 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Linear Estimation with Penalized Estimators: an Application to Reinforcement Learning
Jun 27, 2012Motivated by value function estimation in reinforcement learning, we study statistical linear inverse problems, i.e., problems where the coefficients of a linear system to be solved are observed in noise. We consider penalized estimators, where performance is evaluated using a matrix-weighted two-norm of the defect of the estimator measured with respect to the true, unknown coefficients. Two objective functions are considered depending whether the error of the defect measured with respect to the noisy coefficients is squared or unsquared. We propose simple, yet novel and theoretically well-founded data-dependent choices for the regularization parameters for both cases that avoid data-splitting. A distinguishing feature of our analysis is that we derive deterministic error bounds in terms of the error of the coefficients, thus allowing the complete separation of the analysis of the stochastic properties of these errors. We show that our results lead to new insights and bounds for linear value function estimation in reinforcement learning.
An Adaptive Algorithm for Finite Stochastic Partial Monitoring
Jun 27, 2012
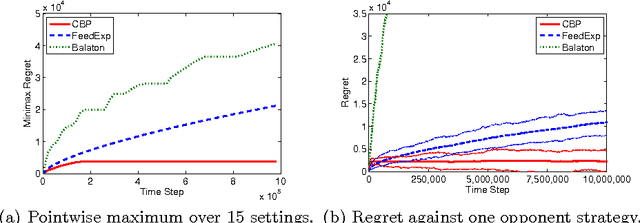
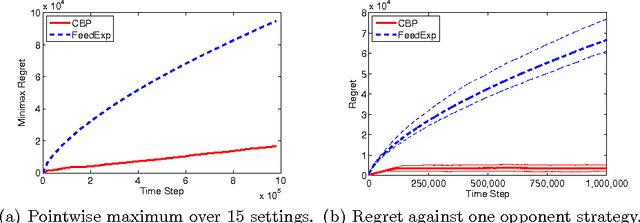
We present a new anytime algorithm that achieves near-optimal regret for any instance of finite stochastic partial monitoring. In particular, the new algorithm achieves the minimax regret, within logarithmic factors, for both "easy" and "hard" problems. For easy problems, it additionally achieves logarithmic individual regret. Most importantly, the algorithm is adaptive in the sense that if the opponent strategy is in an "easy region" of the strategy space then the regret grows as if the problem was easy. As an implication, we show that under some reasonable additional assumptions, the algorithm enjoys an O(\sqrt{T}) regret in Dynamic Pricing, proven to be hard by Bartok et al. (2011).
