 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-NeRF: Neural Radiance Fields from a Moving Event Camera
Aug 24, 2022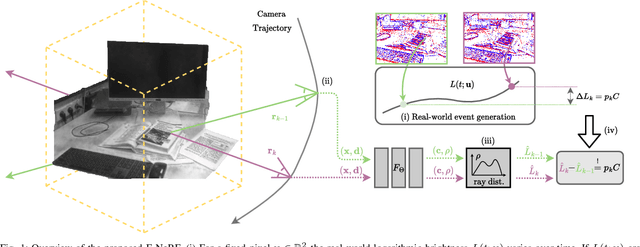
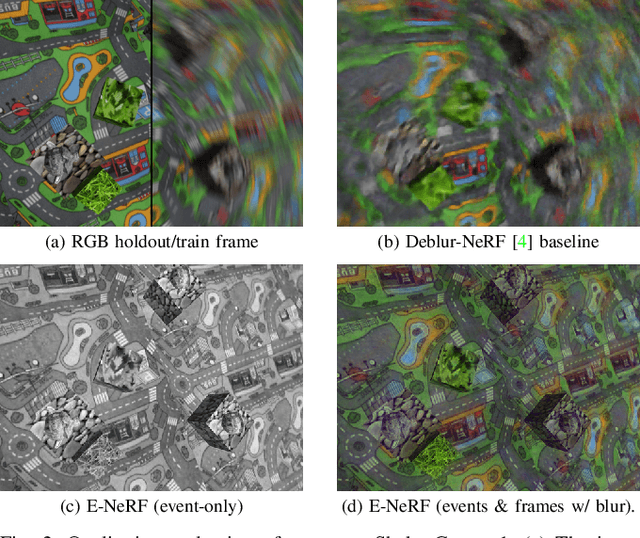


Estimating neural radiance fields (NeRFs) from ideal images has been extensively studied in the computer vision community. Most approaches assume optimal illumination and slow camera motion. These assumptions are often violated in robotic applications, where images contain motion blur and the scene may not have suitable illumination. This can cause significant problems for downstream tasks such as navigation, inspection or visualization of the scene. To alleviate these problems we present E-NeRF, the first method which estimates a volumetric scene representation in the form of a NeRF from a fast-moving event camera. Our method can recover NeRFs during very fast motion and in high dynamic range conditions, where frame-based approaches fail. We show that rendering high-quality frames is possible by only providing an event stream as input. Furthermore, by combining events and frames, we can estimate NeRFs of higher quality than state-of-the-art approaches under severe motion blur. We also show that combining events and frames can overcome failure cases of NeRF estimation in scenarios where only few input views are available, without requiring additional regularization.
Semantic Self-adaptation: Enhancing Generalization with a Single Sample
Aug 10, 2022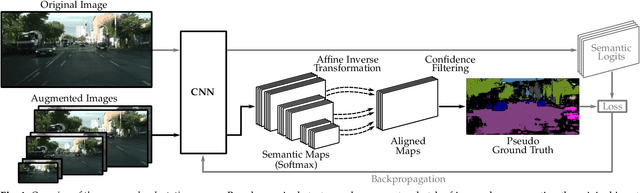

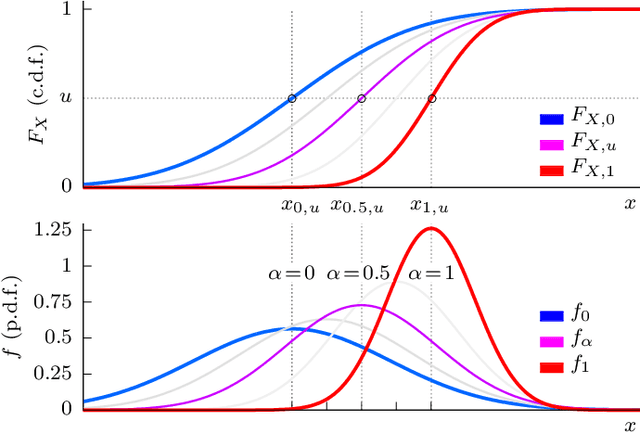
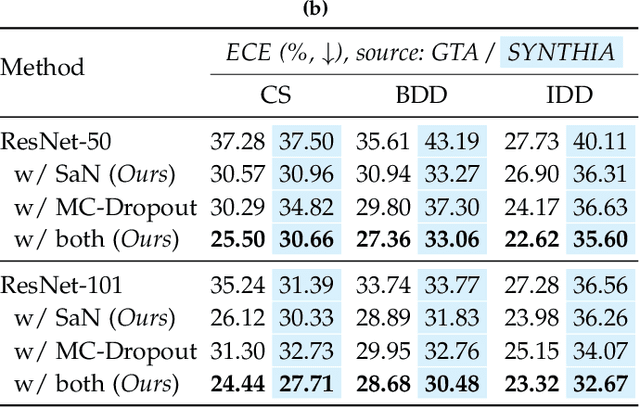
