 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotation-Equivariant Deep Learning for Diffusion MRI
Feb 13, 2021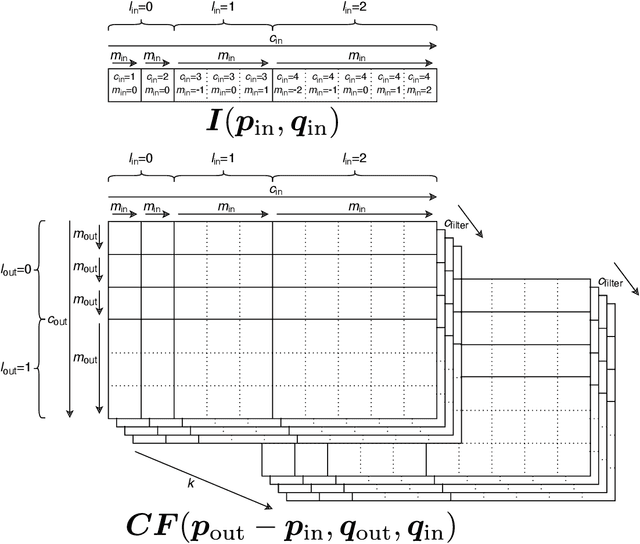
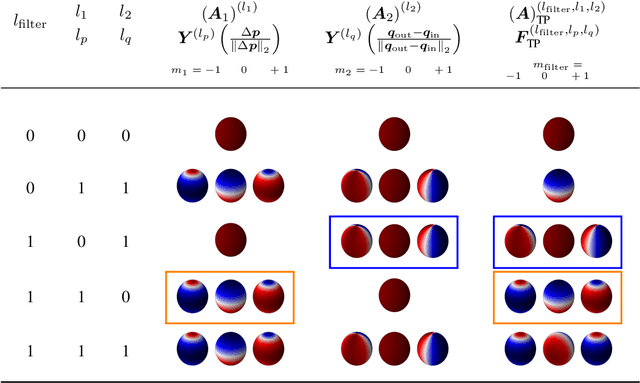
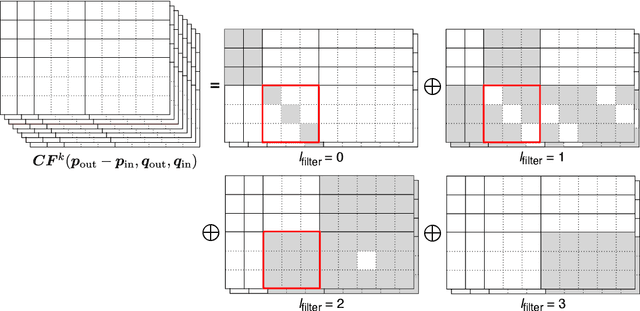
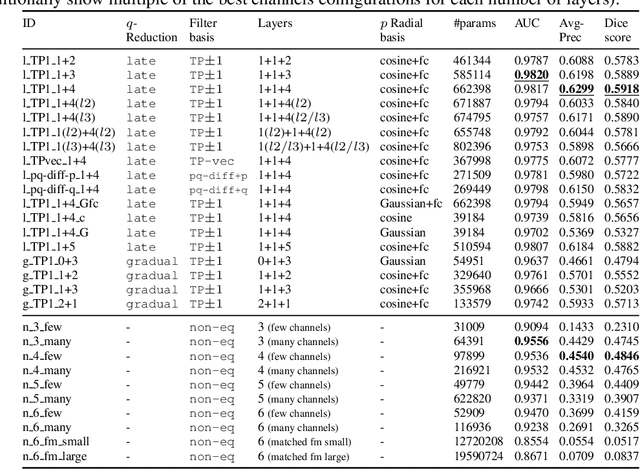
Convolutional networks are successful, but they have recently been outperformed by new neural networks that are equivariant under rotations and translations. These new networks work better because they do not struggle with learning each possible orientation of each image feature separately. So far, they have been proposed for 2D and 3D data. Here we generalize them to 6D diffusion MRI data, ensuring joint equivariance under 3D roto-translations in image space and the matching 3D rotations in $q$-space, as dictated by the image formation. Such equivariant deep learning is appropriate for diffusion MRI, because microstructural and macrostructural features such as neural fibers can appear at many different orientations, and because even non-rotation-equivariant deep learning has so far been the best method for many diffusion MRI tasks. We validate our equivariant method on multiple-sclerosis lesion segmentation. Our proposed neural networks yield better results and require fewer scans for training compared to non-rotation-equivariant deep learning. They also inherit all the advantages of deep learning over classical diffusion MRI methods. Our implementation is available at https://github.com/philip-mueller/equivariant-deep-dmri and can be used off the shelf without understanding the mathematical background.
