 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOTChallenge: A Benchmark for Single-camera Multiple Target Tracking
Oct 15, 2020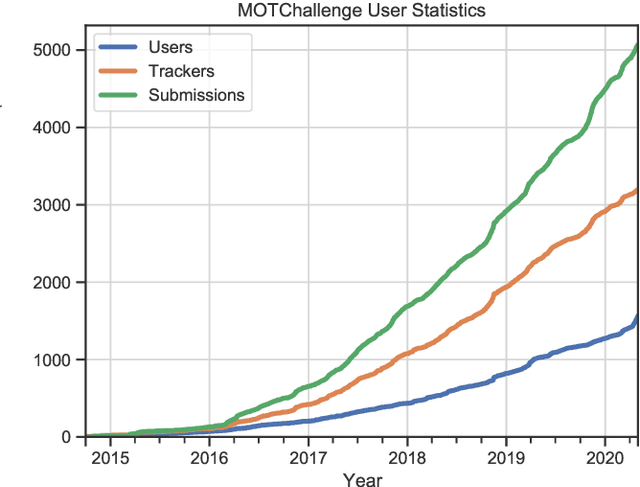
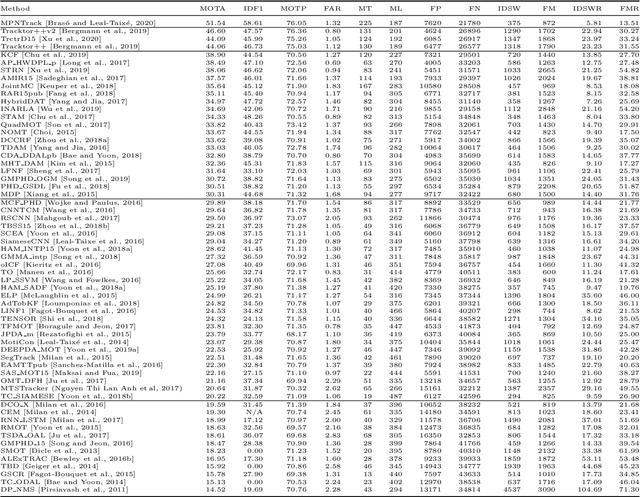

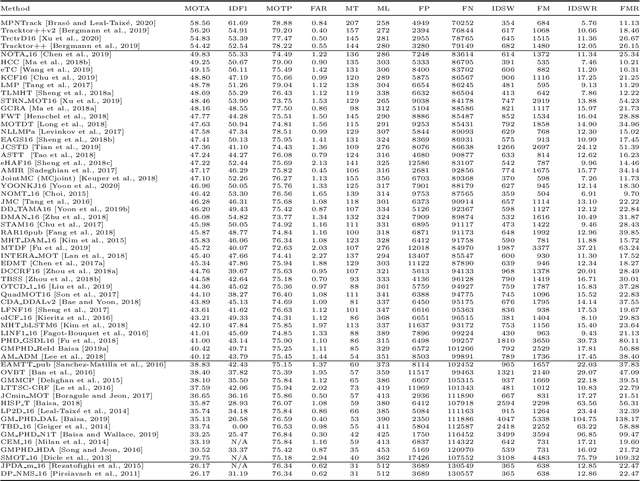
Standardized benchmarks have been crucial in pushing the performance of computer vision algorithms, especially since the advent of deep learning. Although leaderboards should not be over-claimed, they often provide the most objective measure of performance and are therefore important guides for research. We present MOTChallenge, a benchmark for single-camera Multiple Object Tracking (MOT) launched in late 2014, to collect existing and new data, and create a framework for the standardized evaluation of multiple object tracking methods. The benchmark is focused on multiple people tracking, since pedestrians are by far the most studied object in the tracking community, with applications ranging from robot navigation to self-driving cars. This paper collects the first three releases of the benchmark: (i) MOT15, along with numerous state-of-the-art results that were submitted in the last years, (ii) MOT16, which contains new challenging videos, and (iii) MOT17, that extends MOT16 sequences with more precise labels and evaluates tracking performance on three different object detectors. The second and third release not only offers a significant increase in the number of labeled boxes but also provide labels for multiple object classes beside pedestrians, as well as the level of visibility for every single object of interest. We finally provide a categorization of state-of-the-art trackers and a broad error analysis. This will help newcomers understand the related work and research trends in the MOT community, and hopefully shred some light into potential future research directions.
