 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Pretrained Vision-Language Foundational Models to Medical Imaging Domains
Oct 09, 2022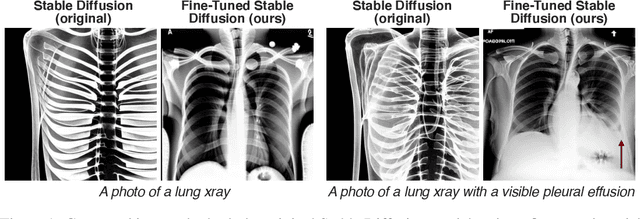
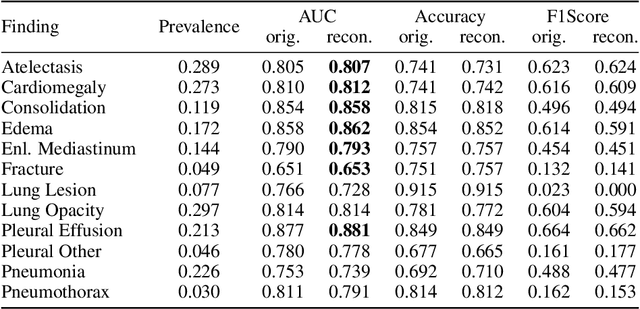
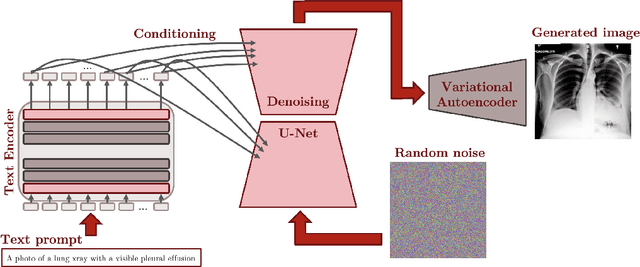
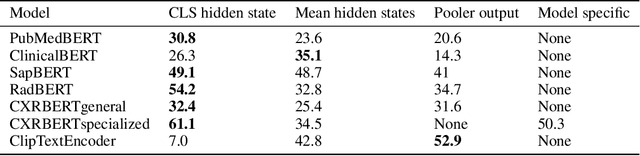
Multi-modal foundation models are typically trained on millions of pairs of natural images and text captions, frequently obtained through web-crawling approaches. Although such models depict excellent generative capabilities, they do not typically generalize well to specific domains such as medical images that have fundamentally shifted distributions compared to natural images. Building generative models for medical images that faithfully depict clinical context may help alleviate the paucity of healthcare datasets. Thus, in this study, we seek to research and expand the representational capabilities of large pretrained foundation models to medical concepts, specifically for leveraging the Stable Diffusion model to generate domain specific images found in medical imaging. We explore the sub-components of the Stable Diffusion pipeline (the variational autoencoder, the U-Net and the text-encoder) to fine-tune the model to generate medical images. We benchmark the efficacy of these efforts using quantitative image quality metrics and qualitative radiologist-driven evaluations that accurately represent the clinical content of conditional text prompts. Our best-performing model improves upon the stable diffusion baseline and can be conditioned to insert a realistic-looking abnormality on a synthetic radiology image, while maintaining a 95% accuracy on a classifier trained to detect the abnormality.