Despite years of research, out-of-domain generalization remains a critical weakness of deep networks for semantic segmentation. Previous studies relied on the assumption of a static model, i.e. once the training process is complete, model parameters remain fixed at test time. In this work, we challenge this premise with a self-adaptive approach for semantic segmentation that adjusts the inference process to each input sample. Self-adaptation operates on two levels. First, it employs a self-supervised loss that customizes the parameters of convolutional layers in the network to the input image. Second, in Batch Normalization layers, self-adaptation approximates the mean and the variance of the entire test data, which is assumed unavailable. It achieves this by interpolating between the training and the reference distribution derived from a single test sample. To empirically analyze our self-adaptive inference strategy, we develop and follow a rigorous evaluation protocol that addresses serious limitations of previous work. Our extensive analysis leads to a surprising conclusion: Using a standard training procedure, self-adaptation significantly outperforms strong baselines and sets new state-of-the-art accuracy on multi-domain benchmarks. Our study suggests that self-adaptive inference may complement the established practice of model regularization at training time for improving deep network generalization to out-of-domain data.
Efficient and Flexible Sublabel-Accurate Energy Minimization
Jun 20, 2022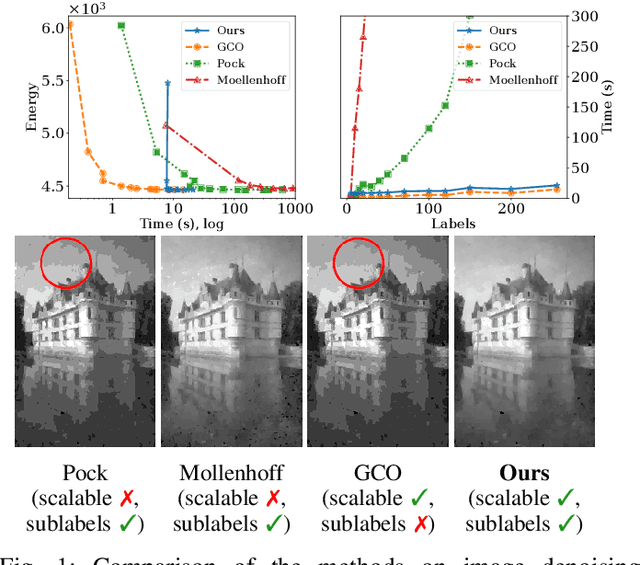

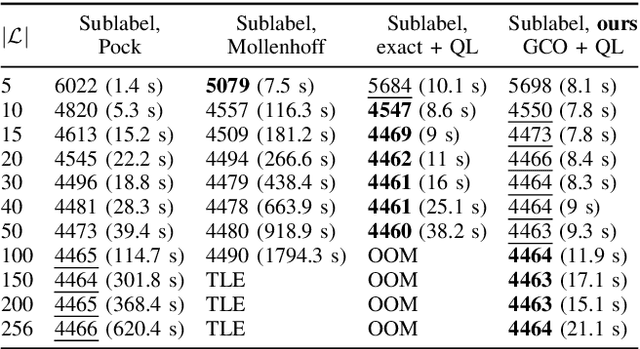
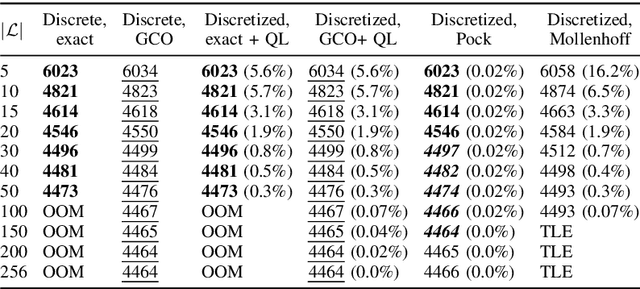
We address the problem of minimizing a class of energy functions consisting of data and smoothness terms that commonly occur in machine learning, computer vision, and pattern recognition. While discrete optimization methods are able to give theoretical optimality guarantees, they can only handle a finite number of labels and therefore suffer from label discretization bias. Existing continuous optimization methods can find sublabel-accurate