reduces error, but often requires space that grows exponentially with dimension. Private-PGM is a recent approach that uses graphical models to represent the data distribution, with complexity proportional to that of exact marginal inference in a graphical model with structure determined by the co-occurrence of variables in the noisy measurements. Private-PGM is highly scalable for sparse measurements, but may fail to run in high dimensions with dense measurements. We overcome the main scalability limitation of Private-PGM through a principled approach that relaxes consistency constraints in the estimation objective. Our new approach works with many existing private query answering algorithms and improves scalability or accuracy with no privacy cost.
Sibling Regression for Generalized Linear Models
Jul 07, 2021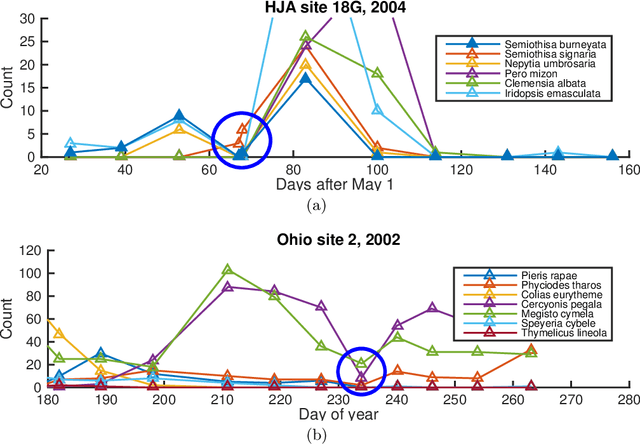
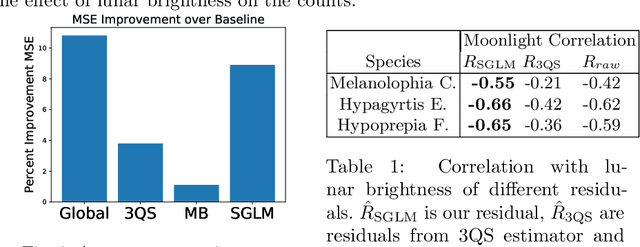
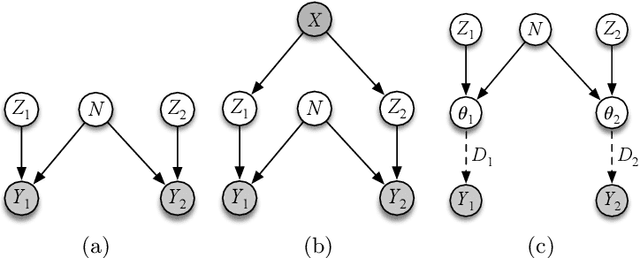
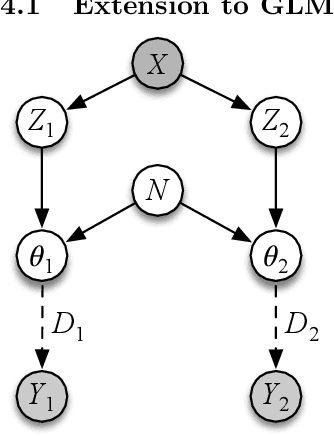
Field observations form the basis of many scientific studies, especially in ecological and social sciences. Despite efforts to conduct such surveys in a standardized way, observations can be prone to systematic measurement errors. The removal of systematic variability introduced by the observation process, if possible, can greatly increase the value of this data. Existing non-parametric techniques for correcting such errors assume linear additive noise models. This leads to biased estimates when applied to generalized linear models (GLM). We present an approach based on residual functions to address this limitation. We then demonstrate its effectiveness on synthetic data and show it reduces systematic detection variability in moth surveys.