RadGraph: Extracting Clinical Entities and Relations from Radiology Reports
Jun 28, 2021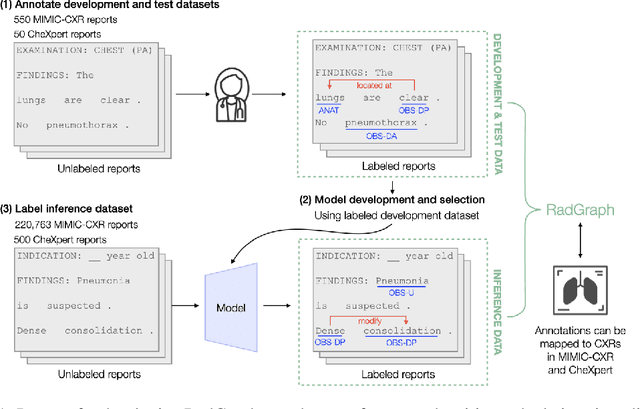
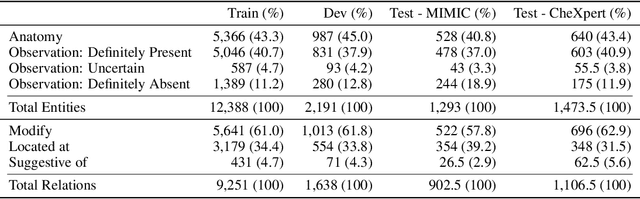
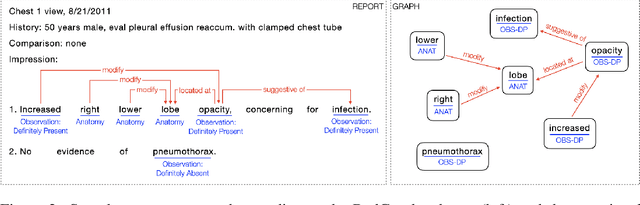
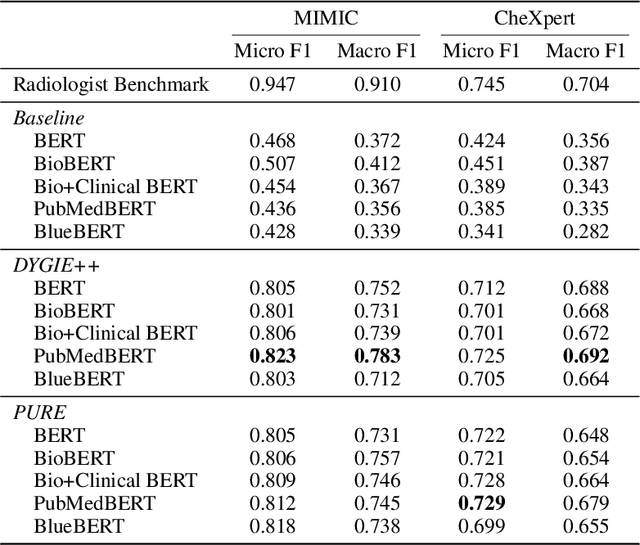
Extracting structured clinical information from free-text radiology reports can enable the use of radiology report information for a variety of critical healthcare applications. In our work, we present RadGraph, a dataset of entities and relations in full-text chest X-ray radiology reports based on a novel information extraction schema we designed to structure radiology reports. We release a development dataset, which contains board-certified radiologist annotations for 500 radiology reports from the MIMIC-CXR dataset (14,579 entities and 10,889 relations), and a test dataset, which contains two independent sets of board-certified radiologist annotations for 100 radiology reports split equally across the MIMIC-CXR and CheXpert datasets. Using these datasets, we train and test a deep learning model, RadGraph Benchmark, that achieves a micro F1 of 0.82 and 0.73 on relation extraction on the MIMIC-CXR and CheXpert test sets respectively. Additionally, we release an inference dataset, which contains annotations automatically generated by RadGraph Benchmark across 220,763 MIMIC-CXR reports (around 6 million entities and 4 million relations) and 500 CheXpert reports (13,783 entities and 9,908 relations) with mappings to associated chest radiographs. Our freely available dataset can facilitate a wide range of research in medical natural language processing, as well as computer vision and multi-modal learning when linked to chest radiographs.
Simulating time to event prediction with spatiotemporal echocardiography deep learning
Mar 03, 2021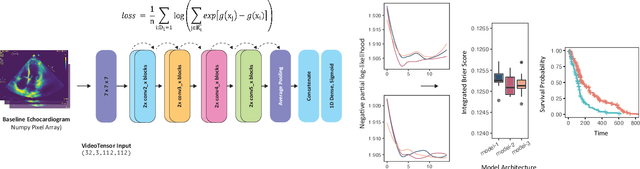
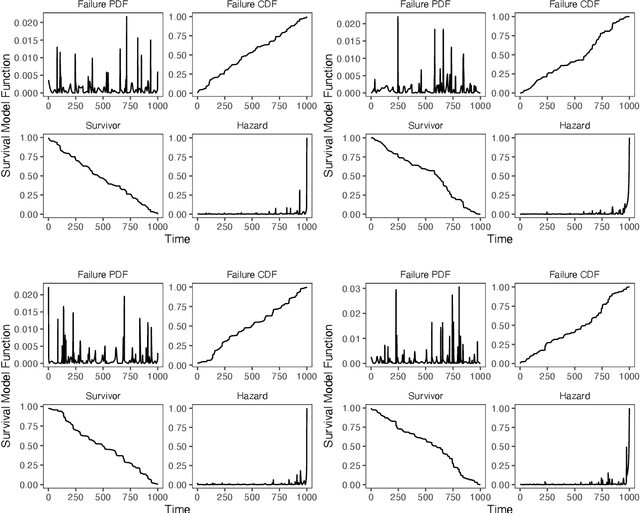
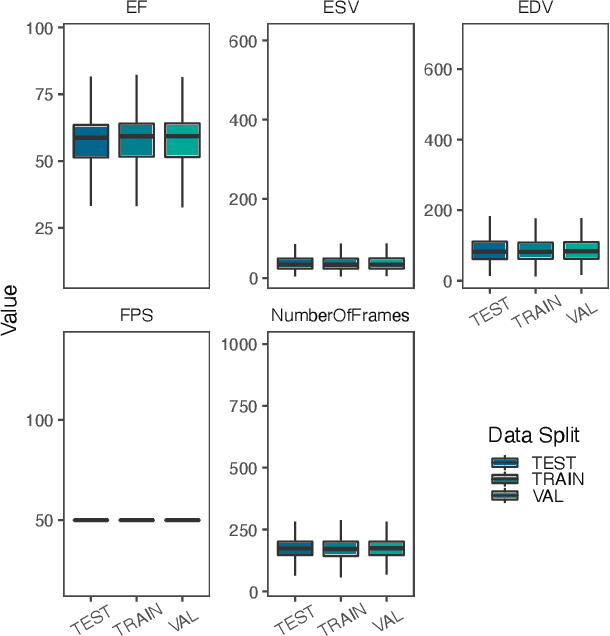
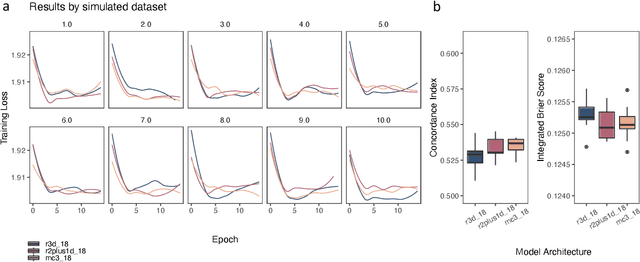
