 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: It's Time to Act on the Risk of Efficient Personalized Text Generation
Feb 10, 2025The recent surge in high-quality open-sourced Generative AI text models (colloquially: LLMs), as well as efficient finetuning techniques, has opened the possibility of creating high-quality personalized models, i.e., models generating text attuned to a specific individual's needs and capable of credibly imitating their writing style by leveraging that person's own data to refine an open-source model. The technology to create such models is accessible to private individuals, and training and running such models can be done cheaply on consumer-grade hardware. These advancements are a huge gain for usability and privacy. This position paper argues, however, that these advancements also introduce new safety risks by making it practically feasible for malicious actors to impersonate specific individuals at scale, for instance for the purpose of phishing emails, based on small amounts of publicly available text. We further argue that these risks are complementary to - and distinct from - the much-discussed risks of other impersonation attacks such as image, voice, or video deepfakes, and are not adequately addressed by the larger research community, or the current generation of open - and closed-source models.
QuEST: Stable Training of LLMs with 1-Bit Weights and Activations
Feb 07, 2025



One approach to reducing the massive costs of large language models (LLMs) is the use of quantized or sparse representations for training or deployment. While post-training compression methods are very popular, the question of obtaining even more accurate compressed models by directly training over such representations, i.e., Quantization-Aware Training (QAT), is still open: for example, a recent study (arXiv:2411.04330v2) put the "optimal" bit-width at which models can be trained using QAT, while staying accuracy-competitive with standard FP16/BF16 precision, at 8-bits weights and activations. We advance this state-of-the-art via a new method called QuEST, which is Pareto-competitive with FP16, i.e., it provides better accuracy at lower model size, while training models with weights and activations in 4-bits or less. Moreover, QuEST allows stable training with 1-bit weights and activations. QuEST achieves this by improving two key aspects of QAT methods: (1) accurate and fast quantization of the (continuous) distributions of weights and activations via Hadamard normalization and MSE-optimal fitting; (2) a new trust gradient estimator based on the idea of explicitly minimizing the error between the noisy gradient computed over quantized states and the "true" (but unknown) full-precision gradient. Experiments on Llama-type architectures show that QuEST induces stable scaling laws across the entire range of hardware-supported precisions, and can be extended to sparse representations. We provide GPU kernel support showing that models produced by QuEST can be executed efficiently. Our code is available at https://github.com/IST-DASLab/QuEST.
Cache Me If You Must: Adaptive Key-Value Quantization for Large Language Models
Jan 31, 2025Efficient real-world deployments of large language models (LLMs) rely on Key-Value (KV) caching for processing and generating long outputs, reducing the need for repetitive computation. For large contexts, Key-Value caches can take up tens of gigabytes of device memory, as they store vector representations for each token and layer. Recent work has shown that the cached vectors can be compressed through quantization, pruning or merging, but these techniques often compromise quality towards higher compression rates. In this work, we aim to improve Key & Value compression by exploiting two observations: 1) the inherent dependencies between keys and values across different layers, and 2) high-compression mechanisms for internal network states. We propose AQUA-KV, an adaptive quantization for Key-Value caches that relies on compact adapters to exploit existing dependencies between Keys and Values, and aims to "optimally" compress the information that cannot be predicted. AQUA-KV significantly improves compression rates, while maintaining high accuracy on state-of-the-art LLM families. On Llama 3.2 LLMs, we achieve near-lossless inference at 2-2.5 bits per value with under $1\%$ relative error in perplexity and LongBench scores. AQUA-KV is one-shot, simple, and efficient: it can be calibrated on a single GPU within 1-6 hours, even for 70B models.
HALO: Hadamard-Assisted Lossless Optimization for Efficient Low-Precision LLM Training and Fine-Tuning
Jan 05, 2025



