 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatting Makes Perfect -- Chat-based Image Retrieval
May 31, 2023



Chats emerge as an effective user-friendly approach for information retrieval, and are successfully employed in many domains, such as customer service, healthcare, and finance. However, existing image retrieval approaches typically address the case of a single query-to-image round, and the use of chats for image retrieval has been mostly overlooked. In this work, we introduce ChatIR: a chat-based image retrieval system that engages in a conversation with the user to elicit information, in addition to an initial query, in order to clarify the user's search intent. Motivated by the capabilities of today's foundation models, we leverage Large Language Models to generate follow-up questions to an initial image description. These questions form a dialog with the user in order to retrieve the desired image from a large corpus. In this study, we explore the capabilities of such a system tested on a large dataset and reveal that engaging in a dialog yields significant gains in image retrieval. We start by building an evaluation pipeline from an existing manually generated dataset and explore different modules and training strategies for ChatIR. Our comparison includes strong baselines derived from related applications trained with Reinforcement Learning. Our system is capable of retrieving the target image from a pool of 50K images with over 78% success rate after 5 dialogue rounds, compared to 75% when questions are asked by humans, and 64% for a single shot text-to-image retrieval. Extensive evaluations reveal the strong capabilities and examine the limitations of CharIR under different settings.
Break-A-Scene: Extracting Multiple Concepts from a Single Image
May 25, 2023



Text-to-image model personalization aims to introduce a user-provided concept to the model, allowing its synthesis in diverse contexts. However, current methods primarily focus on the case of learning a single concept from multiple images with variations in backgrounds and poses, and struggle when adapted to a different scenario. In this work, we introduce the task of textual scene decomposition: given a single image of a scene that may contain several concepts, we aim to extract a distinct text token for each concept, enabling fine-grained control over the generated scenes. To this end, we propose augmenting the input image with masks that indicate the presence of target concepts. These masks can be provided by the user or generated automatically by a pre-trained segmentation model. We then present a novel two-phase customization process that optimizes a set of dedicated textual embeddings (handles), as well as the model weights, striking a delicate balance between accurately capturing the concepts and avoiding overfitting. We employ a masked diffusion loss to enable handles to generate their assigned concepts, complemented by a novel loss on cross-attention maps to prevent entanglement. We also introduce union-sampling, a training strategy aimed to improve the ability of combining multiple concepts in generated images. We use several automatic metrics to quantitatively compare our method against several baselines, and further affirm the results using a user study. Finally, we showcase several applications of our method. Project page is available at: https://omriavrahami.com/break-a-scene/
Data Roaming and Early Fusion for Composed Image Retrieval
Mar 16, 2023



We study the task of Composed Image Retrieval (CoIR), where a query is composed of two modalities, image and text, extending the user's expression ability. Previous methods typically address this task by a separate encoding of each query modality, followed by late fusion of the extracted features. In this paper, we propose a new approach, Cross-Attention driven Shift Encoder (CASE), employing early fusion between modalities through a cross-attention module with an additional auxiliary task. We show that our method outperforms the existing state-of-the-art, on established benchmarks (FashionIQ and CIRR) by a large margin. However, CoIR datasets are a few orders of magnitude smaller compared to other vision and language (V&L) datasets, and some suffer from serious flaws (e.g., queries with a redundant modality). We address these shortcomings by introducing Large Scale Composed Image Retrieval (LaSCo), a new CoIR dataset x10 times larger than current ones. Pre-training on LaSCo yields a further performance boost. We further suggest a new analysis of CoIR datasets and methods, for detecting modality redundancy or necessity, in queries.
