 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Electron-Ionization Mass Spectrometry using Neural Networks
Nov 21, 2018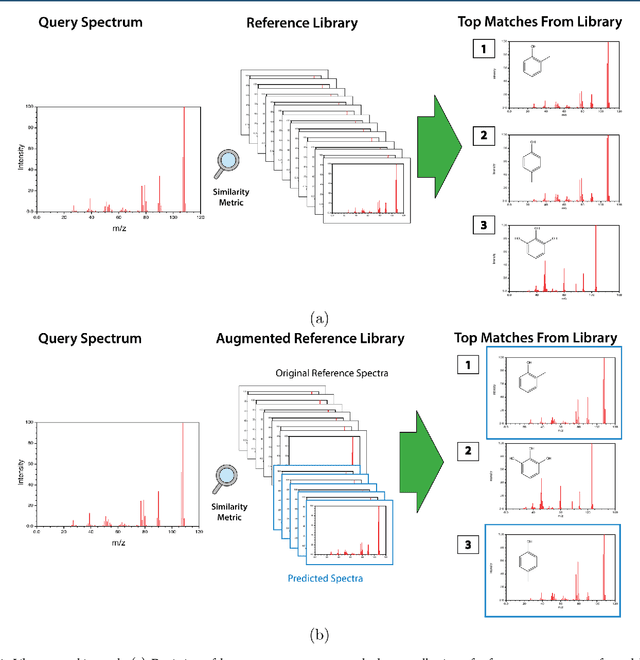
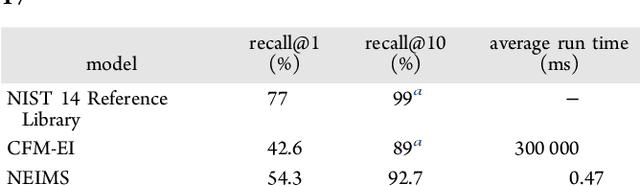
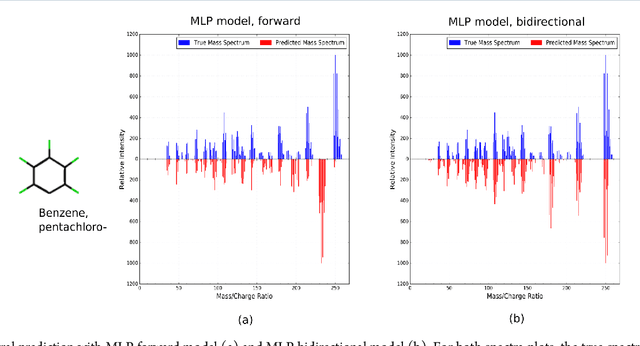
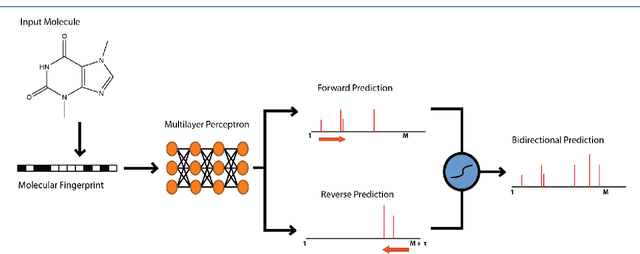
When confronted with a substance of unknown identity, researchers often perform mass spectrometry on the sample and compare the observed spectrum to a library of previously-collected spectra to identify the molecule. While popular, this approach will fail to identify molecules that are not in the existing library. In response, we propose to improve the library's coverage by augmenting it with synthetic spectra that are predicted using machine learning. We contribute a lightweight neural network model that quickly predicts mass spectra for small molecules. Achieving high accuracy predictions requires a novel neural network architecture that is designed to capture typical fragmentation patterns from electron ionization. We analyze the effects of our modeling innovations on library matching performance and compare our models to prior machine learning-based work on spectrum prediction.