LM-Reloc: Levenberg-Marquardt Based Direct Visual Relocalization
Oct 13, 2020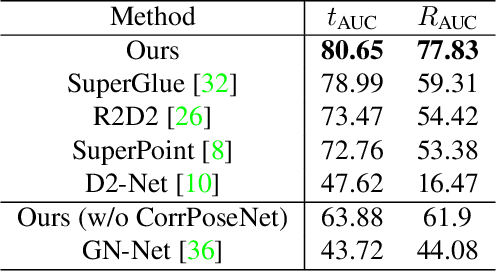
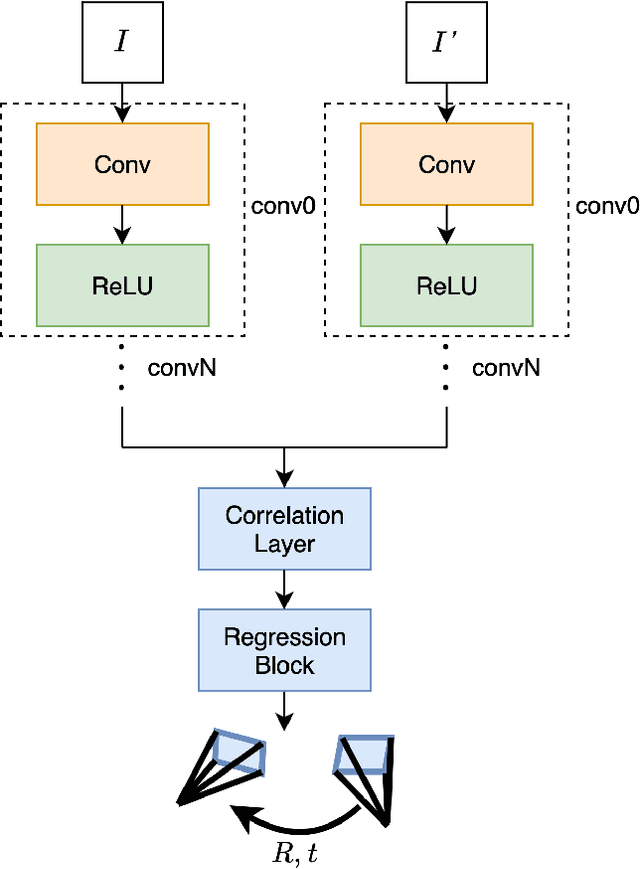
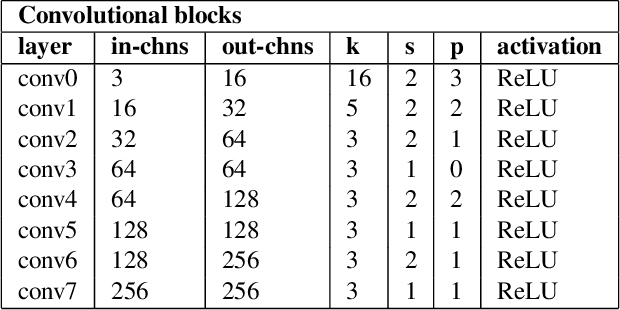
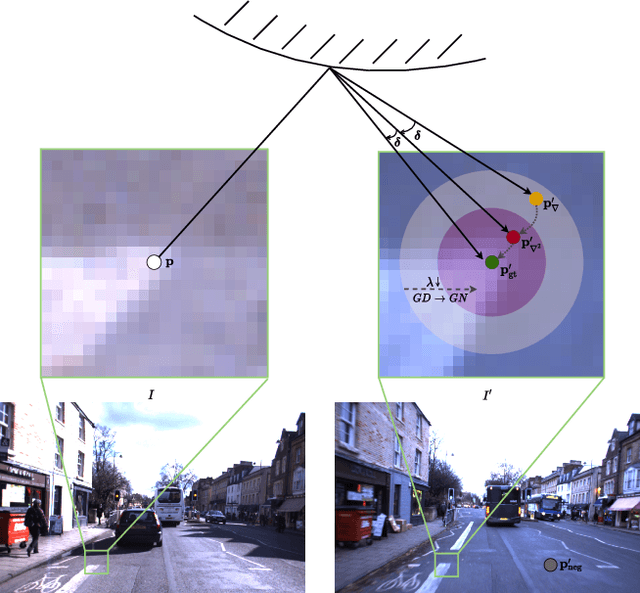
We present LM-Reloc -- a novel approach for visual relocalization based on direct image alignment. In contrast to prior works that tackle the problem with a feature-based formulation, the proposed method does not rely on feature matching and RANSAC. Hence, the method can utilize not only corners but any region of the image with gradients. In particular, we propose a loss formulation inspired by the classical Levenberg-Marquardt algorithm to train LM-Net. The learned features significantly improve the robustness of direct image alignment, especially for relocalization across different conditions. To further improve the robustness of LM-Net against large image baselines, we propose a pose estimation network, CorrPoseNet, which regresses the relative pose to bootstrap the direct image alignment. Evaluations on the CARLA and Oxford RobotCar relocalization tracking benchmark show that our approach delivers more accurate results than previous state-of-the-art methods while being comparable in terms of robustness.