The Spatio-Temporal Poisson Point Process: A Simple Model for the Alignment of Event Camera Data
Jun 13, 2021
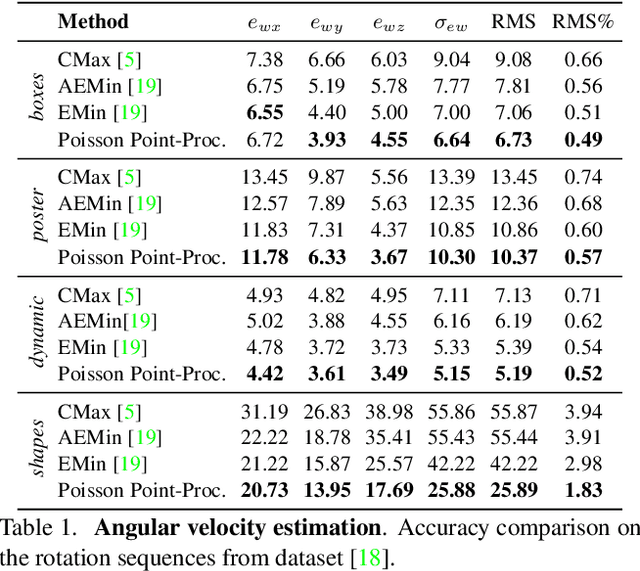
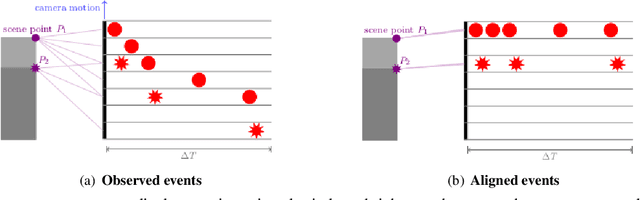
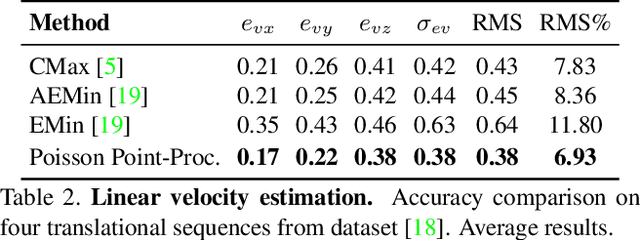
Event cameras, inspired by biological vision systems, provide a natural and data efficient representation of visual information. Visual information is acquired in the form of events that are triggered by local brightness changes. Each pixel location of the camera's sensor records events asynchronously and independently with very high temporal resolution. However, because most brightness changes are triggered by relative motion of the camera and the scene, the events recorded at a single sensor location seldom correspond to the same world point. To extract meaningful information from event cameras, it is helpful to register events that were triggered by the same underlying world point. In this work we propose a new model of event data that captures its natural spatio-temporal structure. We start by developing a model for aligned event data. That is, we develop a model for the data as though it has been perfectly registered already. In particular, we model the aligned data as a spatio-temporal Poisson point process. Based on this model, we develop a maximum likelihood approach to registering events that are not yet aligned. That is, we find transformations of the observed events that make them as likely as possible under our model. In particular we extract the camera rotation that leads to the best event alignment. We show new state of the art accuracy for rotational velocity estimation on the DAVIS 240C dataset. In addition, our method is also faster and has lower computational complexity than several competing methods.
Faster Kernel Interpolation for Gaussian Processes
Jan 28, 2021
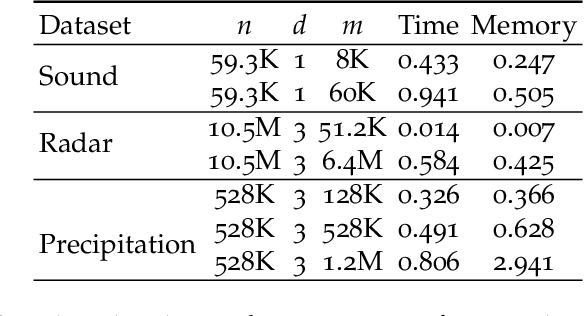

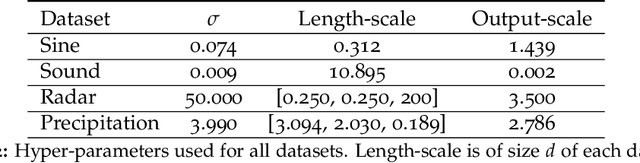
A key challenge in scaling Gaussian Process (GP) regression to massive datasets is that exact inference requires computation with a dense n x n kernel matrix, where n is the number of data points. Significant work focuses on approximating the kernel matrix via interpolation using a smaller set of m inducing points. Structured kernel interpolation (SKI) is among the most scalable methods: by placing inducing points on a dense grid and using structured matrix algebra, SKI achieves per-iteration time of O(n + m log m) for approximate inference. This linear scaling in n enables inference for very large data sets; however the cost is per-iteration, which remains a limitation for extremely large n. We show that the SKI per-iteration time can be reduced to O(m log m) after a single O(n) time precomputation step by reframing SKI as solving a natural Bayesian linear regression problem with a fixed set of m compact basis functions. With per-iteration complexity independent of the dataset size n for a fixed grid, our method scales to truly massive data sets. We demonstrate speedups in practice for a wide range of m and n and apply the method to GP inference on a three-dimensional weather radar dataset with over 100 million points.