Integrating methods for time-to-event prediction with diagnostic imaging modalities is of considerable interest, as accurate estimates of survival requires accounting for censoring of individuals within the observation period. New methods for time-to-event prediction have been developed by extending the cox-proportional hazards model with neural networks. In this paper, to explore the feasibility of these methods when applied to deep learning with echocardiography videos, we utilize the Stanford EchoNet-Dynamic dataset with over 10,000 echocardiograms, and generate simulated survival datasets based on the expert annotated ejection fraction readings. By training on just the simulated survival outcomes, we show that spatiotemporal convolutional neural networks yield accurate survival estimates.
Medical Imaging and Machine Learning
Mar 02, 2021

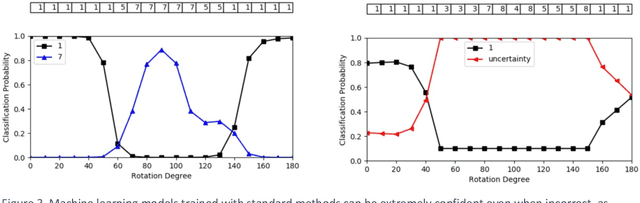
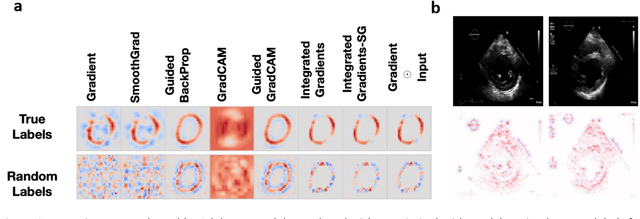
Advances in computing power, deep learning architectures, and expert labelled datasets have spurred the development of medical imaging artificial intelligence systems that rival clinical experts in a variety of scenarios. The National Institutes of Health in 2018 identified key focus areas for the future of artificial intelligence in medical imaging, creating a foundational roadmap for research in image acquisition, algorithms, data standardization, and translatable clinical decision support systems. Among the key issues raised in the report: data availability, need for novel computing architectures and explainable AI algorithms, are still relevant despite the tremendous progress made over the past few years alone. Furthermore, translational goals of data sharing, validation of performance for regulatory approval, generalizability and mitigation of unintended bias must be accounted for early in the development process. In this perspective paper we explore challenges unique to high dimensional clinical imaging data, in addition to highlighting some of the technical and ethical considerations in developing high-dimensional, multi-modality, machine learning systems for clinical decision support.