4Seasons: A Cross-Season Dataset for Multi-Weather SLAM in Autonomous Driving
Sep 14, 2020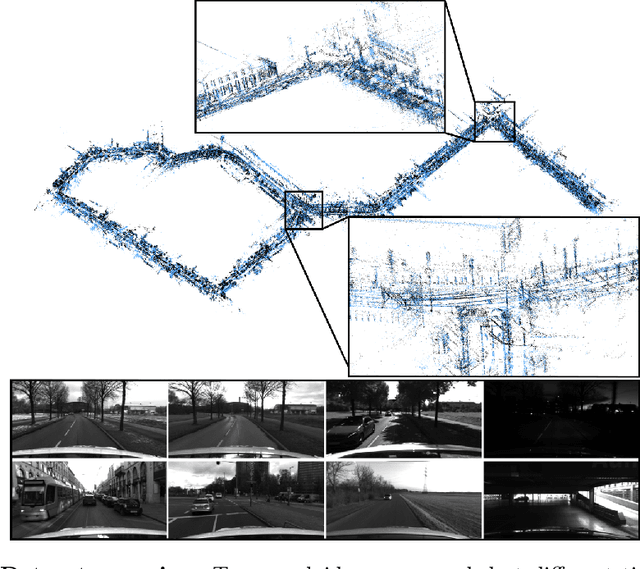
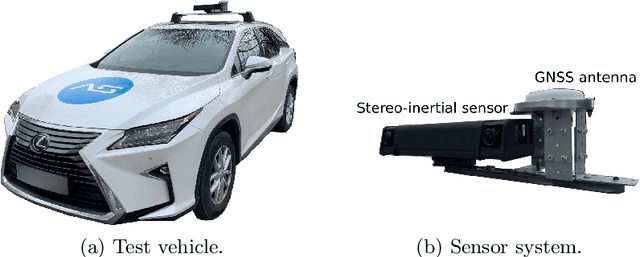
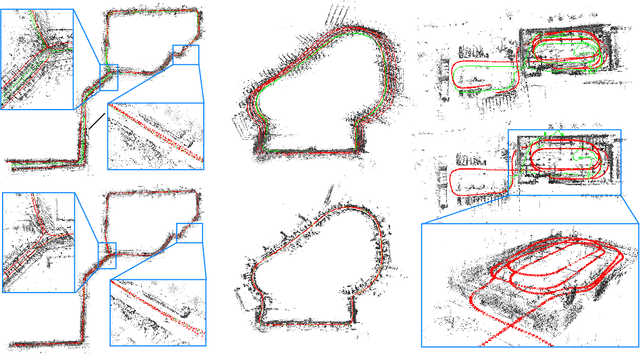

We present a novel dataset covering seasonal and challenging perceptual conditions for autonomous driving. Among others, it enables research on visual odometry, global place recognition, and map-based re-localization tracking. The data was collected in different scenarios and under a wide variety of weather conditions and illuminations, including day and night. This resulted in more than 350 km of recordings in nine different environments ranging from multi-level parking garage over urban (including tunnels) to countryside and highway. We provide globally consistent reference poses with up-to centimeter accuracy obtained from the fusion of direct stereo visual-inertial odometry with RTK-GNSS. The full dataset is available at www.4seasons-dataset.com.