Tight Integration of Feature-Based Relocalization in Monocular Direct Visual Odometry
Feb 08, 2021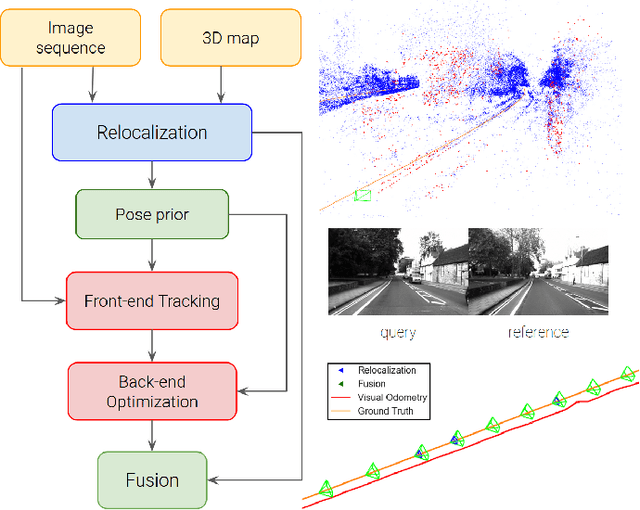
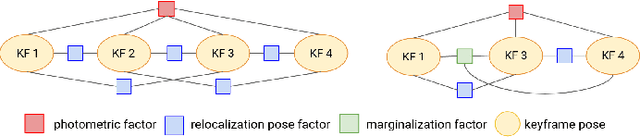
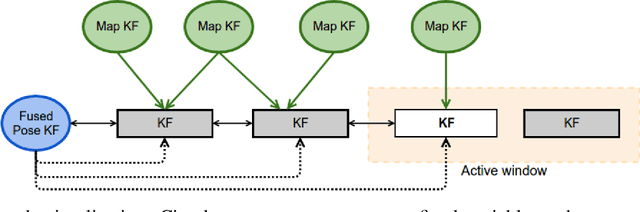
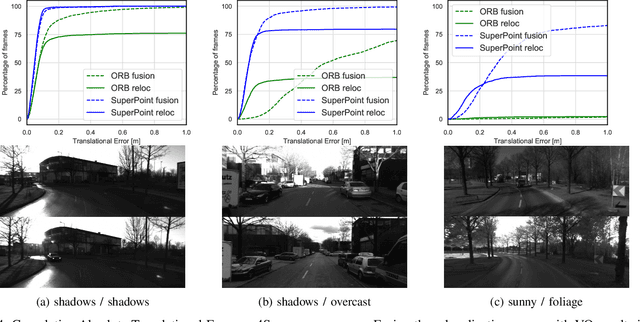
In this paper we propose a framework for integrating map-based relocalization into online direct visual odometry. To achieve map-based relocalization for direct methods, we integrate image features into Direct Sparse Odometry (DSO) and rely on feature matching to associate online visual odometry (VO) with a previously built map. The integration of the relocalization poses is threefold. Firstly, they are treated as pose priors and tightly integrated into the direct image alignment of the front-end tracking. Secondly, they are also tightly integrated into the back-end bundle adjustment. An online fusion module is further proposed to combine relative VO poses and global relocalization poses in a pose graph to estimate keyframe-wise smooth and globally accurate poses. We evaluate our method on two multi-weather datasets showing the benefits of integrating different handcrafted and learned features and demonstrating promising improvements on camera tracking accuracy.
