 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Witness-type Triangle Puzzles Faster with an Automatically Learned Human-Explainable Predicate
Aug 04, 2023Automatically solving puzzle instances in the game The Witness can guide players toward solutions and help puzzle designers generate better puzzles. In the latter case such an Artificial Intelligence puzzle solver can inform a human puzzle designer and procedural puzzle generator to produce better instances. The puzzles, however, are combinatorially difficult and search-based solvers can require large amounts of time and memory. We accelerate such search by automatically learning a human-explainable predicate that predicts whether a partial path to a Witness-type puzzle is not completable to a solution path. We prove a key property of the learned predicate which allows us to use it for pruning successor states in search thereby accelerating search by an average of six times while maintaining completeness of the underlying search. Conversely given a fixed search time budget per puzzle our predicate-accelerated search can solve more puzzle instances of larger sizes than the baseline search.
Automatic Algorithm Selection In Multi-agent Pathfinding
Jun 15, 2019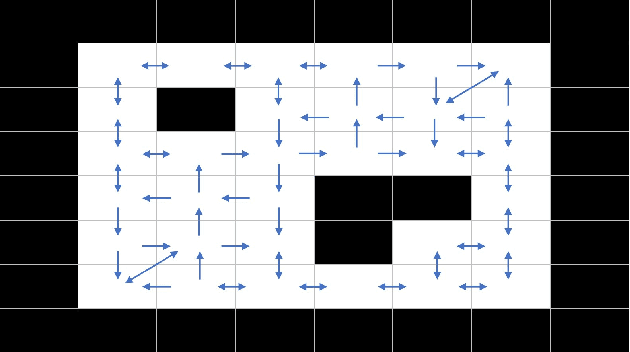


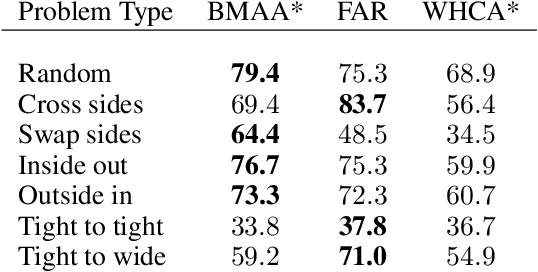
In a multi-agent pathfinding (MAPF) problem, agents need to navigate from their start to their goal locations without colliding into each other. There are various MAPF algorithms, including Windowed Hierarchical Cooperative A*, Flow Annotated Replanning, and Bounded Multi-Agent A*. It is often the case that there is no a single algorithm that dominates all MAPF instances. Therefore, in this paper, we investigate the use of deep learning to automatically select the best MAPF algorithm from a portfolio of algorithms for a given MAPF problem instance. Empirical results show that our automatic algorithm selection approach, which uses an off-the-shelf convolutional neural network, is able to outperform any individual MAPF algorithm in our portfolio.
Flow for Meta Control
Jul 17, 2014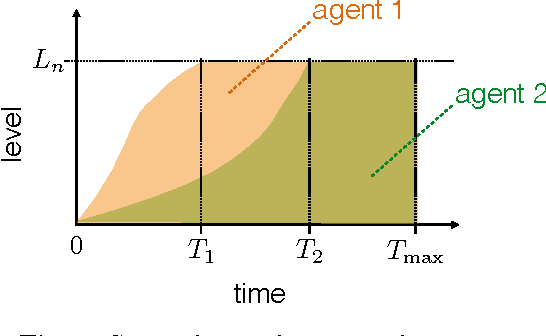

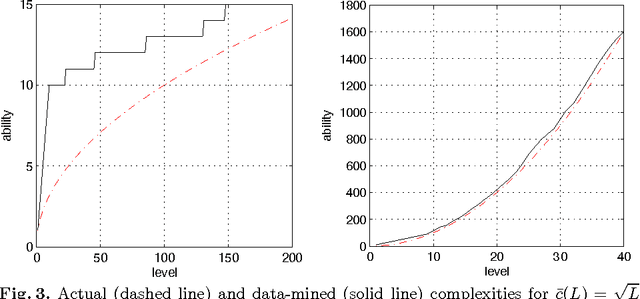
The psychological state of flow has been linked to optimizing human performance. A key condition of flow emergence is a match between the human abilities and complexity of the task. We propose a simple computational model of flow for Artificial Intelligence (AI) agents. The model factors the standard agent-environment state into a self-reflective set of the agent's abilities and a socially learned set of the environmental complexity. Maximizing the flow serves as a meta control for the agent. We show how to apply the meta-control policy to a broad class of AI control policies and illustrate our approach with a specific implementation. Results in a synthetic testbed are promising and open interesting directions for future work.