solutions, but they are not efficient for large label spaces. In this work, we propose an efficient sublabel-accurate method that utilizes the best properties of both continuous and discrete models. We separate the problem into two sequential steps: (i) global discrete optimization for selecting the label range, and (ii) efficient continuous sublabel-accurate local refinement of a convex approximation of the energy function in the chosen range. Doing so allows us to achieve a boost in time and memory efficiency while practically keeping the accuracy at the same level as continuous convex relaxation methods, and in addition, providing theoretical optimality guarantees at the level of discrete methods. Finally, we show the flexibility of the proposed approach to general pairwise smoothness terms, so that it is applicable to a wide range of regularizations. Experiments on the illustrating example of the image denoising problem demonstrate the properties of the proposed method. The code reproducing experiments is available at \url{https://github.com/nurlanov-zh/sublabel-accurate-alpha-expansion}.
Biologically Inspired Neural Path Finding
Jun 13, 2022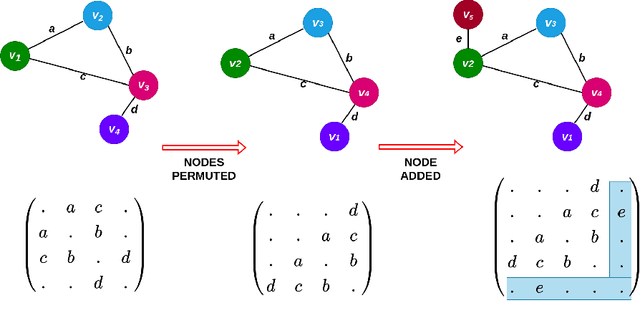
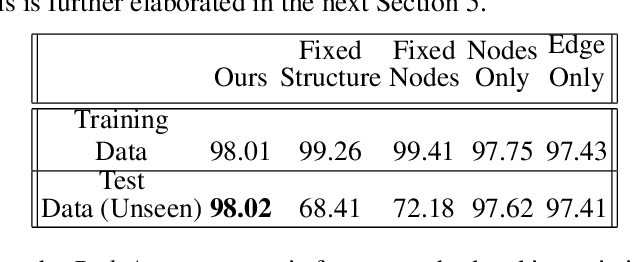
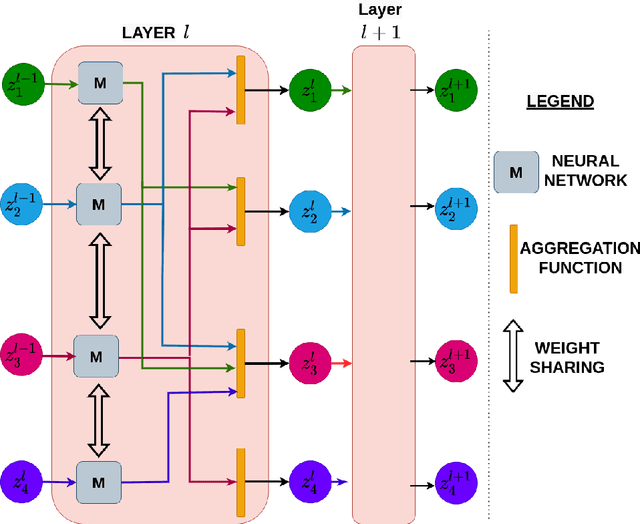
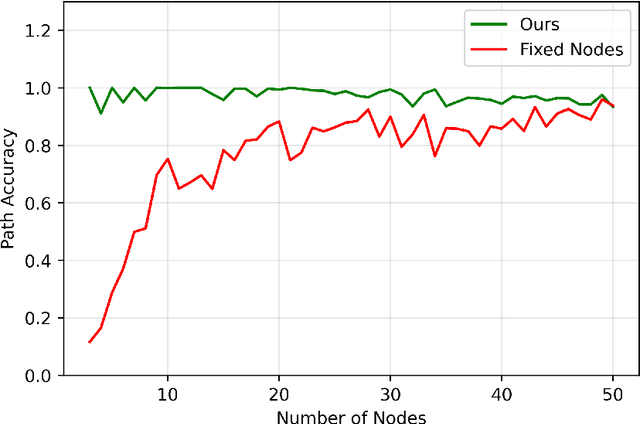
The human brain can be considered to be a graphical structure comprising of tens of billions of biological neurons connected by synapses. It has the remarkable ability to automatically re-route information flow through alternate paths in case some neurons are damaged. Moreover, the brain is capable of retaining information and applying it to similar but completely unseen scenarios. In this paper, we take inspiration from these attributes of the brain, to develop a computational framework to find the optimal low cost