SpaText: Spatio-Textual Representation for Controllable Image Generation
Nov 25, 2022Recent text-to-image diffusion models are able to generate convincing results of unprecedented quality. However, it is nearly impossible to control the shapes of different regions/objects or their layout in a fine-grained fashion. Previous attempts to provide such controls were hindered by their reliance on a fixed set of labels. To this end, we present SpaText - a new method for text-to-image generation using open-vocabulary scene control. In addition to a global text prompt that describes the entire scene, the user provides a segmentation map where each region of interest is annotated by a free-form natural language description. Due to lack of large-scale datasets that have a detailed textual description for each region in the image, we choose to leverage the current large-scale text-to-image datasets and base our approach on a novel CLIP-based spatio-textual representation, and show its effectiveness on two state-of-the-art diffusion models: pixel-based and latent-based. In addition, we show how to extend the classifier-free guidance method in diffusion models to the multi-conditional case and present an alternative accelerated inference algorithm. Finally, we offer several automatic evaluation metrics and use them, in addition to FID scores and a user study, to evaluate our method and show that it achieves state-of-the-art results on image generation with free-form textual scene control.
What's in a Decade? Transforming Faces Through Time
Oct 17, 2022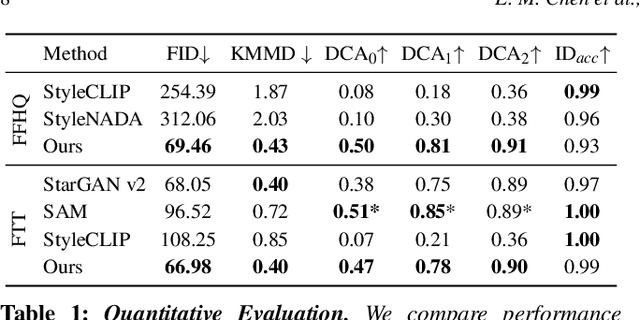

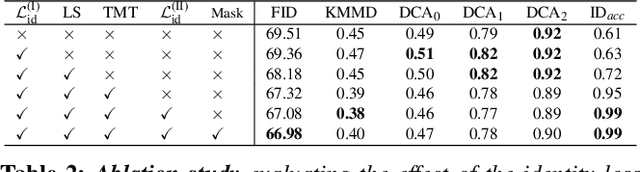
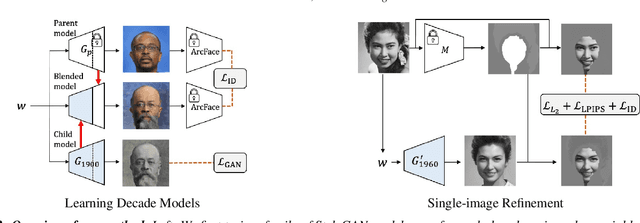
How can one visually characterize people in a decade? In this work, we assemble the Faces Through Time dataset, which contains over a thousand portrait images from each decade, spanning the 1880s to the present day. Using our new dataset, we present a framework for resynthesizing portrait images across time, imagining how a portrait taken during a particular decade might have looked like, had it been taken in other decades. Our framework optimizes a family of per-decade generators that reveal subtle changes that differentiate decade--such as different hairstyles or makeup--while maintaining the identity of the input portrait. Experiments show that our method is more effective in resynthesizing portraits across time compared to state-of-the-art image-to-image translation methods, as well as attribute-based and language-guided portrait editing models. Our code and data will be available at https://facesthroughtime.github.io