Case-Based Subgoaling in Real-Time Heuristic Search for Video Game Pathfinding
Jan 16, 2014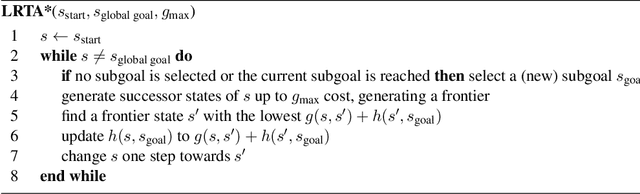
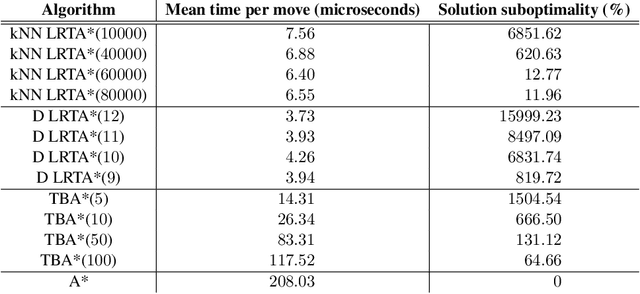
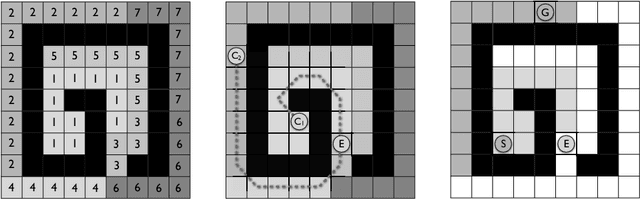
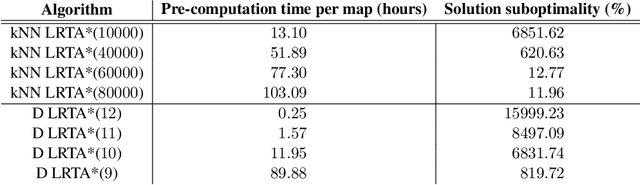
Real-time heuristic search algorithms satisfy a constant bound on the amount of planning per action, independent of problem size. As a result, they scale up well as problems become larger. This property would make them well suited for video games where Artificial Intelligence controlled agents must react quickly to user commands and to other agents actions. On the downside, real-time search algorithms employ learning methods that frequently lead to poor solution quality and cause the agent to appear irrational by re-visiting the same problem states repeatedly. The situation changed recently with a new algorithm, D LRTA*, which attempted to eliminate learning by automatically selecting subgoals. D LRTA* is well poised for video games, except it has a complex and memory-demanding pre-computation phase during which it builds a database of subgoals. In this paper, we propose a simpler and more memory-efficient way of pre-computing subgoals thereby eliminating the main obstacle to applying state-of-the-art real-time search methods in video games. The new algorithm solves a number of randomly chosen problems off-line, compresses the solutions into a series of subgoals and stores them in a database. When presented with a novel problem on-line, it queries the database for the most similar previously solved case and uses its subgoals to solve the problem. In the domain of pathfinding on four large video game maps, the new algorithm delivers solutions eight times better while using 57 times less memory and requiring 14% less pre-computation time.
Search-Space Characterization for Real-time Heuristic Search
Aug 15, 2013
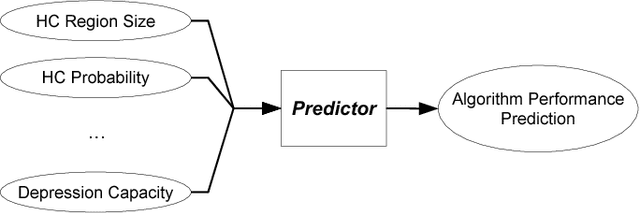
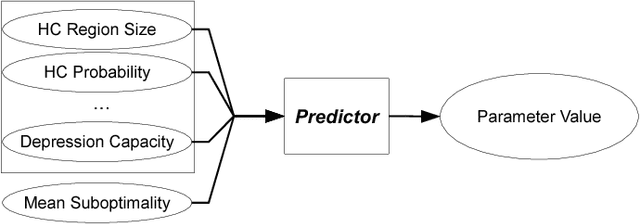
Recent real-time heuristic search algorithms have demonstrated outstanding performance in video-game pathfinding. However, their applications have been thus far limited to that domain. We proceed with the aim of facilitating wider applications of real-time search by fostering a greater understanding of the performance of recent algorithms. We first introduce eight algorithm-independent complexity measures for search spaces and correlate their values with algorithm performance. The complexity measures are statistically shown to be significant predictors of algorithm performance across a set of commercial video-game maps. We then extend this analysis to a wider variety of search spaces in the first application of database-driven real-time search to domains outside of video-game pathfinding. In doing so, we gain insight into algorithm performance and possible enhancement as well as into search space complexity.