path between a source node and a destination node in a generalized graph. We show that our framework is capable of handling unseen graphs at test time. Moreover, it can find alternate optimal paths, when nodes are arbitrarily added or removed during inference, while maintaining a fixed prediction time. Code is available here: https://github.com/hangligit/pathfinding
CHALLENGER: Training with Attribution Maps
May 30, 2022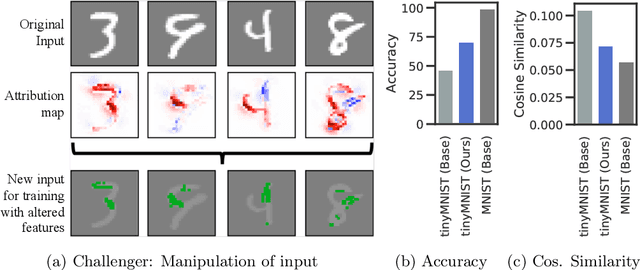


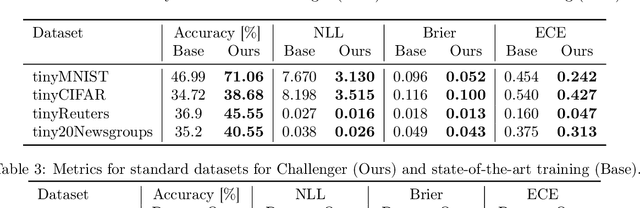
We show that utilizing attribution maps for training neural networks can improve regularization of models and thus increase performance. Regularization is key in deep learning, especially when training complex models on relatively small datasets. In order to understand inner workings of neural networks, attribution methods such as Layer-wise Relevance Propagation (LRP) have been extensively studied, particularly for interpreting the relevance of input features. We introduce Challenger, a module that leverages the explainable power of attribution maps in order to manipulate particularly relevant input patterns. Therefore, exposing and subsequently resolving regions of ambiguity towards separating classes on the ground-truth data manifold, an issue that arises particularly when training models on rather small datasets. Our Challenger module increases model performance through building more diverse filters within the network and can be applied to any input data domain. We demonstrate that our approach results in substantially better classification as well as calibration performance on datasets with only a few samples up to datasets with thousands of samples. In particular, we show that our generic domain-independent approach yields state-of-the-art results in vision, natural language processing and on time series tasks.