Quantized training of Large Language Models (LLMs) remains an open challenge, as maintaining accuracy while performing all matrix multiplications in low precision has proven difficult. This is particularly the case when fine-tuning pre-trained models, which often already have large weight and activation outlier values that render quantized optimization difficult. We present HALO, a novel quantization-aware training approach for Transformers that enables accurate and efficient low-precision training by combining 1) strategic placement of Hadamard rotations in both forward and backward passes, to mitigate outliers during the low-precision computation, 2) FSDP integration for low-precision communication, and 3) high-performance kernel support. Our approach ensures that all large matrix multiplications during the forward and backward passes are executed in lower precision. Applied to LLAMA-family models, HALO achieves near-full-precision-equivalent results during fine-tuning on various tasks, while delivering up to 1.31x end-to-end speedup for full fine-tuning on RTX 4090 GPUs. Our method supports both standard and parameter-efficient fine-tuning (PEFT) methods, both backed by efficient kernel implementations. Our results demonstrate the first practical approach to fully quantized LLM fine-tuning that maintains accuracy in FP8 precision, while delivering performance benefits.
Pushing the Limits of Large Language Model Quantization via the Linearity Theorem
Nov 26, 2024



Quantizing large language models has become a standard way to reduce their memory and computational costs. Typically, existing methods focus on breaking down the problem into individual layer-wise sub-problems, and minimizing per-layer error, measured via various metrics. Yet, this approach currently lacks theoretical justification and the metrics employed may be sub-optimal. In this paper, we present a "linearity theorem" establishing a direct relationship between the layer-wise $\ell_2$ reconstruction error and the model perplexity increase due to quantization. This insight enables two novel applications: (1) a simple data-free LLM quantization method using Hadamard rotations and MSE-optimal grids, dubbed HIGGS, which outperforms all prior data-free approaches such as the extremely popular NF4 quantized format, and (2) an optimal solution to the problem of finding non-uniform per-layer quantization levels which match a given compression constraint in the medium-bitwidth regime, obtained by reduction to dynamic programming. On the practical side, we demonstrate improved accuracy-compression trade-offs on Llama-3.1 and 3.2-family models, as well as on Qwen-family models. Further, we show that our method can be efficiently supported in terms of GPU kernels at various batch sizes, advancing both data-free and non-uniform quantization for LLMs.
"Give Me BF16 or Give Me Death"? Accuracy-Performance Trade-Offs in LLM Quantization
Nov 04, 2024



Despite the popularity of large language model (LLM) quantization for inference acceleration, significant uncertainty remains regarding the accuracy-performance trade-offs associated with various quantization formats. We present a comprehensive empirical study of quantized accuracy, evaluating popular quantization formats (FP8, INT8, INT4) across academic benchmarks and real-world tasks, on the entire Llama-3.1 model family. Additionally, our study examines the difference in text generated by quantized models versus their uncompressed counterparts. Beyond benchmarks, we also present a couple of quantization improvements which allowed us to obtain state-of-the-art accuracy recovery results. Our investigation, encompassing over 500,000 individual evaluations, yields several key findings: (1) FP8 weight and activation quantization (W8A8-FP) is lossless across all model scales, (2) INT8 weight and activation quantization (W8A8-INT), when properly tuned, incurs surprisingly low 1-3% accuracy degradation, and (3) INT4 weight-only quantization (W4A16-INT) is competitive with 8-bit integer weight and activation quantization. To address the question of the "best" format for a given deployment environment, we conduct inference performance analysis using the popular open-source vLLM framework on various GPU architectures. We find that W4A16 offers the best cost-efficiency for synchronous deployments, and for asynchronous deployment on mid-tier GPUs. At the same time, W8A8 formats excel in asynchronous "continuous batching" deployment of mid- and large-size models on high-end GPUs. Our results provide a set of practical guidelines for deploying quantized LLMs across scales and performance requirements.
LDAdam: Adaptive Optimization from Low-Dimensional Gradient Statistics
Oct 21, 2024We introduce LDAdam, a memory-efficient optimizer for training large models, that performs adaptive optimization steps within lower dimensional subspaces, while consistently exploring the full parameter space during training. This strategy keeps the optimizer's memory footprint to a fraction of the model size. LDAdam relies on a new projection-aware update rule for the optimizer states that allows for transitioning between subspaces, i.e., estimation of the statistics of the projected gradients. To mitigate the errors due to low-rank projection, LDAdam integrates a new generalized error feedback mechanism, which explicitly accounts for both gradient and optimizer state compression. We prove the convergence of LDAdam under standard assumptions, and show that LDAdam allows for accurate and efficient fine-tuning and pre-training of language models.
EvoPress: Towards Optimal Dynamic Model Compression via Evolutionary Search
Oct 18, 2024