Three-quarter Sibling Regression for Denoising Observational Data
Dec 31, 2020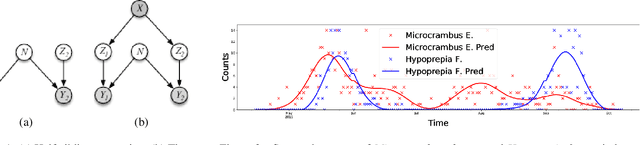
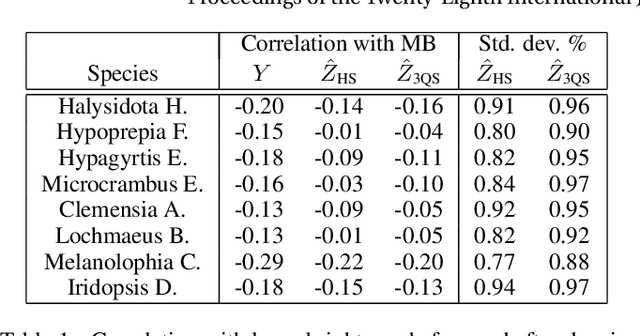
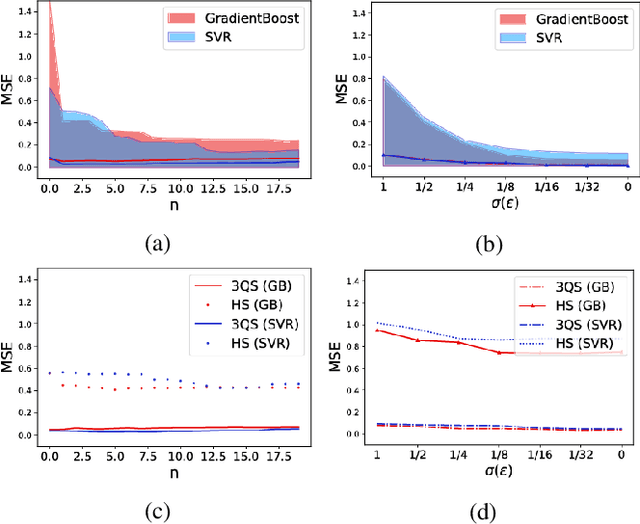
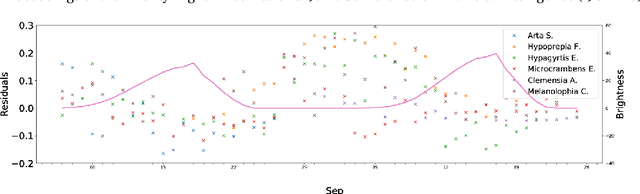
Many ecological studies and conservation policies are based on field observations of species, which can be affected by systematic variability introduced by the observation process. A recently introduced causal modeling technique called 'half-sibling regression' can detect and correct for systematic errors in measurements of multiple independent random variables. However, it will remove intrinsic variability if the variables are dependent, and therefore does not apply to many situations, including modeling of species counts that are controlled by common causes. We present a technique called 'three-quarter sibling regression' to partially overcome this limitation. It can filter the effect of systematic noise when the latent variables have observed common causes. We provide theoretical justification of this approach, demonstrate its effectiveness on synthetic data, and show that it reduces systematic detection variability due to moon brightness in moth surveys.