DH3D: Deep Hierarchical 3D Descriptors for Robust Large-Scale 6DoF Relocalization
Jul 17, 2020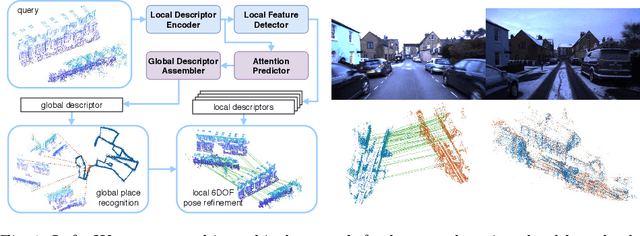
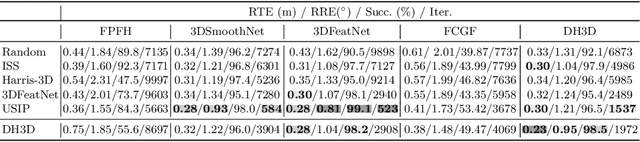
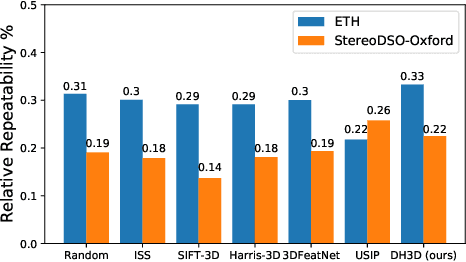
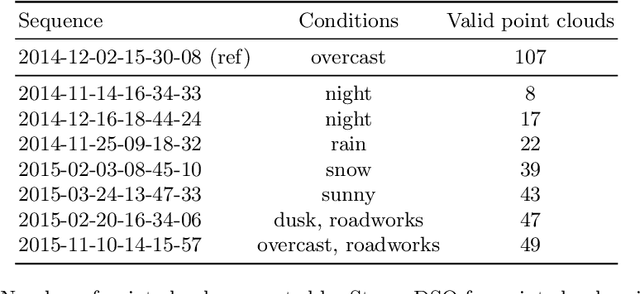
For relocalization in large-scale point clouds, we propose the first approach that unifies global place recognition and local 6DoF pose refinement. To this end, we design a Siamese network that jointly learns 3D local feature detection and description directly from raw 3D points. It integrates FlexConv and Squeeze-and-Excitation (SE) to assure that the learned local descriptor captures multi-level geometric information and channel-wise relations. For detecting 3D keypoints we predict the discriminativeness of the local descriptors in an unsupervised manner. We generate the global descriptor by directly aggregating the learned local descriptors with an effective attention mechanism. In this way, local and global 3D descriptors are inferred in one single forward pass. Experiments on various benchmarks demonstrate that our method achieves competitive results for both global point cloud retrieval and local point cloud registration in comparison to state-of-the-art approaches. To validate the generalizability and robustness of our 3D keypoints, we demonstrate that our method also performs favorably without fine-tuning on the registration of point clouds that were generated by a visual SLAM system. Code and related materials are available at https://vision.in.tum.de/research/vslam/dh3d.