Post-hoc Uncertainty Calibration for Domain Drift Scenarios
Dec 20, 2020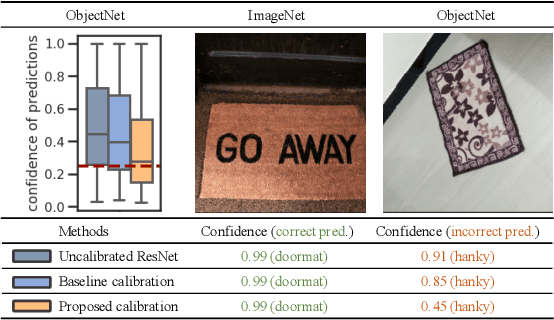
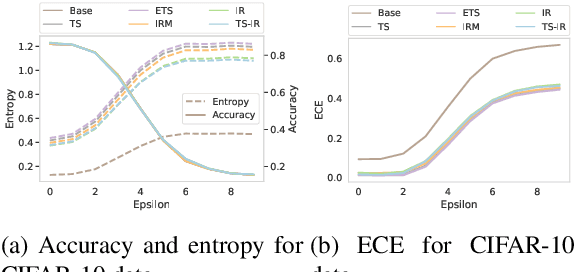
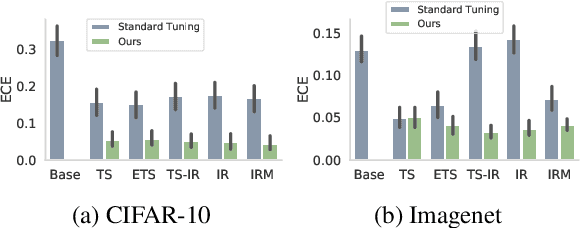
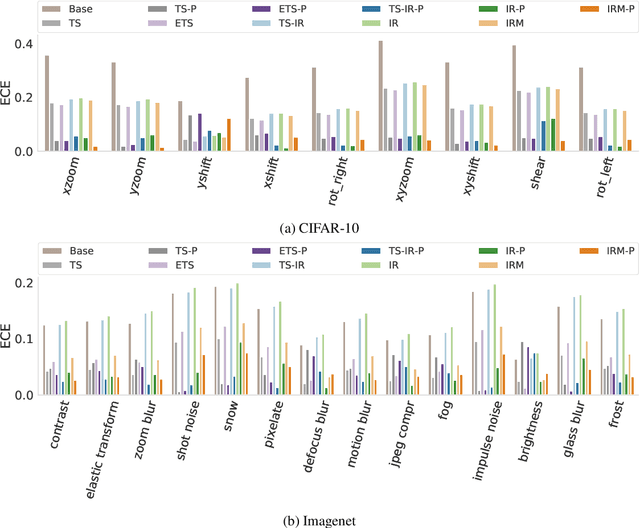
We address the problem of uncertainty calibration. While standard deep neural networks typically yield uncalibrated predictions, calibrated confidence scores that are representative of the true likelihood of a prediction can be achieved using post-hoc calibration methods. However, to date the focus of these approaches has been on in-domain calibration. Our contribution is two-fold. First, we show that existing post-hoc calibration methods yield highly over-confident predictions under domain shift. Second, we introduce a simple strategy where perturbations are applied to samples in the validation set before performing the post-hoc calibration step. In extensive experiments, we demonstrate that this perturbation step results in substantially better calibration under domain shift on a wide range of architectures and modelling tasks.