Apprenticeship Learning using Inverse Reinforcement Learning and Gradient Methods
Jun 20, 2012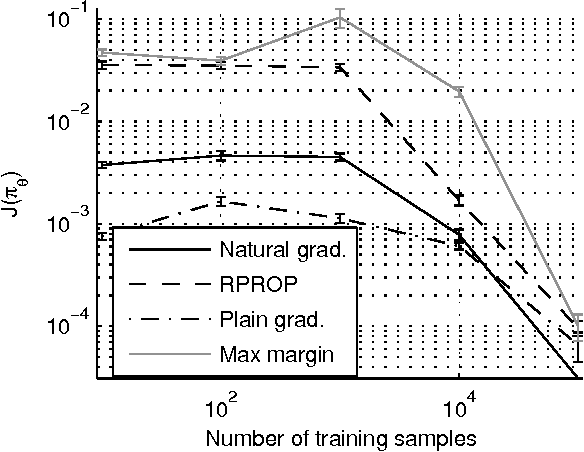

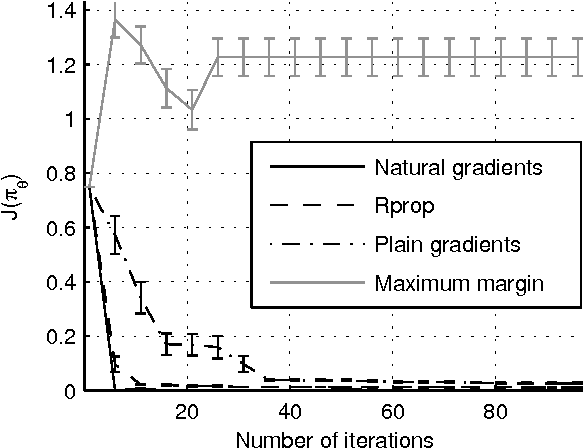
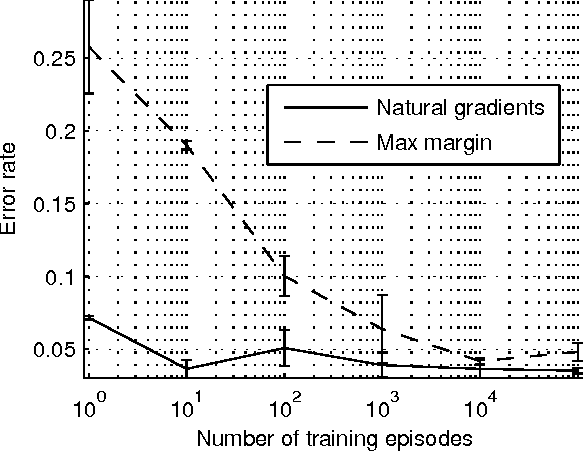
In this paper we propose a novel gradient algorithm to learn a policy from an expert's observed behavior assuming that the expert behaves optimally with respect to some unknown reward function of a Markovian Decision Problem. The algorithm's aim is to find a reward function such that the resulting optimal policy matches well the expert's observed behavior. The main difficulty is that the mapping from the parameters to policies is both nonsmooth and highly redundant. Resorting to subdifferentials solves the first difficulty, while the second one is over- come by computing natural gradients. We tested the proposed method in two artificial domains and found it to be more reliable and efficient than some previous methods.
Analysis of Kernel Mean Matching under Covariate Shift
Jun 18, 2012In real supervised learning scenarios, it is not uncommon that the training and test sample follow different probability distributions, thus rendering the necessity to correct the sampling bias. Focusing on a particular covariate shift problem, we derive high probability confidence bounds for the kernel mean matching (KMM) estimator, whose convergence rate turns out to depend on some regularity measure of the regression function and also on some capacity measure of the kernel. By comparing KMM with the natural plug-in estimator, we establish the superiority of the former hence provide concrete evidence/understanding to the effectiveness of KMM under covariate shift.
Dyna-Style Planning with Linear Function Approximation and Prioritized Sweeping
Jun 13, 2012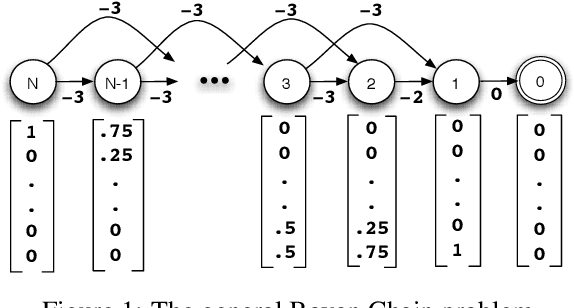
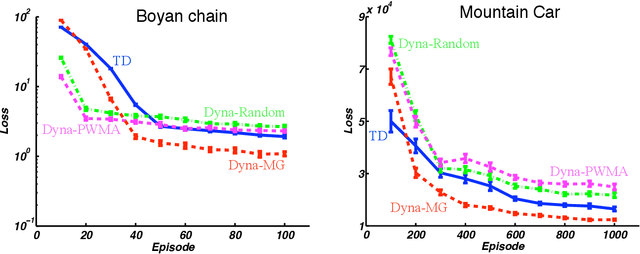
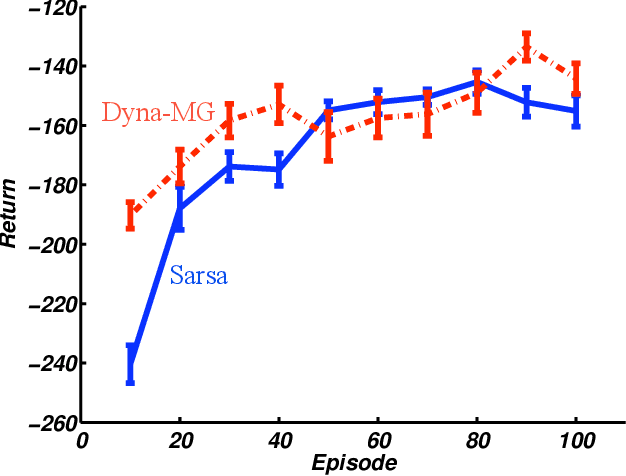