Deriving Neural Network Design and Learning from the Probabilistic Framework of Chain Graphs
Jun 30, 2020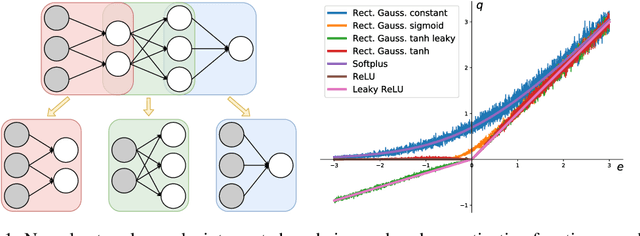

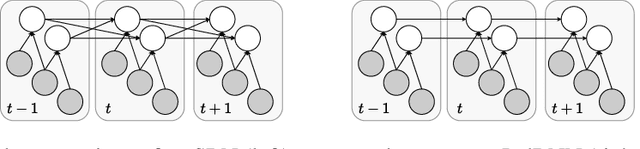
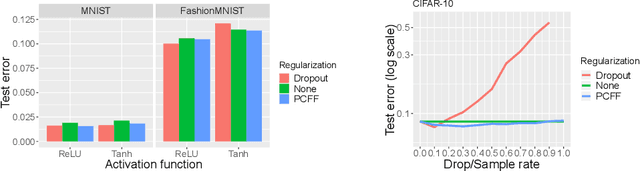
The last decade has witnessed a boom of neural network (NN) research and applications achieving state-of-the-art results in various domains. Yet, most advances on architecture and learning have been discovered empirically in a trial-and-error manner such that a more systematic exploration is difficult. Their theoretical analyses are limited and a unifying framework is absent. In this paper, we tackle this issue by identifying NNs as chain graphs (CGs) with chain components modeled as bipartite pairwise conditional random fields, and feed-forward as a form of approximate probabilistic inference. We show that from this CG interpretation we can systematically formulate an extensive range of the empirically discovered results, including various network designs (e.g., CNN, RNN, ResNet), activation functions (e.g., sigmoid, tanh, softmax, (leaky) ReLU) and regularizations (e.g., weight decay, dropout, BatchNorm). Furthermore, guided by this interpretation, we are able to derive "the preferred form" of residual block, recover the simple yet powerful IndRNN model and discover a new stochastic inference procedure: the partially collapsed feed-forward inference. We believe that our work can provide a well-founded formulation to analyze the nature and design of NNs, and can serve as a unifying theoretical framework for deep learning research.
Deep Learning for Virtual Screening: Five Reasons to Use ROC Cost Functions
Jun 25, 2020Computer-aided drug discovery is an essential component of modern drug development. Therein, deep learning has become an important tool for rapid screening of billions of molecules in silico for potential hits containing desired chemical features. Despite its importance, substantial challenges persist in training these models, such as severe class imbalance, high decision thresholds, and lack of ground truth labels in some datasets. In this work we argue in favor of directly optimizing the receiver operating characteristic (ROC) in such cases, due to its robustness to class imbalance, its ability to compromise over different decision thresholds, certain freedom to influence the relative weights in this compromise, fidelity to typical benchmarking measures, and equivalence to positive/unlabeled learning. We also propose new training schemes (coherent mini-batch arrangement, and usage of out-of-batch samples) for cost functions based on the ROC, as well as a cost function based on the logAUC metric that facilitates early enrichment (i.e. improves performance at high decision thresholds, as often desired when synthesizing predicted hit compounds). We demonstrate that these approaches outperform standard deep learning approaches on a series of PubChem high-throughput screening datasets that represent realistic and diverse drug discovery campaigns on major drug target families.