Improving Factual Completeness and Consistency of Image-to-Text Radiology Report Generation
Oct 20, 2020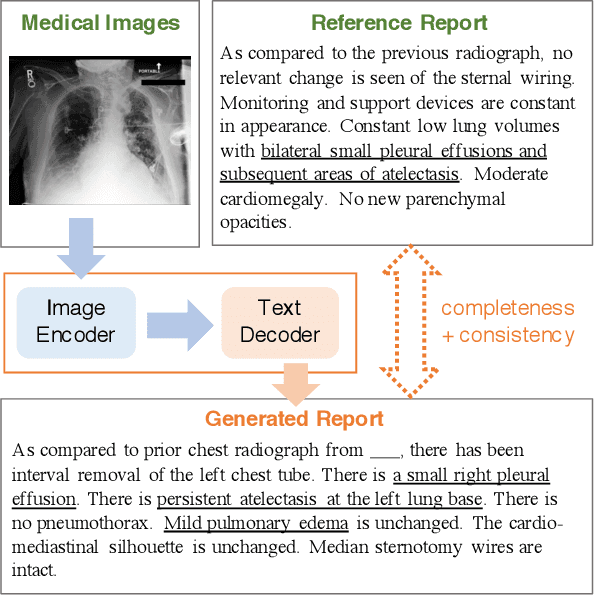

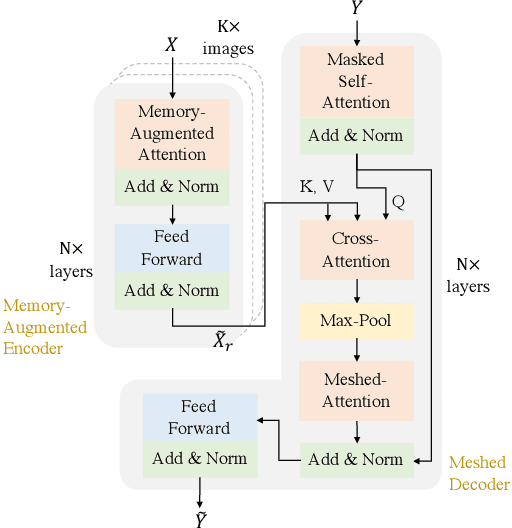
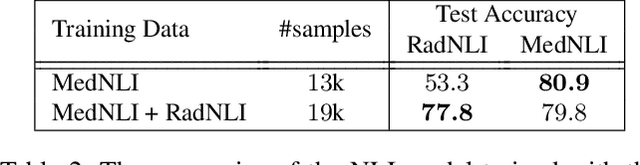
Neural image-to-text radiology report generation systems offer the potential to accelerate clinical processes by saving radiologists from the repetitive labor of drafting radiology reports and preventing medical errors. However, existing report generation systems, despite achieving high performances on natural language generation metrics such as CIDEr or BLEU, still suffer from incomplete and inconsistent generations, rendering these systems unusable in practice. In this work, we aim to overcome this problem by proposing two new metrics that encourage the factual completeness and consistency of generated radiology reports. The first metric, the Exact Entity Match score, evaluates a generation by its coverage of radiology domain entities against the references. The second metric, the Entailing Entity Match score, augments the first metric by introducing a natural language inference model into the entity match process to encourage consistent generations that can be entailed from the references. To achieve this, we also developed an in-domain NLI model via weak supervision to improve its performance on radiology text. We further propose a report generation system that optimizes these two new metrics via reinforcement learning. On two open radiology report datasets, our system not only achieves the best performance on these two metrics compared to baselines, but also leads to as much as +2.0 improvement on the F1 score of a clinical finding metric. We show via analysis and examples that our system leads to generations that are more complete and consistent compared to the baselines.