Neural Online Graph Exploration
Dec 06, 2020
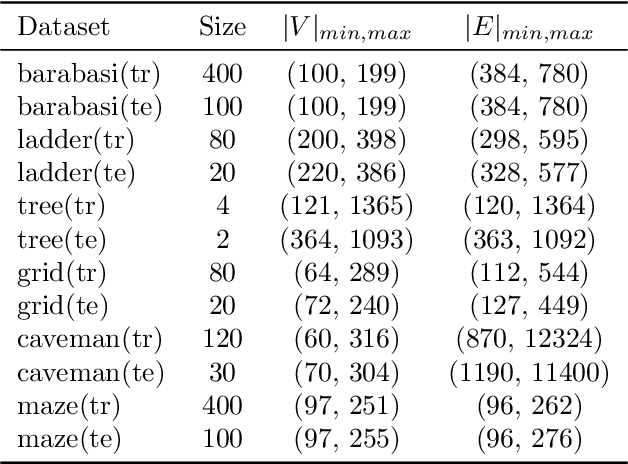

Can we learn how to explore unknown spaces efficiently? To answer this question, we study the problem of Online Graph Exploration, the online version of the Traveling Salesperson Problem. We reformulate graph exploration as a reinforcement learning problem and apply Direct Future Prediction (Dosovitskiy and Koltun, 2016) to solve it. As the graph is discovered online, the corresponding Markov Decision Process entails a dynamic state space, namely the observable graph and a dynamic action space, namely the nodes forming the graph's frontier. To the best of our knowledge, this is the first attempt to solve online graph exploration in a data-driven way. We conduct experiments on six data sets of procedurally generated graphs and three real city road networks. We demonstrate that our agent can learn strategies superior to many well known graph traversal algorithms, confirming that exploration can be learned.
Isometric Multi-Shape Matching
Dec 04, 2020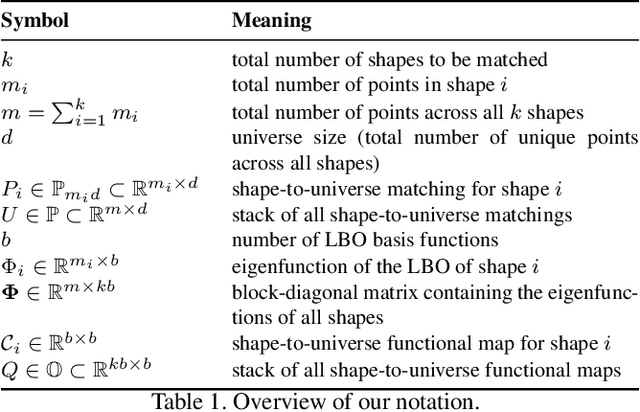
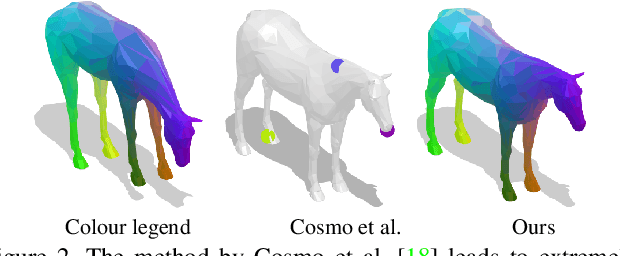
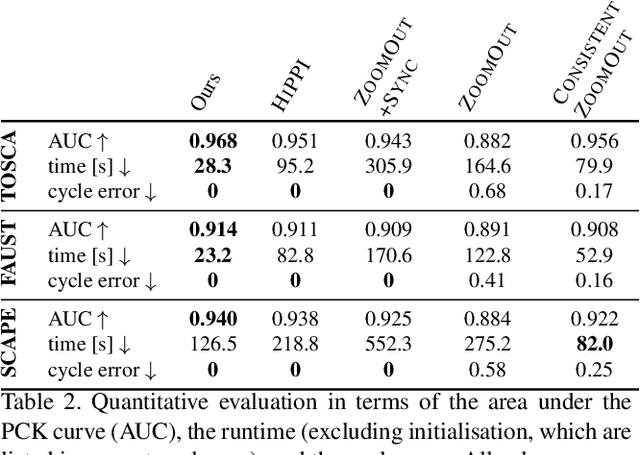
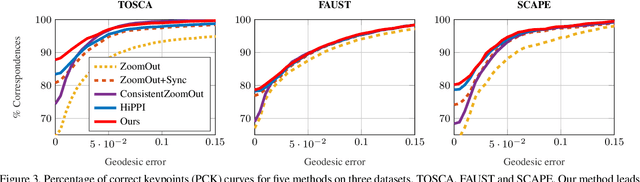
Finding correspondences between shapes is a fundamental problem in computer vision and graphics, which is relevant for many applications, including 3D reconstruction, object tracking, and style transfer. The vast majority of correspondence methods aim to find a solution between pairs of shapes, even if multiple instances of the same class are available. While isometries are often studied in shape correspondence problems, they have not been considered explicitly in the multi-matching setting. This paper closes this gap by proposing a novel optimisation formulation for isometric multi-shape matching. We present a suitable optimisation algorithm for solving our formulation and provide a convergence and complexity analysis. Our algorithm obtains multi-matchings that are by construction provably cycle-consistent. We demonstrate the superior performance of our method on various datasets and set the new state-of-the-art in isometric multi-shape matching.