Blended Latent Diffusion
Jun 06, 2022
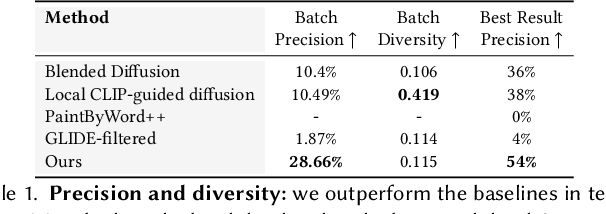

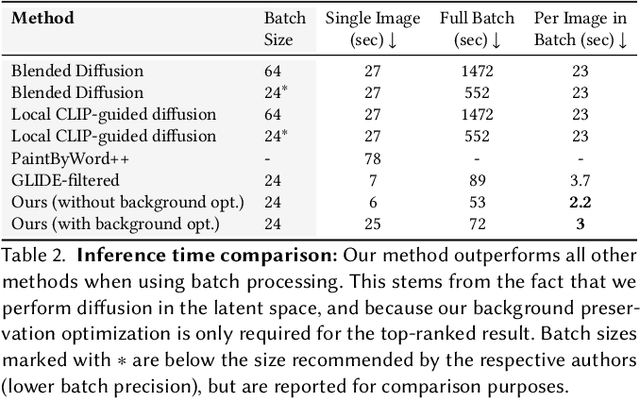
The tremendous progress in neural image generation, coupled with the emergence of seemingly omnipotent vision-language models has finally enabled text-based interfaces for creating and editing images. Handling generic images requires a diverse underlying generative model, hence the latest works utilize diffusion models, which were shown to surpass GANs in terms of diversity. One major drawback of diffusion models, however, is their relatively slow inference time. In this paper, we present an accelerated solution to the task of local text-driven editing of generic images, where the desired edits are confined to a user-provided mask. Our solution leverages a recent text-to-image Latent Diffusion Model (LDM), which speeds up diffusion by operating in a lower-dimensional latent space. We first convert the LDM into a local image editor by incorporating Blended Diffusion into it. Next we propose an optimization-based solution for the inherent inability of this LDM to accurately reconstruct images. Finally, we address the scenario of performing local edits using thin masks. We evaluate our method against the available baselines both qualitatively and quantitatively and demonstrate that in addition to being faster, our method achieves better precision than the baselines while mitigating some of their artifacts. Project page is available at https://omriavrahami.com/blended-latent-diffusion-page/
Shape-Pose Disentanglement using SE(3)-equivariant Vector Neurons
Apr 03, 2022
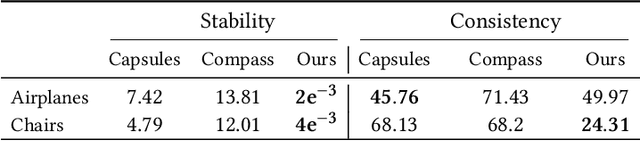
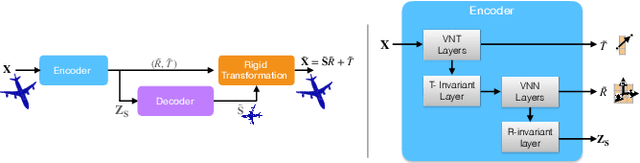
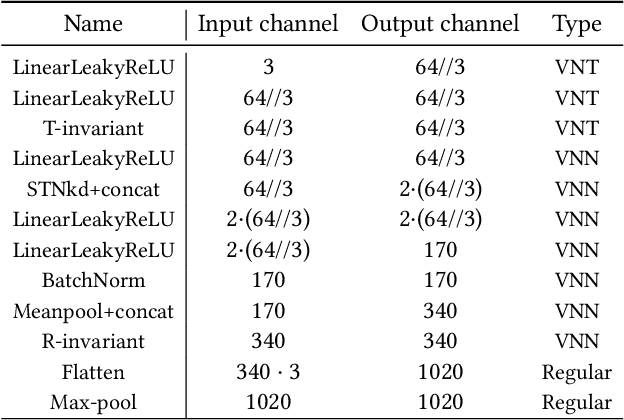
We introduce an unsupervised technique for encoding point clouds into a canonical shape representation, by disentangling shape and pose. Our encoder is stable and consistent, meaning that the shape encoding is purely pose-invariant, while the extracted rotation and translation are able to semantically align different input shapes of the same class to a common canonical pose. Specifically, we design an auto-encoder based on Vector Neuron Networks, a rotation-equivariant neural network, whose layers we extend to provide translation-equivariance in addition to rotation-equivariance only. The resulting encoder produces pose-invariant shape encoding by construction, enabling our approach to focus on learning a consistent canonical pose for a class of objects. Quantitative and qualitative experiments validate the superior stability and consistency of our approach.