Speeding Up Planning in Markov Decision Processes via Automatically Constructed Abstractions
Jun 13, 2012
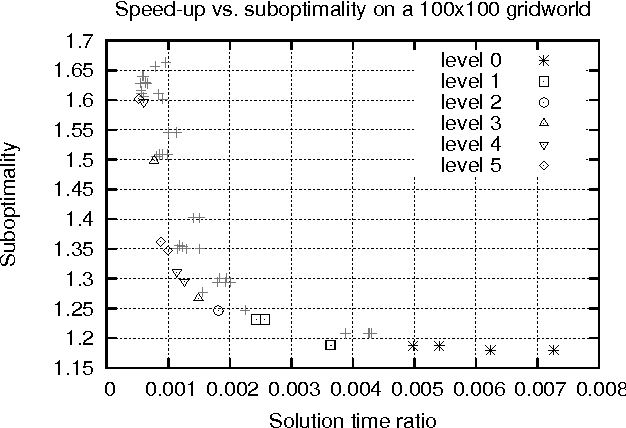
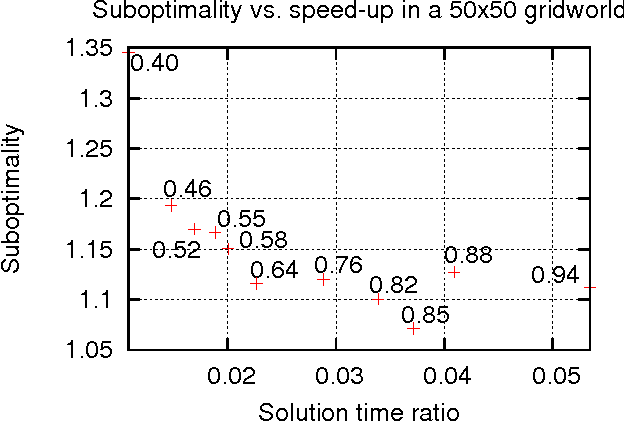
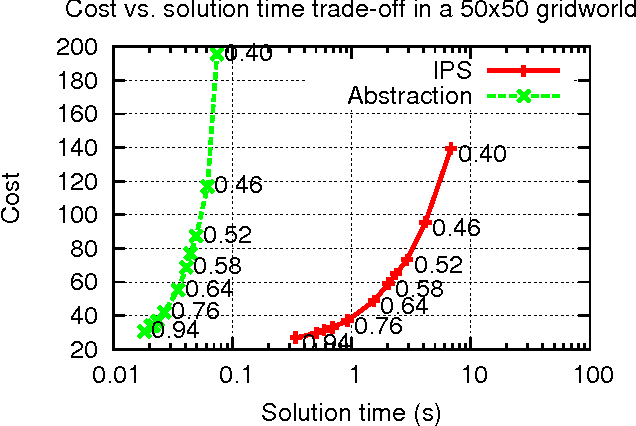
In this paper, we consider planning in stochastic shortest path (SSP) problems, a subclass of Markov Decision Problems (MDP). We focus on medium-size problems whose state space can be fully enumerated. This problem has numerous important applications, such as navigation and planning under uncertainty. We propose a new approach for constructing a multi-level hierarchy of progressively simpler abstractions of the original problem. Once computed, the hierarchy can be used to speed up planning by first finding a policy for the most abstract level and then recursively refining it into a solution to the original problem. This approach is fully automated and delivers a speed-up of two orders of magnitude over a state-of-the-art MDP solver on sample problems while returning near-optimal solutions. We also prove theoretical bounds on the loss of solution optimality resulting from the use of abstractions.