Effective Version Space Reduction for Convolutional Neural Networks
Jun 22, 2020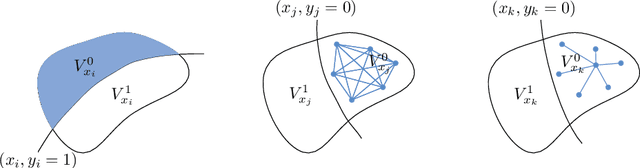

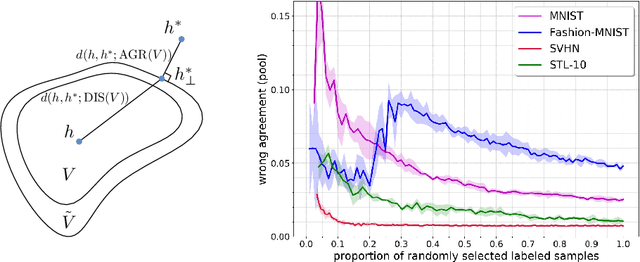
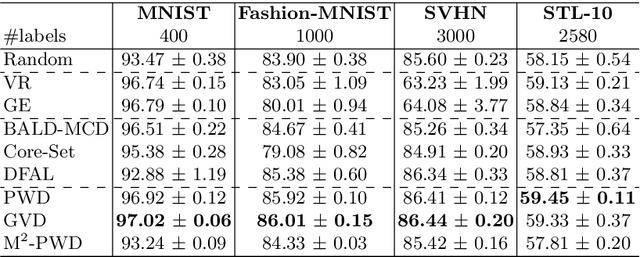
In active learning, sampling bias could pose a serious inconsistency problem and hinder the algorithm from finding the optimal hypothesis. However, many methods for neural networks are hypothesis space agnostic and do not address this problem. We examine active learning with convolutional neural networks through the principled lens of version space reduction. We identify the connection between two approaches---prior mass reduction and diameter reduction---and propose a new diameter-based querying method---the minimum Gibbs-vote disagreement. By estimating version space diameter and bias, we illustrate how version space of neural networks evolves and examine the realizability assumption. With experiments on MNIST, Fashion-MNIST, SVHN and STL-10 datasets, we demonstrate that diameter reduction methods reduce the version space more effectively and perform better than prior mass reduction and other baselines, and that the Gibbs vote disagreement is on par with the best query method.
PrimiTect: Fast Continuous Hough Voting for Primitive Detection
May 15, 2020
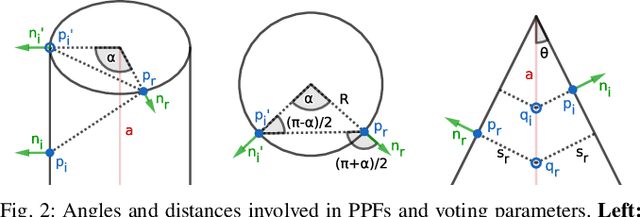
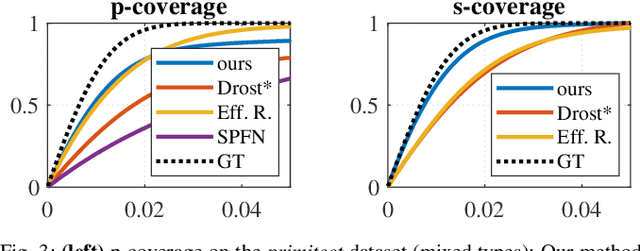
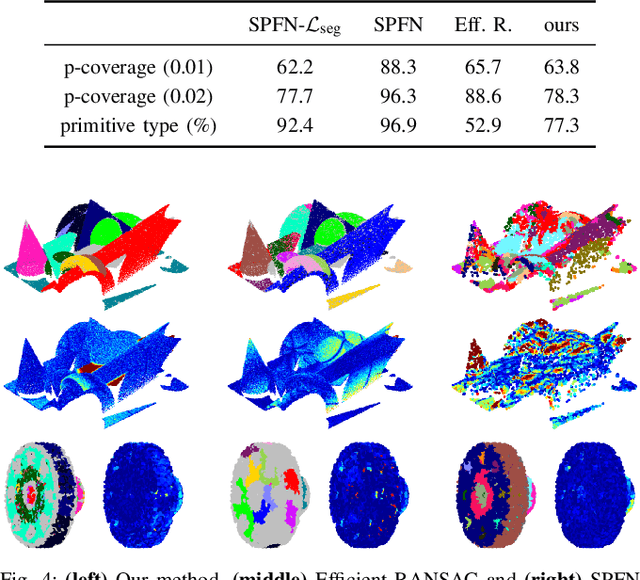
This paper tackles the problem of data abstraction in the context of 3D point sets. Our method classifies points into different geometric primitives, such as planes and cones, leading to a compact representation of the data. Being based on a semi-global Hough voting scheme, the method does not need initialization and is robust, accurate, and efficient. We use a local, low-dimensional parameterization of primitives to determine type, shape and pose of the object that a point belongs to. This makes our algorithm suitable to run on devices with low computational power, as often required in robotics applications. The evaluation shows that our method outperforms state-of-the-art methods both in terms of accuracy and robustness.