Contrastive Learning of Medical Visual Representations from Paired Images and Text
Oct 02, 2020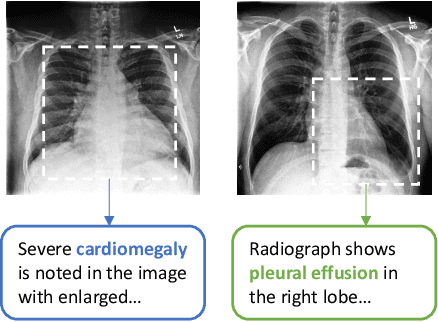
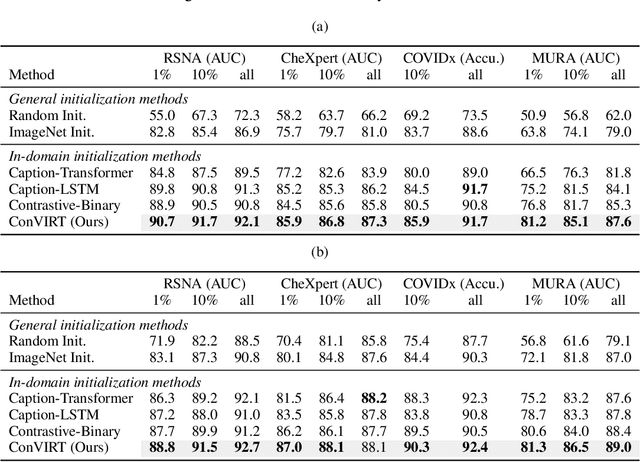
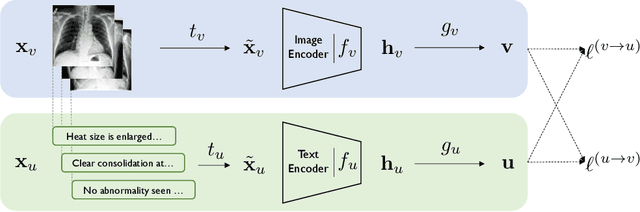
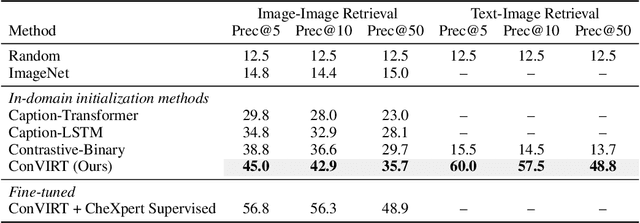
Learning visual representations of medical images is core to medical image understanding but its progress has been held back by the small size of hand-labeled datasets. Existing work commonly relies on transferring weights from ImageNet pretraining, which is suboptimal due to drastically different image characteristics, or rule-based label extraction from the textual report data paired with medical images, which is inaccurate and hard to generalize. We propose an alternative unsupervised strategy to learn medical visual representations directly from the naturally occurring pairing of images and textual data. Our method of pretraining medical image encoders with the paired text data via a bidirectional contrastive objective between the two modalities is domain-agnostic, and requires no additional expert input. We test our method by transferring our pretrained weights to 4 medical image classification tasks and 2 zero-shot retrieval tasks, and show that our method leads to image representations that considerably outperform strong baselines in most settings. Notably, in all 4 classification tasks, our method requires only 10% as much labeled training data as an ImageNet initialized counterpart to achieve better or comparable performance, demonstrating superior data efficiency.
SCREENet: A Multi-view Deep Convolutional Neural Network for Classification of High-resolution Synthetic Mammographic Screening Scans
Sep 25, 2020
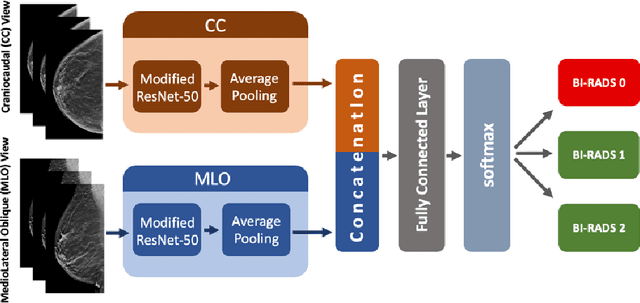
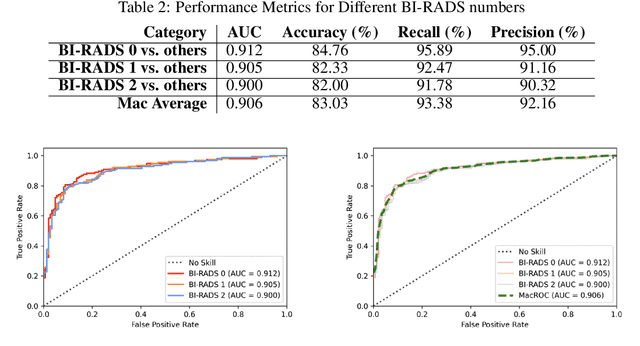
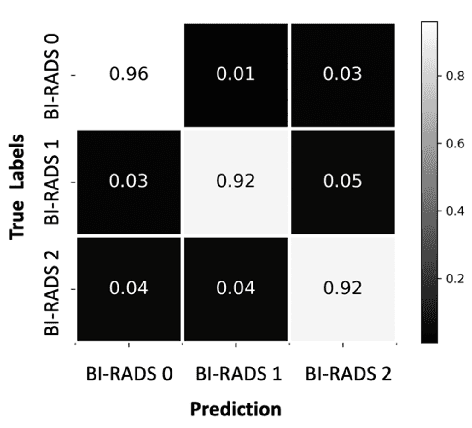
Purpose: To develop and evaluate the accuracy of a multi-view deep learning approach to the analysis of high-resolution synthetic mammograms from digital breast tomosynthesis screening cases, and to assess the effect on accuracy of image resolution and training set size. Materials and Methods: In a retrospective study, 21,264 screening digital breast tomosynthesis (DBT) exams obtained at our institution were collected