Multi-level Latent Space Structuring for Generative Control
Feb 11, 2022



Truncation is widely used in generative models for improving the quality of the generated samples, at the expense of reducing their diversity. We propose to leverage the StyleGAN generative architecture to devise a new truncation technique, based on a decomposition of the latent space into clusters, enabling customized truncation to be performed at multiple semantic levels. We do so by learning to re-generate W-space, the extended intermediate latent space of StyleGAN, using a learnable mixture of Gaussians, while simultaneously training a classifier to identify, for each latent vector, the cluster that it belongs to. The resulting truncation scheme is more faithful to the original untruncated samples and allows a better trade-off between quality and diversity. We compare our method to other truncation approaches for StyleGAN, both qualitatively and quantitatively.
Third Time's the Charm? Image and Video Editing with StyleGAN3
Jan 31, 2022StyleGAN is arguably one of the most intriguing and well-studied generative models, demonstrating impressive performance in image generation, inversion, and manipulation. In this work, we explore the recent StyleGAN3 architecture, compare it to its predecessor, and investigate its unique advantages, as well as drawbacks. In particular, we demonstrate that while StyleGAN3 can be trained on unaligned data, one can still use aligned data for training, without hindering the ability to generate unaligned imagery. Next, our analysis of the disentanglement of the different latent spaces of StyleGAN3 indicates that the commonly used W/W+ spaces are more entangled than their StyleGAN2 counterparts, underscoring the benefits of using the StyleSpace for fine-grained editing. Considering image inversion, we observe that existing encoder-based techniques struggle when trained on unaligned data. We therefore propose an encoding scheme trained solely on aligned data, yet can still invert unaligned images. Finally, we introduce a novel video inversion and editing workflow that leverages the capabilities of a fine-tuned StyleGAN3 generator to reduce texture sticking and expand the field of view of the edited video.
ShapeFormer: Transformer-based Shape Completion via Sparse Representation
Jan 25, 2022
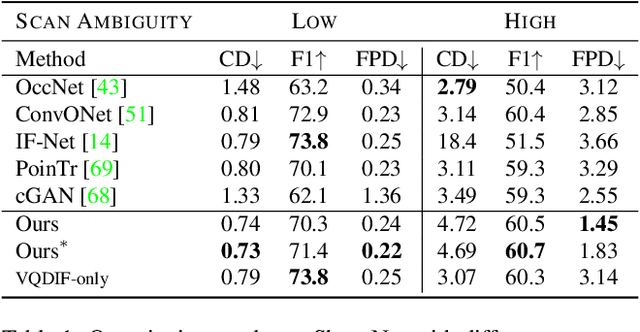
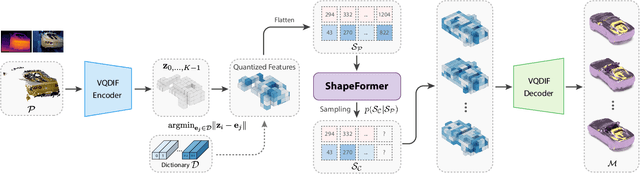
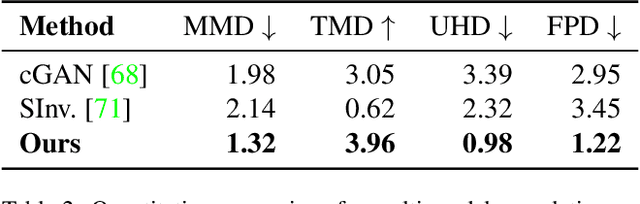
We present ShapeFormer, a transformer-based network that produces a distribution of object completions, conditioned on incomplete, and possibly noisy, point clouds. The resultant distribution can then be sampled to generate likely completions, each exhibiting plausible shape details while being faithful to the input. To facilitate the use of transformers for 3D, we introduce a compact 3D representation, vector quantized deep implicit function, that utilizes spatial sparsity to represent a close approximation of a 3D shape by a short sequence of discrete variables. Experiments demonstrate that ShapeFormer outperforms prior art for shape completion from ambiguous partial inputs in terms of both completion quality and diversity. We also show that our approach effectively handles a variety of shape types, incomplete patterns, and real-world scans.