Hamiltonian Dynamics for Real-World Shape Interpolation
Apr 10, 2020
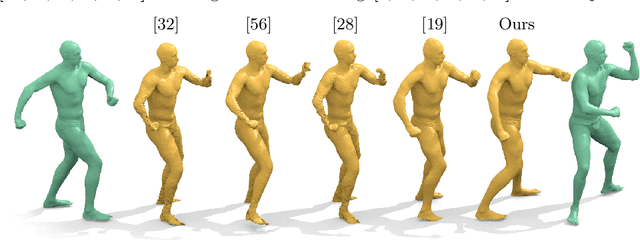
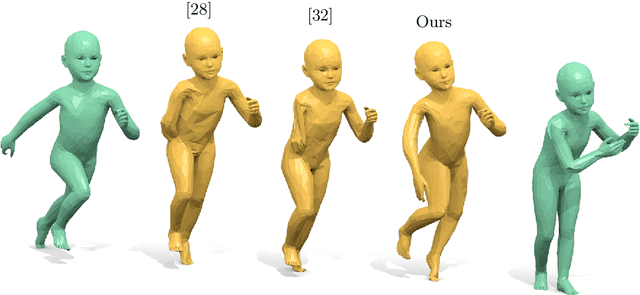

We revisit the classical problem of 3D shape interpolation and propose a novel, physically plausible approach based on Hamiltonian dynamics. While most prior work focuses on synthetic input shapes, our formulation is designed to be applicable to real-world scans with imperfect input correspondences and various types of noise. To that end, we use recent progress on dynamic thin shell simulation and divergence-free shape deformation and combine them to address the inverse problem of finding a plausible intermediate sequence for two input shapes. In comparison to prior work that mainly focuses on small distortion of consecutive frames, we explicitly model volume preservation and momentum conservation, as well as an anisotropic local distortion model. We argue that, in order to get a robust interpolation for imperfect inputs, we need to model the input noise explicitly which results in an alignment based formulation. Finally, we show a qualitative and quantitative improvement over prior work on a broad range of synthetic and scanned data. Besides being more robust to noisy inputs, our method yields exactly volume preserving intermediate shapes, avoids self-intersections and is scalable to high resolution scans.