We consider the problem of efficiently learning optimal control policies and value functions over large state spaces in an online setting in which estimates must be available after each interaction with the world. This paper develops an explicitly model-based approach extending the Dyna architecture to linear function approximation. Dynastyle planning proceeds by generating imaginary experience from the world model and then applying model-free reinforcement learning algorithms to the imagined state transitions. Our main results are to prove that linear Dyna-style planning converges to a unique solution independent of the generating distribution, under natural conditions. In the policy evaluation setting, we prove that the limit point is the least-squares (LSTD) solution. An implication of our results is that prioritized-sweeping can be soundly extended to the linear approximation case, backing up to preceding features rather than to preceding states. We introduce two versions of prioritized sweeping with linear Dyna and briefly illustrate their performance empirically on the Mountain Car and Boyan Chain problems.
Speeding Up Planning in Markov Decision Processes via Automatically Constructed Abstractions
Jun 13, 2012
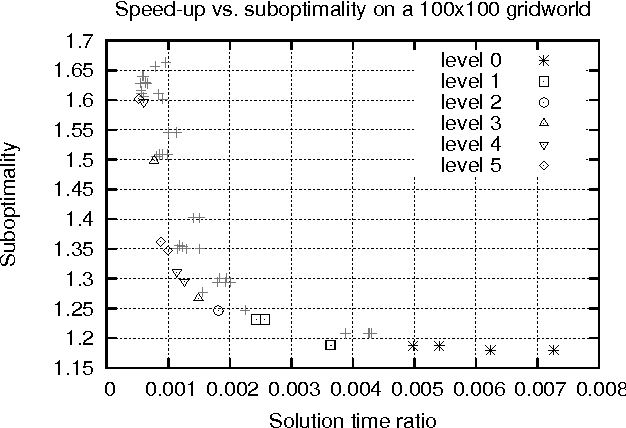
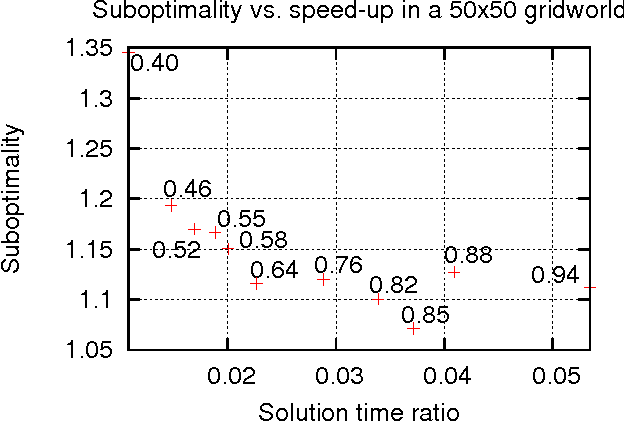
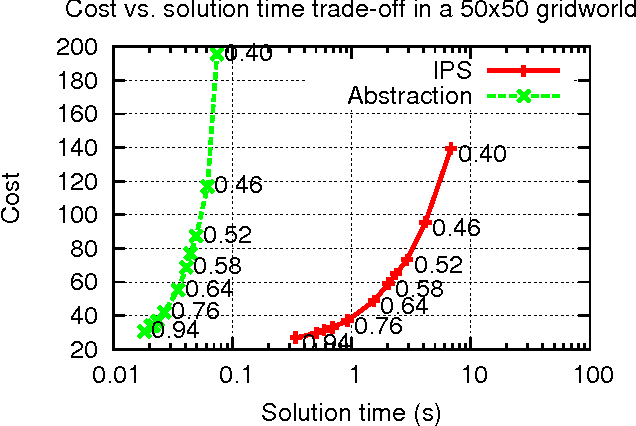
In this paper, we consider planning in stochastic shortest path (SSP) problems, a subclass of Markov Decision Problems (MDP). We focus on medium-size problems whose state space can be fully enumerated. This problem has numerous important applications, such as navigation and planning under uncertainty. We propose a new approach for constructing a multi-level hierarchy of progressively simpler abstractions of the original problem. Once computed, the hierarchy can be used to speed up planning by first finding a policy for the most abstract level and then recursively refining it into a solution to the original problem. This approach is fully automated and delivers a speed-up of two orders of magnitude over a state-of-the-art MDP solver on sample problems while returning near-optimal solutions. We also prove theoretical bounds on the loss of solution optimality resulting from the use of abstractions.