VPAIR -- Aerial Visual Place Recognition and Localization in Large-scale Outdoor Environments
May 23, 2022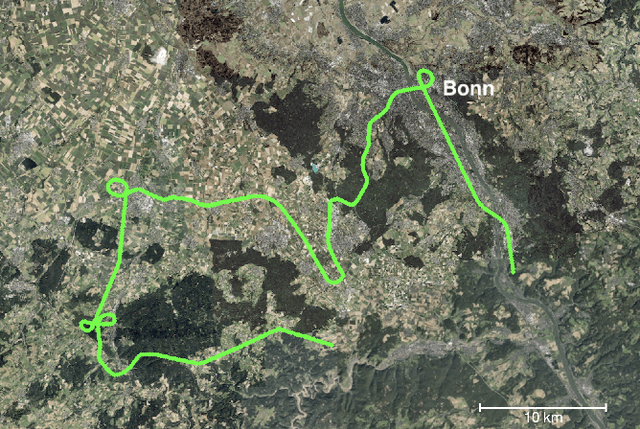
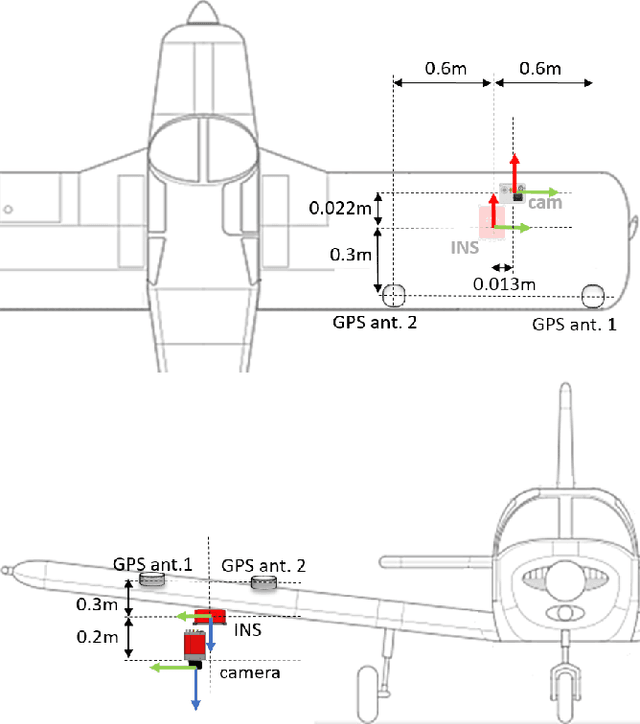

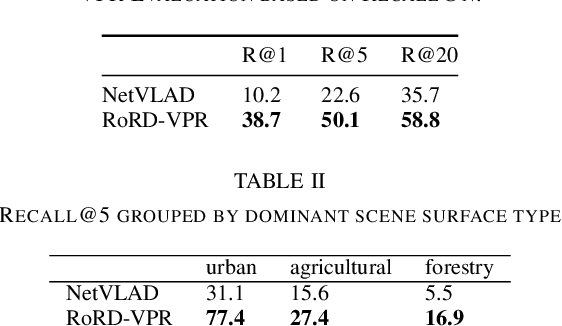
Visual Place Recognition and Visual Localization are essential components in navigation and mapping for autonomous vehicles especially in GNSS-denied navigation scenarios. Recent work has focused on ground or close to ground applications such as self-driving cars or indoor-scenarios and low-altitude drone flights. However, applications such as Urban Air Mobility require operations in large-scale outdoor environments at medium to high altitudes. We present a new dataset named VPAIR. The dataset was recorded on board a light aircraft flying at an altitude of more than 300 meters above ground capturing images with a downwardfacing camera. Each image is paired with a high resolution reference render including dense depth information and 6-DoF reference poses. The dataset covers a more than one hundred kilometers long trajectory over various types of challenging landscapes, e.g. urban, farmland and forests. Experiments on this dataset illustrate the challenges introduced by the change in perspective to a bird's eye view such as in-plane rotations.