The high computational costs of large language models (LLMs) have led to a flurry of research on LLM compression, via methods such as quantization, sparsification, or structured pruning. A new frontier in this area is given by \emph{dynamic, non-uniform} compression methods, which adjust the compression levels (e.g., sparsity) per-block or even per-layer in order to minimize accuracy loss, while guaranteeing a global compression threshold. Yet, current methods rely on heuristics for identifying the "importance" of a given layer towards the loss, based on assumptions such as \emph{error monotonicity}, i.e. that the end-to-end model compression error is proportional to the sum of layer-wise errors. In this paper, we revisit this area, and propose a new and general approach for dynamic compression that is provably optimal in a given input range. We begin from the motivating observation that, in general, \emph{error monotonicity does not hold for LLMs}: compressed models with lower sum of per-layer errors can perform \emph{worse} than models with higher error sums. To address this, we propose a new general evolutionary framework for dynamic LLM compression called EvoPress, which has provable convergence, and low sample and evaluation complexity. We show that these theoretical guarantees lead to highly competitive practical performance for dynamic compression of Llama, Mistral and Phi models. Via EvoPress, we set new state-of-the-art results across all compression approaches: structural pruning (block/layer dropping), unstructured sparsity, as well as quantization with dynamic bitwidths. Our code is available at https://github.com/IST-DASLab/EvoPress.
Scalable Mechanistic Neural Networks
Oct 08, 2024



We propose Scalable Mechanistic Neural Network (S-MNN), an enhanced neural network framework designed for scientific machine learning applications involving long temporal sequences. By reformulating the original Mechanistic Neural Network (MNN) (Pervez et al., 2024), we reduce the computational time and space complexities from cubic and quadratic with respect to the sequence length, respectively, to linear. This significant improvement enables efficient modeling of long-term dynamics without sacrificing accuracy or interpretability. Extensive experiments demonstrate that S-MNN matches the original MNN in precision while substantially reducing computational resources. Consequently, S-MNN can drop-in replace the original MNN in applications, providing a practical and efficient tool for integrating mechanistic bottlenecks into neural network models of complex dynamical systems.
Accurate Compression of Text-to-Image Diffusion Models via Vector Quantization
Aug 31, 2024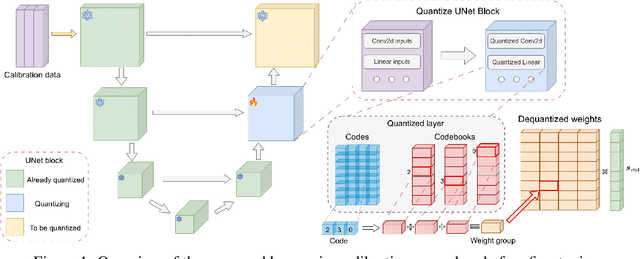
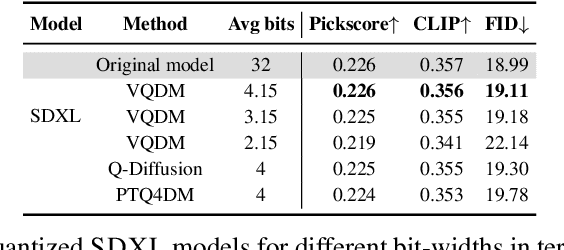


Text-to-image diffusion models have emerged as a powerful framework for high-quality image generation given textual prompts. Their success has driven the rapid development of production-grade diffusion models that consistently increase in size and already contain billions of parameters. As a result, state-of-the-art text-to-image models are becoming less accessible in practice, especially in resource-limited environments. Post-training quantization (PTQ) tackles this issue by compressing the pretrained model weights into lower-bit representations. Recent diffusion quantization techniques primarily rely on uniform scalar quantization, providing decent performance for the models compressed to 4 bits. This work demonstrates that more versatile vector quantization (VQ) may achieve higher compression rates for large-scale text-to-image diffusion models. Specifically, we tailor vector-based PTQ methods to recent billion-scale text-to-image models (SDXL and SDXL-Turbo), and show that the diffusion models of 2B+ parameters compressed to around 3 bits using VQ exhibit the similar image quality and textual alignment as previous 4-bit compression techniques.