along with associated radiology reports. The 2D synthetic mammographic images from these exams, with varying resolutions and data set sizes, were used to train a multi-view deep convolutional neural network (MV-CNN) to classify screening images into BI-RADS classes (BI-RADS 0, 1 and 2) before evaluation on a held-out set of exams. Results: Area under the receiver operating characteristic curve (AUC) for BI-RADS 0 vs non-BI-RADS 0 class was 0.912 for the MV-CNN trained on the full dataset. The model obtained accuracy of 84.8%, recall of 95.9% and precision of 95.0%. This AUC value decreased when the same model was trained with 50% and 25% of images (AUC = 0.877, P=0.010 and 0.834, P=0.009 respectively). Also, the performance dropped when the same model was trained using images that were under-sampled by 1/2 and 1/4 (AUC = 0.870, P=0.011 and 0.813, P=0.009 respectively). Conclusion: This deep learning model classified high-resolution synthetic mammography scans into normal vs needing further workup using tens of thousands of high-resolution images. Smaller training data sets and lower resolution images both caused significant decrease in performance.
Biomedical and Clinical English Model Packages in the Stanza Python NLP Library
Jul 29, 2020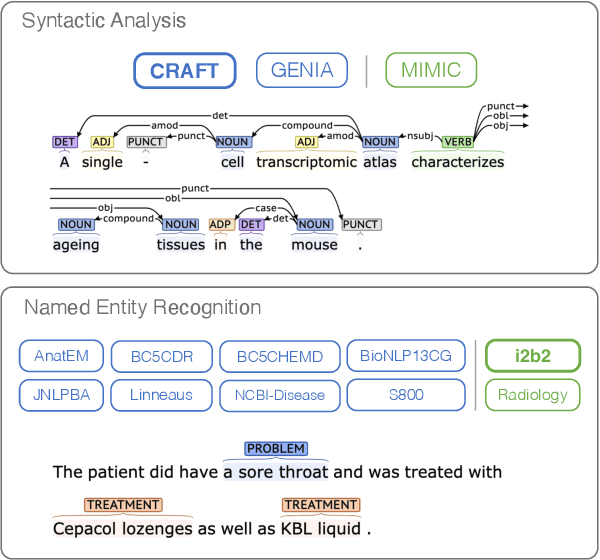
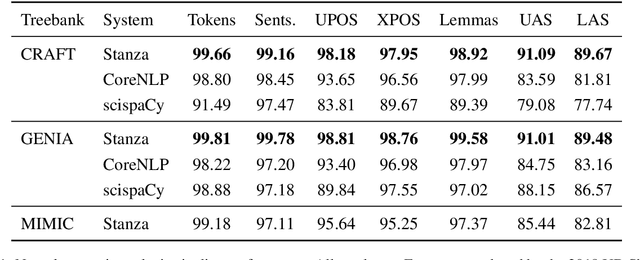
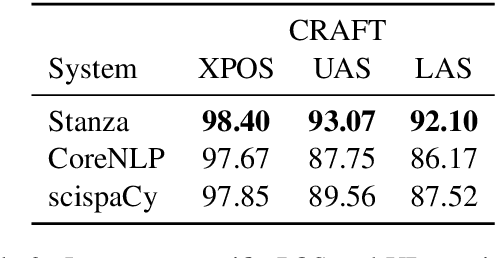
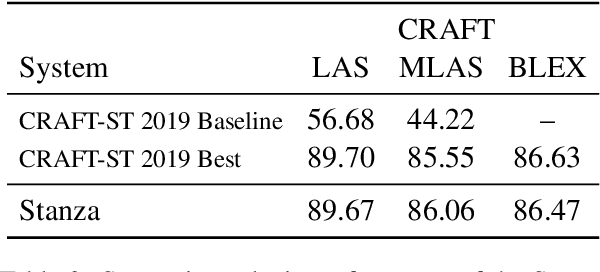
We introduce biomedical and clinical English model packages for the Stanza Python NLP library. These packages offer accurate syntactic analysis and named entity recognition capabilities for biomedical and clinical text, by combining Stanza's fully neural architecture with a wide variety of open datasets as well as large-scale unsupervised biomedical and clinical text data. We show via extensive experiments that our packages achieve syntactic analysis and named entity recognition performance that is on par with or surpasses state-of-the-art results. We further show that these models do not compromise speed compared to existing toolkits when GPU acceleration is available, and are made easy to download and use with Stanza's Python interface. A demonstration of our packages is available at: http://stanza.run/bio.