i3DMM: Deep Implicit 3D Morphable Model of Human Heads
Nov 28, 2020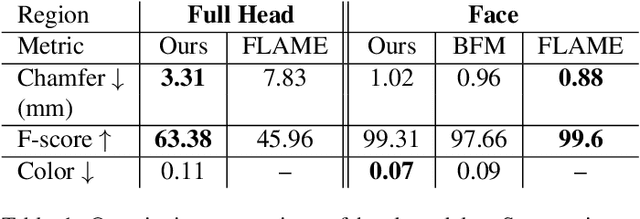


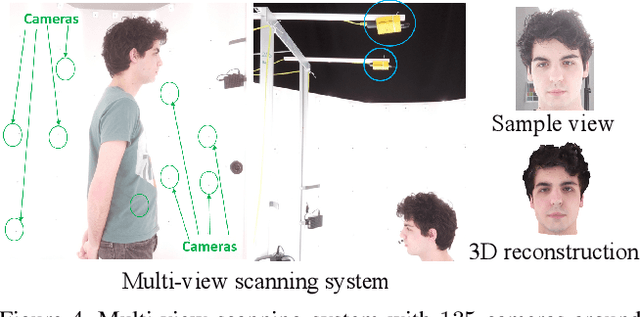
We present the first deep implicit 3D morphable model (i3DMM) of full heads. Unlike earlier morphable face models it not only captures identity-specific geometry, texture, and expressions of the frontal face, but also models the entire head, including hair. We collect a new dataset consisting of 64 people with different expressions and hairstyles to train i3DMM. Our approach has the following favorable properties: (i) It is the first full head morphable model that includes hair. (ii) In contrast to mesh-based models it can be trained on merely rigidly aligned scans, without requiring difficult non-rigid registration. (iii) We design a novel architecture to decouple the shape model into an implicit reference shape and a deformation of this reference shape. With that, dense correspondences between shapes can be learned implicitly. (iv) This architecture allows us to semantically disentangle the geometry and color components, as color is learned in the reference space. Geometry is further disentangled as identity, expressions, and hairstyle, while color is disentangled as identity and hairstyle components. We show the merits of i3DMM using ablation studies, comparisons to state-of-the-art models, and applications such as semantic head editing and texture transfer. We will make our model publicly available.
Non-Rigid Puzzles
Nov 26, 2020Shape correspondence is a fundamental problem in computer graphics and vision, with applications in various problems including animation, texture mapping, robotic vision, medical imaging, archaeology and many more. In settings where the shapes are allowed to undergo non-rigid deformations and only partial views are available, the problem becomes very challenging. To this end, we present a non-rigid multi-part shape matching algorithm. We assume to be given a reference shape and its multiple parts undergoing a non-rigid deformation. Each of these query parts can be additionally contaminated by clutter, may overlap with other parts, and there might be missing parts or redundant ones. Our method simultaneously solves for the segmentation of the reference model, and for a dense correspondence to (subsets of) the parts. Experimental results on synthetic as well as real scans demonstrate the effectiveness of our method in dealing with this challenging matching scenario.