On Backtracking in Real-time Heuristic Search
Dec 16, 2009

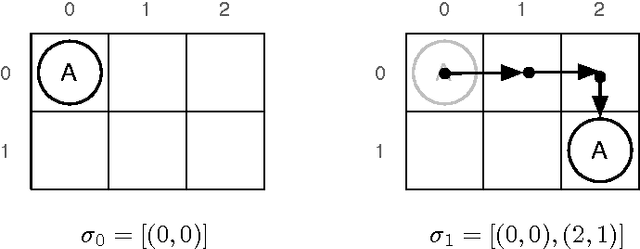
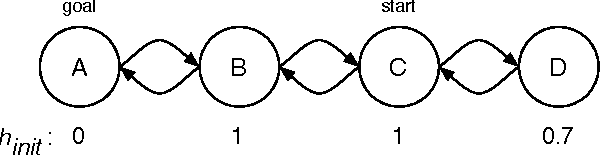
Real-time heuristic search algorithms are suitable for situated agents that need to make their decisions in constant time. Since the original work by Korf nearly two decades ago, numerous extensions have been suggested. One of the most intriguing extensions is the idea of backtracking wherein the agent decides to return to a previously visited state as opposed to moving forward greedily. This idea has been empirically shown to have a significant impact on various performance measures. The studies have been carried out in particular empirical testbeds with specific real-time search algorithms that use backtracking. Consequently, the extent to which the trends observed are characteristic of backtracking in general is unclear. In this paper, we present the first entirely theoretical study of backtracking in real-time heuristic search. In particular, we present upper bounds on the solution cost exponential and linear in a parameter regulating the amount of backtracking. The results hold for a wide class of real-time heuristic search algorithms that includes many existing algorithms as a small subclass.
Learning for Adaptive Real-time Search
Jul 06, 2004
Real-time heuristic search is a popular model of acting and learning in intelligent autonomous agents. Learning real-time search agents improve their performance over time by acquiring and refining a value function guiding the application of their actions. As computing the perfect value function is typically intractable, a heuristic approximation is acquired instead. Most studies of learning in real-time search (and reinforcement learning) assume that a simple value-function-greedy policy is used to select actions. This is in contrast to practice, where high-performance is usually attained by interleaving planning and acting via a lookahead search of a non-trivial depth. In this paper, we take a step toward bridging this gap and propose a novel algorithm that (i) learns a heuristic function to be used specifically with a lookahead-based policy, (ii) selects the lookahead depth adaptively in each state, (iii) gives the user control over the trade-off between exploration and exploitation. We extensively evaluate the algorithm in the sliding tile puzzle testbed comparing it to the classical LRTA* and the more recent weighted LRTA*, bounded LRTA*, and FALCONS. Improvements of 5 to 30 folds in convergence speed are observed.
Oracle Complexity and Nontransitivity in Pattern Recognition
Oct 16, 2000
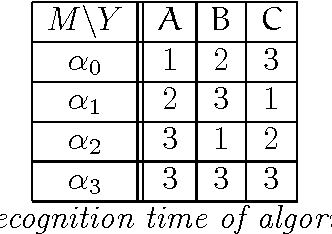
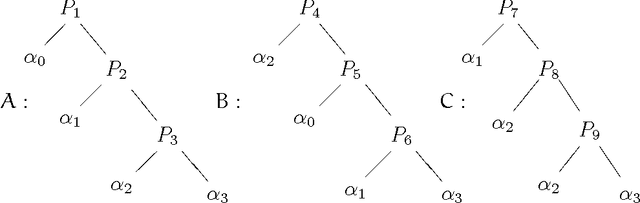
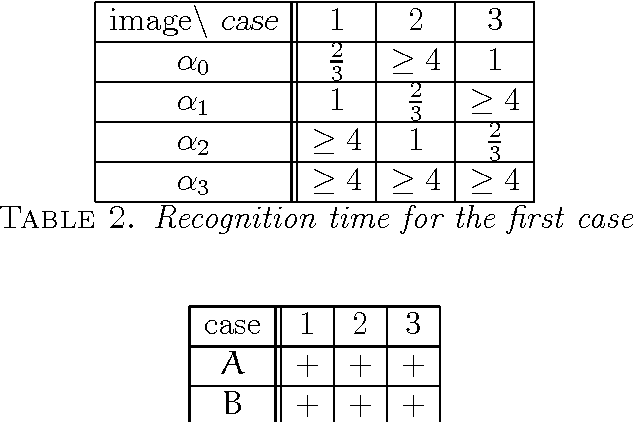
Different mathematical models of recognition processes are known. In the present paper we consider a pattern recognition algorithm as an oracle computation on a Turing machine. Such point of view seems to be useful in pattern recognition as well as in recursion theory. Use of recursion theory in pattern recognition shows connection between a recognition algorithm comparison problem and complexity problems of oracle computation. That is because in many cases we can take into account only the number of sign computations or in other words volume of oracle information needed. Therefore, the problem of recognition algorithm preference can be formulated as a complexity optimization problem of oracle computation. Furthermore, introducing a certain "natural" preference relation on a set of recognizing algorithms, we discover it to be nontransitive. This relates to the well known nontransitivity paradox in probability theory. Keywords: Pattern Recognition, Recursion Theory, Nontransitivity, Preference Relation