Optimizing the Factual Correctness of a Summary: A Study of Summarizing Radiology Reports
Nov 08, 2019
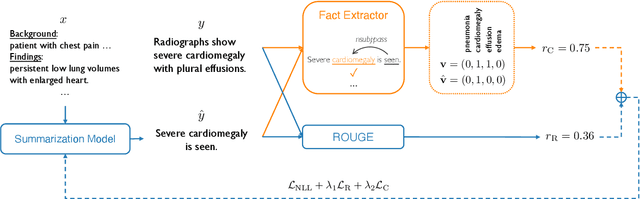
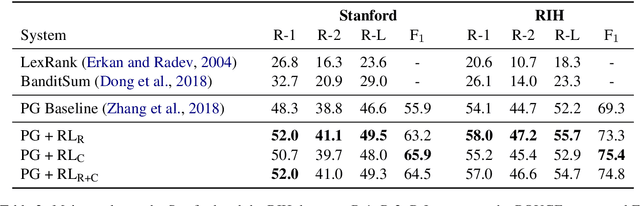
Neural abstractive summarization models are able to generate summaries which have high overlap with human references. However, existing models are not optimized for factual correctness, a critical metric in real-world applications. In this work, we develop a general framework where we evaluate the factual correctness of a generated summary by fact-checking it against its reference using an information extraction module. We further propose a training strategy which optimizes a neural summarization model with a factual correctness reward via reinforcement learning. We apply the proposed method to the summarization of radiology reports, where factual correctness is a key requirement. On two separate datasets collected from real hospitals, we show via both automatic and human evaluation that the proposed approach substantially improves the factual correctness and overall quality of outputs over a competitive neural summarization system.
Plexus Convolutional Neural Network (PlexusNet): A novel neural network architecture for histologic image analysis
Aug 24, 2019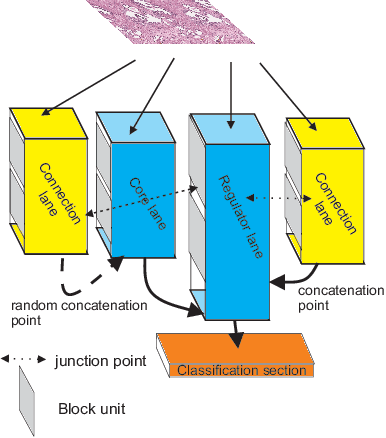
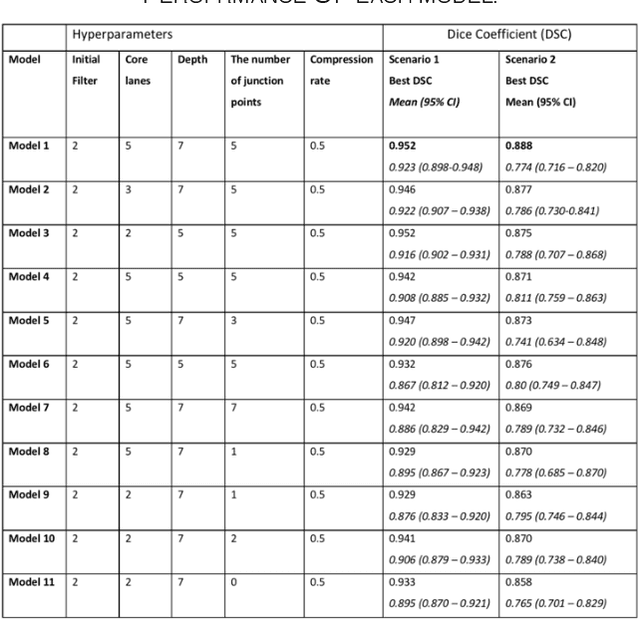
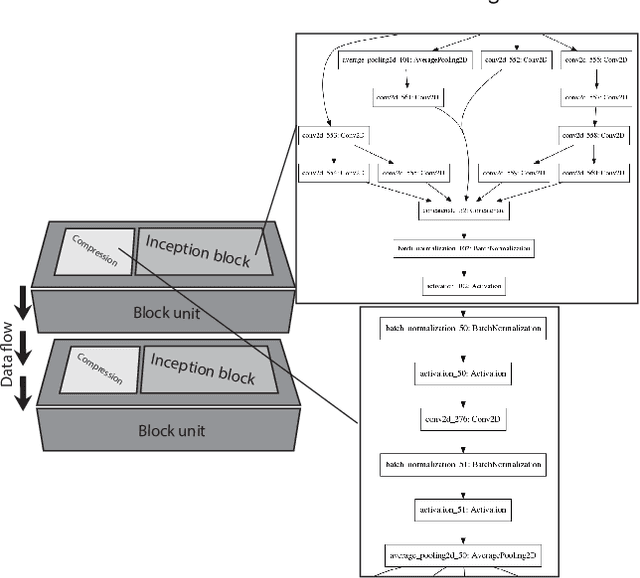
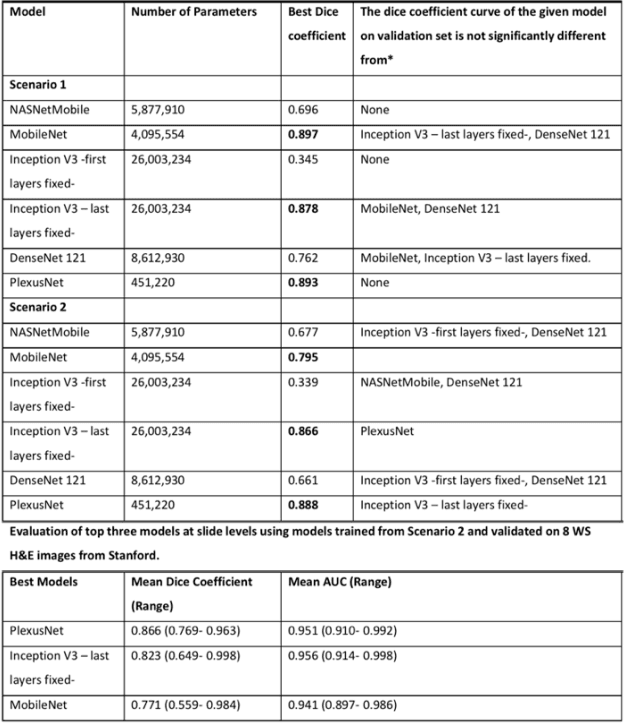
Different convolutional neural network (CNN) models have been tested for their application in histologic imaging analyses. However, these models are prone to overfitting due to their large parameter capacity, requiring more data and expensive computational resources for model training. Given these limitations, we developed and tested PlexusNet for histologic evaluation using a single GPU by a batch dimension of 16x512x512x3. We utilized 62 Hematoxylin and eosin stain (H&E) annotated histological images of radical prostatectomy cases from TCGA-PRAD and Stanford University, and 24 H&E whole-slide images with hepatocellular carcinoma from TCGA-LIHC diagnostic histology images. Base models were DenseNet, Inception V3, and MobileNet and compared with PlexusNet. The dice coefficient (DSC) was evaluated for each model. PlexusNet delivered comparable classification performance (DSC at patch level: 0.89) for H&E whole-slice images in distinguishing prostate cancer from normal tissues. The parameter capacity of PlexusNet is 9 times smaller than MobileNet or 58 times smaller than Inception V3, respectively. Similar findings were observed in distinguishing hepatocellular carcinoma from non-cancerous liver histologies (DSC at patch level: 0.85). As conclusion, PlexusNet represents a novel model architecture for histological image analysis that achieves classification performance comparable to the base models while providing orders-of-magnitude memory savings.