SOE-Net: A Self-Attention and Orientation Encoding Network for Point Cloud based Place Recognition
Nov 24, 2020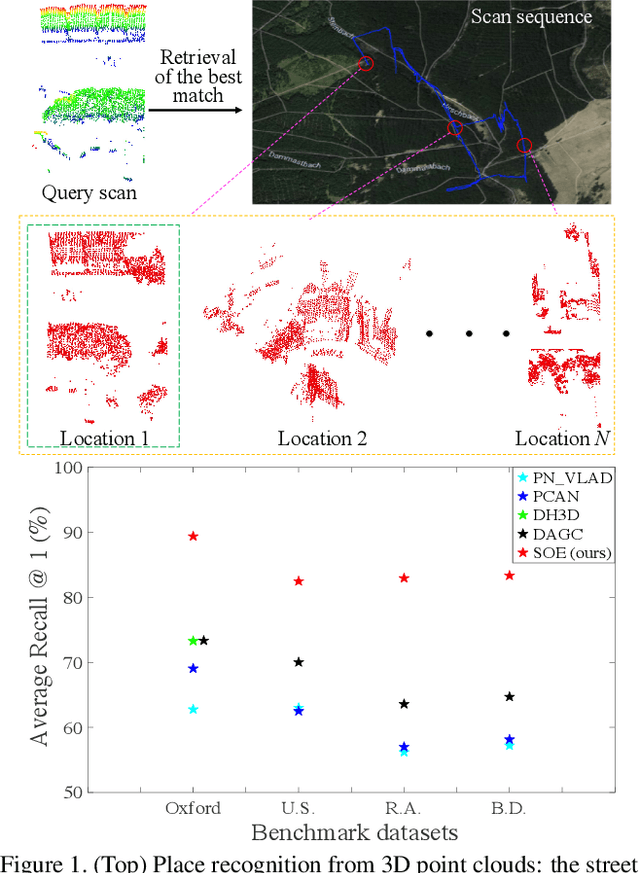
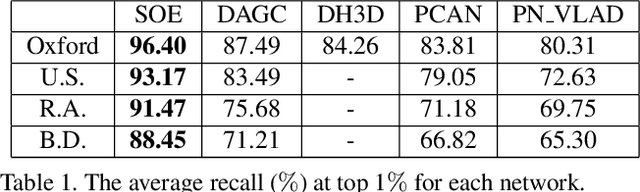

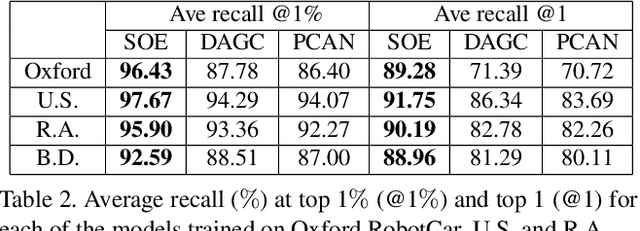
We tackle the problem of place recognition from point cloud data and introduce a self-attention and orientation encoding network (SOE-Net) that fully explores the relationship between points and incorporates long-range context into point-wise local descriptors. Local information of each point from eight orientations is captured in a PointOE module, whereas long-range feature dependencies among local descriptors are captured with a self-attention unit. Moreover, we propose a novel loss function called Hard Positive Hard Negative quadruplet loss (HPHN quadruplet), that achieves better performance than the commonly used metric learning loss. Experiments on various benchmark datasets demonstrate promising performance of the proposed network. It significantly outperforms the current state-of-the-art approaches - the average recall at top 1 retrieval on the Oxford RobotCar dataset is improved by over 16%. Codes and the trained model will be made publicly available.