D3VO: Deep Depth, Deep Pose and Deep Uncertainty for Monocular Visual Odometry
Mar 28, 2020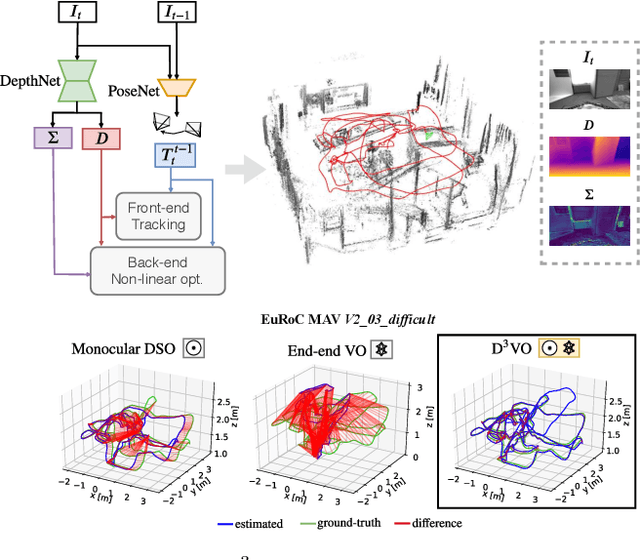
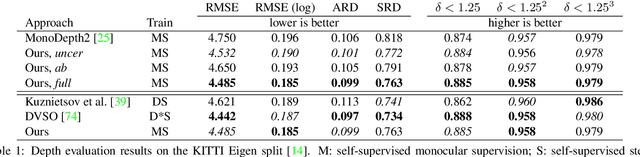
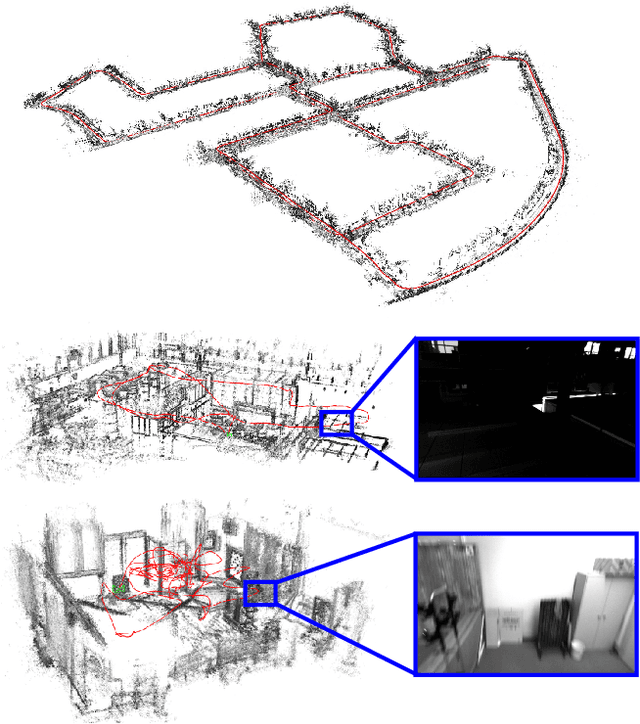
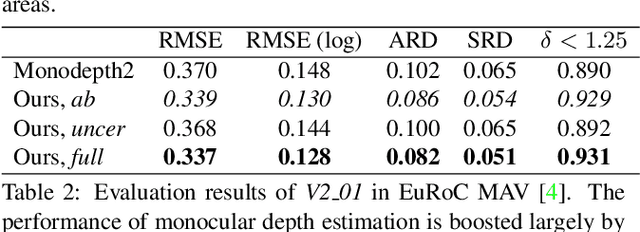
We propose D3VO as a novel framework for monocular visual odometry that exploits deep networks on three levels -- deep depth, pose and uncertainty estimation. We first propose a novel self-supervised monocular depth estimation network trained on stereo videos without any external supervision. In particular, it aligns the training image pairs into similar lighting condition with predictive brightness transformation parameters. Besides, we model the photometric uncertainties of pixels on the input images, which improves the depth estimation accuracy and provides a learned weighting function for the photometric residuals in direct (feature-less) visual odometry. Evaluation results show that the proposed network outperforms state-of-the-art self-supervised depth estimation networks. D3VO tightly incorporates the predicted depth, pose and uncertainty into a direct visual odometry method to boost both the front-end tracking as well as the back-end non-linear optimization. We evaluate D3VO in terms of monocular visual odometry on both the KITTI odometry benchmark and the EuRoC MAV dataset.The results show that D3VO outperforms state-of-the-art traditional monocular VO methods by a large margin. It also achieves comparable results to state-of-the-art stereo/LiDAR odometry on KITTI and to the state-of-the-art visual-inertial odometry on EuRoC MAV, while using only a single camera.