PAC-Bayesian Policy Evaluation for Reinforcement Learning
Feb 14, 2012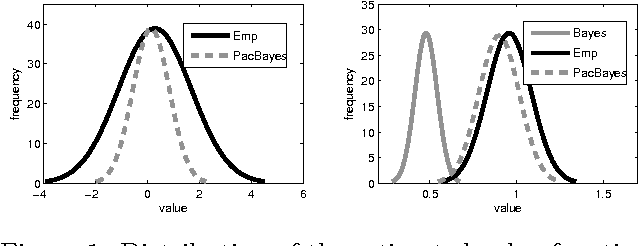
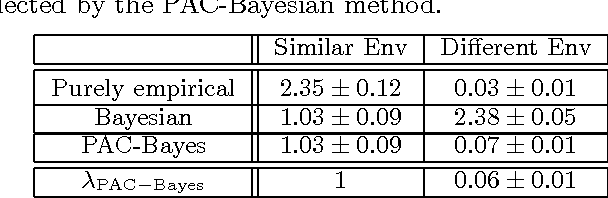

Bayesian priors offer a compact yet general means of incorporating domain knowledge into many learning tasks. The correctness of the Bayesian analysis and inference, however, largely depends on accuracy and correctness of these priors. PAC-Bayesian methods overcome this problem by providing bounds that hold regardless of the correctness of the prior distribution. This paper introduces the first PAC-Bayesian bound for the batch reinforcement learning problem with function approximation. We show how this bound can be used to perform model-selection in a transfer learning scenario. Our empirical results confirm that PAC-Bayesian policy evaluation is able to leverage prior distributions when they are informative and, unlike standard Bayesian RL approaches, ignore them when they are misleading.
Alignment Based Kernel Learning with a Continuous Set of Base Kernels
Dec 20, 2011
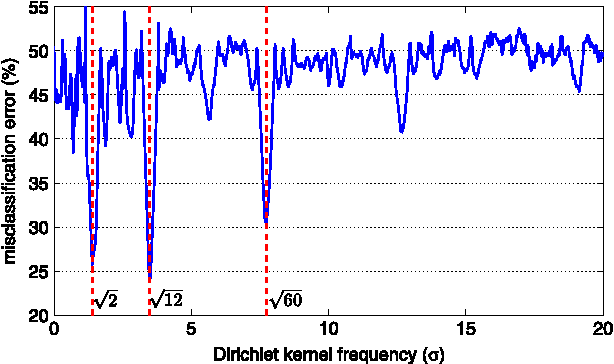
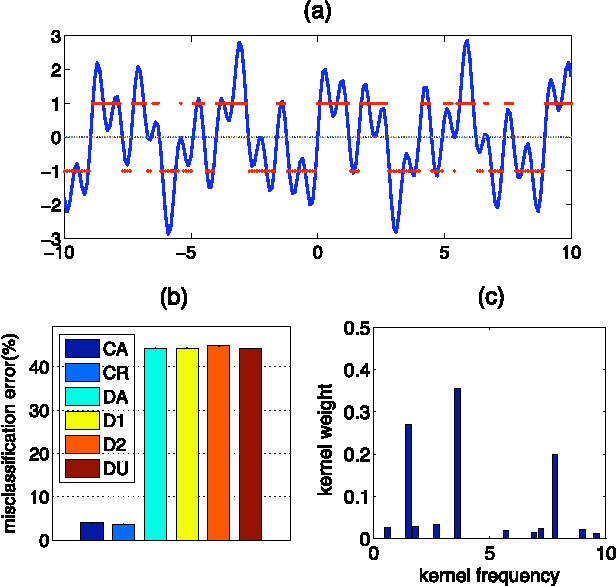
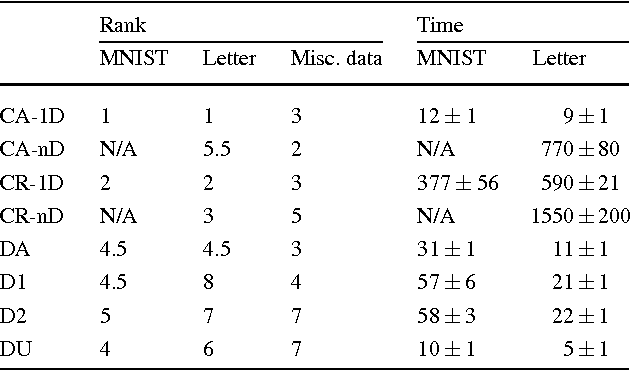
The success of kernel-based learning methods depend on the choice of kernel. Recently, kernel learning methods have been proposed that use data to select the most appropriate kernel, usually by combining a set of base kernels. We introduce a new algorithm for kernel learning that combines a {\em continuous set of base kernels}, without the common step of discretizing the space of base kernels. We demonstrate that our new method achieves state-of-the-art performance across a variety of real-world datasets. Furthermore, we explicitly demonstrate the importance of combining the right dictionary of kernels, which is problematic for methods based on a finite set of base kernels chosen a priori. Our method is not the first approach to work with continuously parameterized kernels. However, we show that our method requires substantially less computation than previous such approaches, and so is more amenable to multiple dimensional parameterizations of base kernels, which we demonstrate.
X-Armed Bandits
Apr 13, 2011