No Classification without Representation: Assessing Geodiversity Issues in Open Data Sets for the Developing World
Nov 22, 2017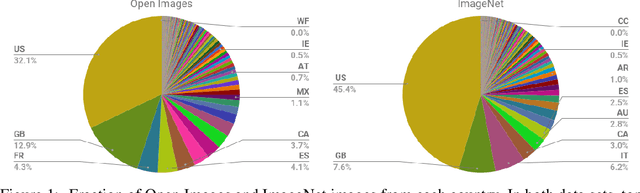
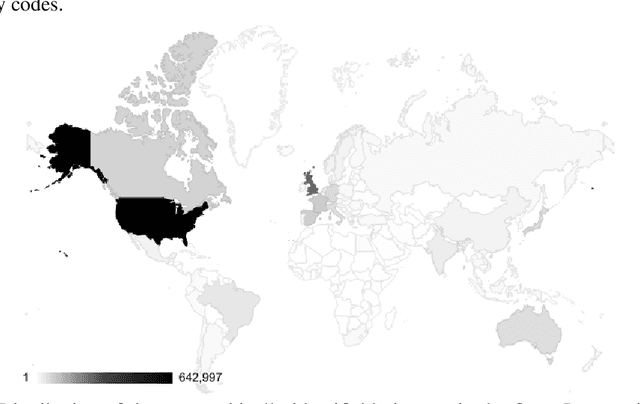
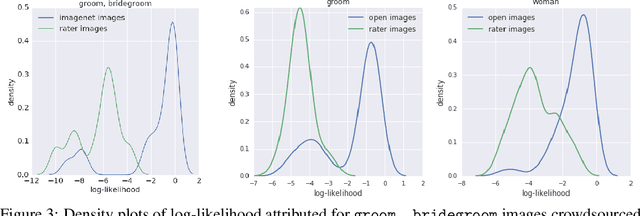
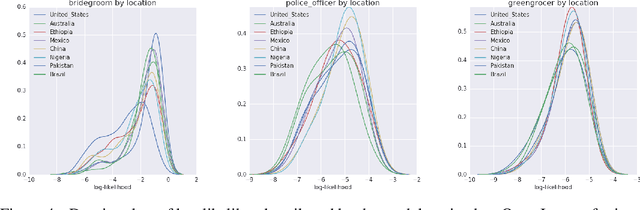
Modern machine learning systems such as image classifiers rely heavily on large scale data sets for training. Such data sets are costly to create, thus in practice a small number of freely available, open source data sets are widely used. We suggest that examining the geo-diversity of open data sets is critical before adopting a data set for use cases in the developing world. We analyze two large, publicly available image data sets to assess geo-diversity and find that these data sets appear to exhibit an observable amerocentric and eurocentric representation bias. Further, we analyze classifiers trained on these data sets to assess the impact of these training distributions and find strong differences in the relative performance on images from different locales. These results emphasize the need to ensure geo-representation when constructing data sets for use in the developing world.
Direct-Manipulation Visualization of Deep Networks
Aug 12, 2017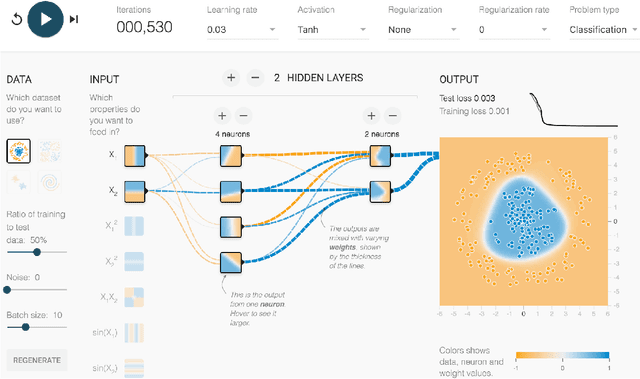
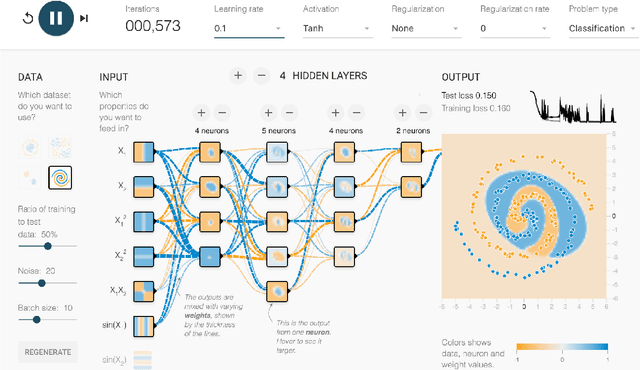
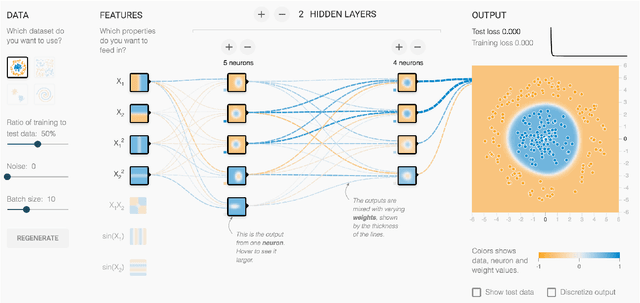
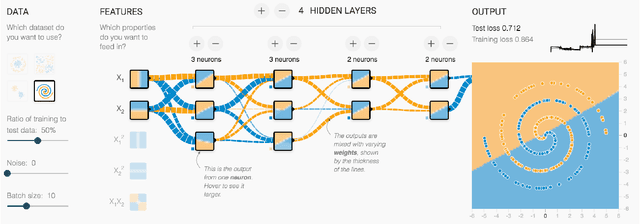
The recent successes of deep learning have led to a wave of interest from non-experts. Gaining an understanding of this technology, however, is difficult. While the theory is important, it is also helpful for novices to develop an intuitive feel for the effect of different hyperparameters and structural variations. We describe TensorFlow Playground, an interactive, open sourced visualization that allows users to experiment via direct manipulation rather than coding, enabling them to quickly build an intuition about neural nets.