A Unified Framework for Implicit Sinkhorn Differentiation
May 13, 2022
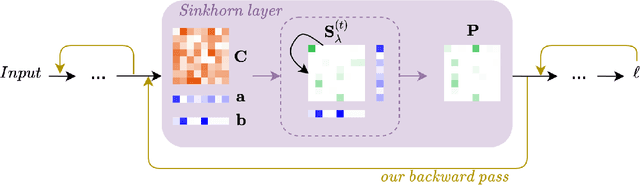
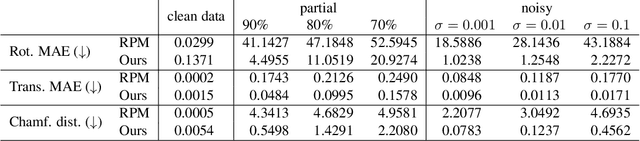
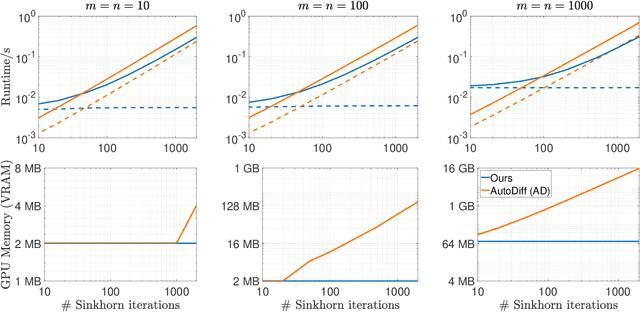
The Sinkhorn operator has recently experienced a surge of popularity in computer vision and related fields. One major reason is its ease of integration into deep learning frameworks. To allow for an efficient training of respective neural networks, we propose an algorithm that obtains analytical gradients of a Sinkhorn layer via implicit differentiation. In comparison to prior work, our framework is based on the most general formulation of the Sinkhorn operator. It allows for any type of loss function, while both the target capacities and cost matrices are differentiated jointly. We further construct error bounds of the resulting algorithm for approximate inputs. Finally, we demonstrate that for a number of applications, simply replacing automatic differentiation with our algorithm directly improves the stability and accuracy of the obtained gradients. Moreover, we show that it is computationally more efficient, particularly when resources like GPU memory are scarce.
Power Bundle Adjustment for Large-Scale 3D Reconstruction
May 03, 2022



We present the design and the implementation of a new expansion type algorithm to solve large-scale bundle adjustment problems. Our approach -- called Power Bundle Adjustment -- is based on the power series expansion of the inverse Schur complement. This initiates a new family of solvers that we call inverse expansion methods. We show with the real-world BAL dataset that the proposed solver challenges the traditional direct and iterative methods. The solution of the normal equation is significantly accelerated, even for reaching a very high accuracy. Last but not least, our solver can also complement a recently presented distributed bundle adjustment framework. We demonstrate that employing the proposed Power Bundle Adjustment as a sub-problem solver greatly improves speed and accuracy of the distributed optimization.