We consider a generalization of stochastic bandits where the set of arms, $\cX$, is allowed to be a generic measurable space and the mean-payoff function is "locally Lipschitz" with respect to a dissimilarity function that is known to the decision maker. Under this condition we construct an arm selection policy, called HOO (hierarchical optimistic optimization), with improved regret bounds compared to previous results for a large class of problems. In particular, our results imply that if $\cX$ is the unit hypercube in a Euclidean space and the mean-payoff function has a finite number of global maxima around which the behavior of the function is locally continuous with a known smoothness degree, then the expected regret of HOO is bounded up to a logarithmic factor by $\sqrt{n}$, i.e., the rate of growth of the regret is independent of the dimension of the space. We also prove the minimax optimality of our algorithm when the dissimilarity is a metric. Our basic strategy has quadratic computational complexity as a function of the number of time steps and does not rely on the doubling trick. We also introduce a modified strategy, which relies on the doubling trick but runs in linearithmic time. Both results are improvements with respect to previous approaches.
Online Least Squares Estimation with Self-Normalized Processes: An Application to Bandit Problems
Feb 14, 2011
The analysis of online least squares estimation is at the heart of many stochastic sequential decision making problems. We employ tools from the self-normalized processes to provide a simple and self-contained proof of a tail bound of a vector-valued martingale. We use the bound to construct a new tighter confidence sets for the least squares estimate. We apply the confidence sets to several online decision problems, such as the multi-armed and the linearly parametrized bandit problems. The confidence sets are potentially applicable to other problems such as sleeping bandits, generalized linear bandits, and other linear control problems. We improve the regret bound of the Upper Confidence Bound (UCB) algorithm of Auer et al. (2002) and show that its regret is with high-probability a problem dependent constant. In the case of linear bandits (Dani et al., 2008), we improve the problem dependent bound in the dimension and number of time steps. Furthermore, as opposed to the previous result, we prove that our bound holds for small sample sizes, and at the same time the worst case bound is improved by a logarithmic factor and the constant is improved.