AutoMOS: Learning a non-intrusive assessor of naturalness-of-speech
Nov 28, 2016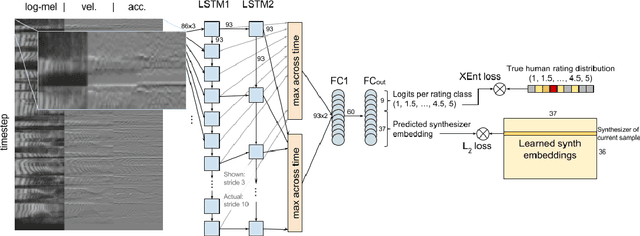
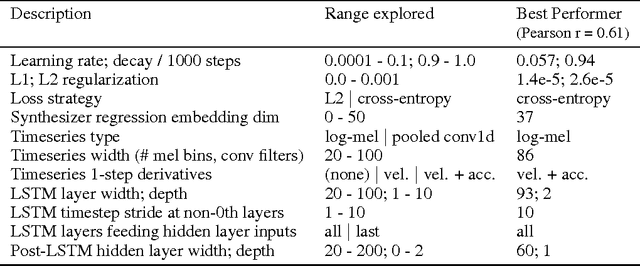
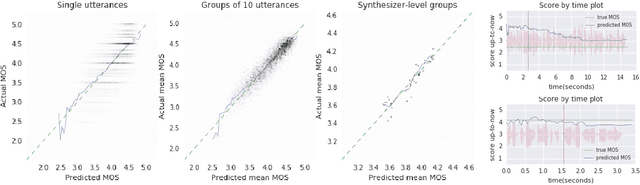
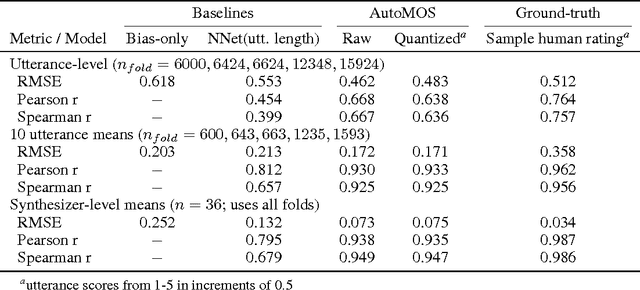
Developers of text-to-speech synthesizers (TTS) often make use of human raters to assess the quality of synthesized speech. We demonstrate that we can model human raters' mean opinion scores (MOS) of synthesized speech using a deep recurrent neural network whose inputs consist solely of a raw waveform. Our best models provide utterance-level estimates of MOS only moderately inferior to sampled human ratings, as shown by Pearson and Spearman correlations. When multiple utterances are scored and averaged, a scenario common in synthesizer quality assessment, AutoMOS achieves correlations approaching those of human raters. The AutoMOS model has a number of applications, such as the ability to explore the parameter space of a speech synthesizer without requiring a human-in-the-loop.
Large-Scale Learning with Less RAM via Randomization
Mar 19, 2013

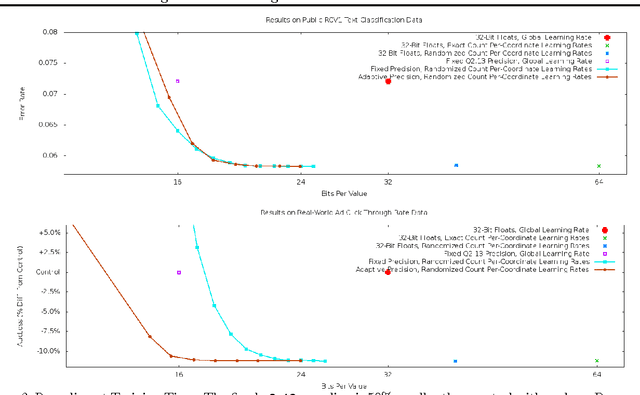
We reduce the memory footprint of popular large-scale online learning methods by projecting our weight vector onto a coarse discrete set using randomized rounding. Compared to standard 32-bit float encodings, this reduces RAM usage by more than 50% during training and by up to 95% when making predictions from a fixed model, with almost no loss in accuracy. We also show that randomized counting can be used to implement per-coordinate learning rates, improving model quality with little additional RAM. We prove these memory-saving methods achieve regret guarantees similar to their exact variants. Empirical evaluation confirms excellent performance, dominating standard approaches across memory versus accuracy tradeoffs.