Normalizing Flows Across Dimensions
Jun 23, 2020
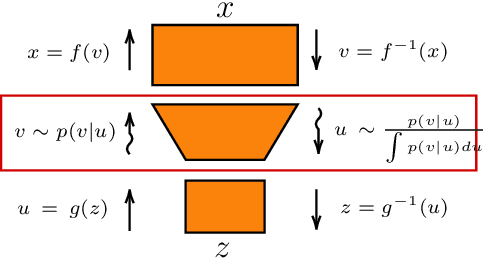

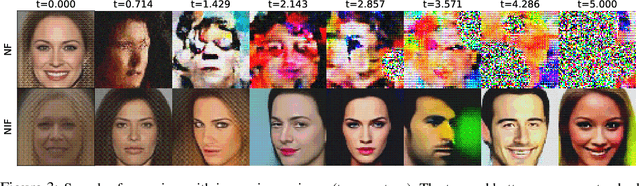
Real-world data with underlying structure, such as pictures of faces, are hypothesized to lie on a low-dimensional manifold. This manifold hypothesis has motivated state-of-the-art generative algorithms that learn low-dimensional data representations. Unfortunately, a popular generative model, normalizing flows, cannot take advantage of this. Normalizing flows are based on successive variable transformations that are, by design, incapable of learning lower-dimensional representations. In this paper we introduce noisy injective flows (NIF), a generalization of normalizing flows that can go across dimensions. NIF explicitly map the latent space to a learnable manifold in a high-dimensional data space using injective transformations. We further employ an additive noise model to account for deviations from the manifold and identify a stochastic inverse of the generative process. Empirically, we demonstrate that a simple application of our method to existing flow architectures can significantly improve sample quality and yield separable data embeddings.
Advances in Black-Box VI: Normalizing Flows, Importance Weighting, and Optimization
Jun 18, 2020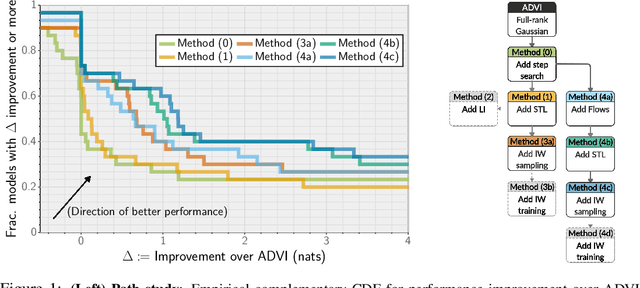
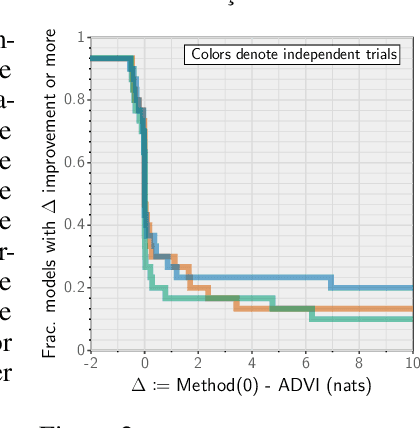
Recent research has seen several advances relevant to black-box VI, but the current state of automatic posterior inference is unclear. One such advance is the use of normalizing flows to define flexible posterior densities for deep latent variable models. Another direction is the integration of Monte-Carlo methods to serve two purposes; first, to obtain tighter variational objectives for optimization, and second, to define enriched variational families through sampling. However, both flows and variational Monte-Carlo methods remain relatively unexplored for black-box VI. Moreover, on a pragmatic front, there are several optimization considerations like step-size scheme, parameter initialization, and choice of gradient estimators, for which there are no clear guidance in the existing literature. In this paper, we postulate that black-box VI is best addressed through a careful combination of numerous algorithmic components. We evaluate components relating to optimization, flows, and Monte-Carlo methods on a benchmark of 30 models from the Stan model library. The combination of these algorithmic components significantly advances the state-of-the-art "out of the box" variational inference.