Neural Implicit Representations for Physical Parameter Inference from a Single Video
Apr 29, 2022
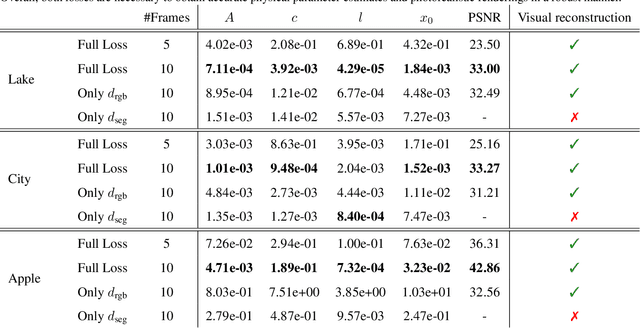
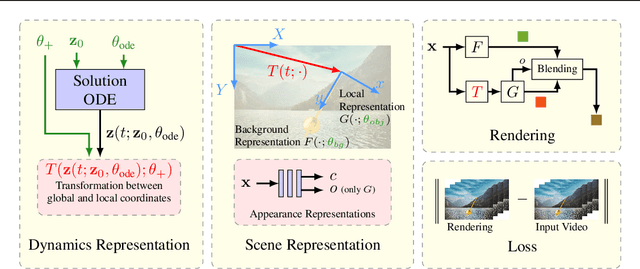

Neural networks have recently been used to analyze diverse physical systems and to identify the underlying dynamics. While existing methods achieve impressive results, they are limited by their strong demand for training data and their weak generalization abilities to out-of-distribution data. To overcome these limitations, in this work we propose to combine neural implicit representations for appearance modeling with neural ordinary differential equations (ODEs) for modelling physical phenomena to obtain a dynamic scene representation that can be identified directly from visual observations. Our proposed model combines several unique advantages: (i) Contrary to existing approaches that require large training datasets, we are able to identify physical parameters from only a single video. (ii) The use of neural implicit representations enables the processing of high-resolution videos and the synthesis of photo-realistic images. (iii) The embedded neural ODE has a known parametric form that allows for the identification of interpretable physical parameters, and (iv) long-term prediction in state space. (v) Furthermore, the photo-realistic rendering of novel scenes with modified physical parameters becomes possible.
A Scalable Combinatorial Solver for Elastic Geometrically Consistent 3D Shape Matching
Apr 27, 2022
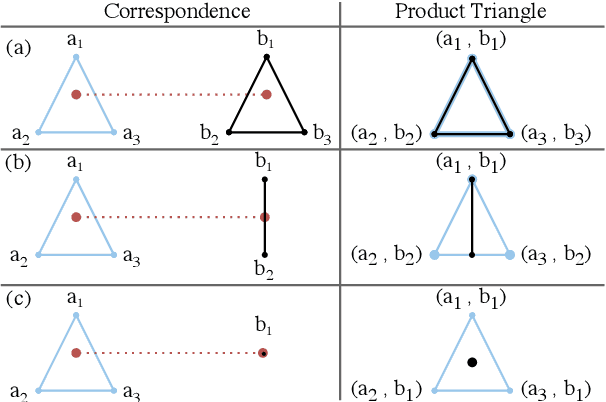
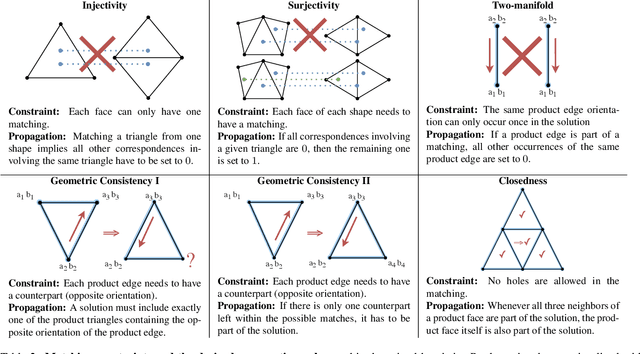
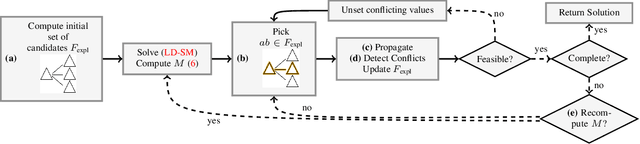
We present a scalable combinatorial algorithm for globally optimizing over the space of geometrically consistent mappings between 3D shapes. We use the mathematically elegant formalism proposed by Windheuser et al. (ICCV 2011) where 3D shape matching was formulated as an integer linear program over the space of orientation-preserving diffeomorphisms. Until now, the resulting formulation had limited practical applicability due to its complicated constraint structure and its large size. We propose a novel primal heuristic coupled with a Lagrange dual problem that is several orders of magnitudes faster compared to previous solvers. This allows us to handle shapes with substantially more triangles than previously solvable. We demonstrate compelling results on diverse datasets, and, even showcase that we can address the challenging setting of matching two partial shapes without availability of complete shapes. Our code is publicly available at http://github.com/paul0noah/sm-comb .