MonoRec: Semi-Supervised Dense Reconstruction in Dynamic Environments from a Single Moving Camera
Nov 24, 2020
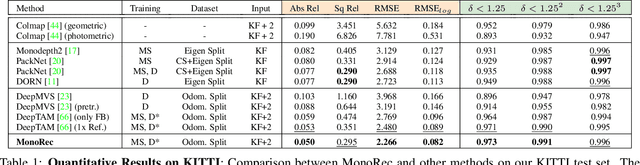
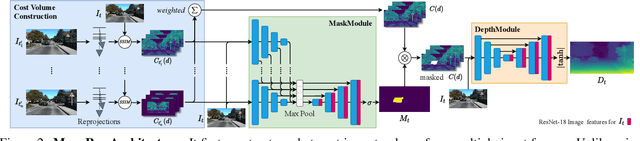

In this paper, we propose MonoRec, a semi-supervised monocular dense reconstruction architecture that predicts depth maps from a single moving camera in dynamic environments. MonoRec is based on a MVS setting which encodes the information of multiple consecutive images in a cost volume. To deal with dynamic objects in the scene, we introduce a MaskModule that predicts moving object masks by leveraging the photometric inconsistencies encoded in the cost volumes. Unlike other MVS methods, MonoRec is able to predict accurate depths for both static and moving objects by leveraging the predicted masks. Furthermore, we present a novel multi-stage training scheme with a semi-supervised loss formulation that does not require LiDAR depth values. We carefully evaluate MonoRec on the KITTI dataset and show that it achieves state-of-the-art performance compared to both multi-view and single-view methods. With the model trained on KITTI, we further demonstrate that MonoRec is able to generalize well to both the Oxford RobotCar dataset and the more challenging TUM-Mono dataset recorded by a handheld camera. Training code and pre-trained model will be published soon.
Deep Shells: Unsupervised Shape Correspondence with Optimal Transport
Oct 28, 2020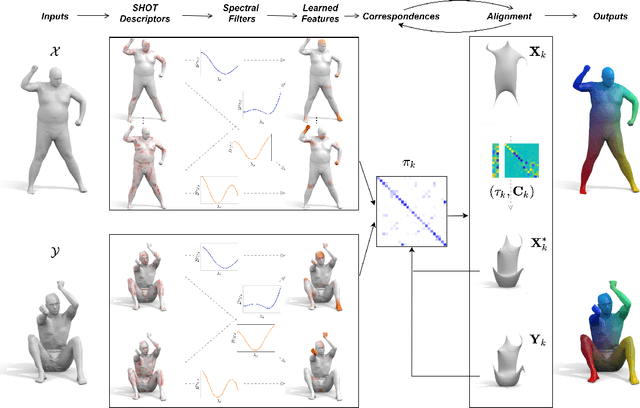
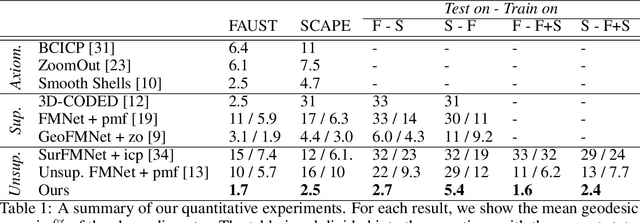


We propose a novel unsupervised learning approach to 3D shape correspondence that builds a multiscale matching pipeline into a deep neural network. This approach is based on smooth shells, the current state-of-the-art axiomatic correspondence method, which requires an a priori stochastic search over the space of initial poses. Our goal is to replace this costly preprocessing step by directly learning good initializations from the input surfaces. To that end, we systematically derive a fully differentiable, hierarchical matching pipeline from entropy regularized optimal transport. This allows us to combine it with a local feature extractor based on smooth, truncated spectral convolution filters. Finally, we show that the proposed unsupervised method significantly improves over the state-of-the-art on multiple datasets, even in comparison to the most recent supervised methods. Moreover, we demonstrate compelling generalization results by applying our learned filters to examples that significantly deviate from the training set.