 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Rank-1 Bandits
Mar 08, 2017
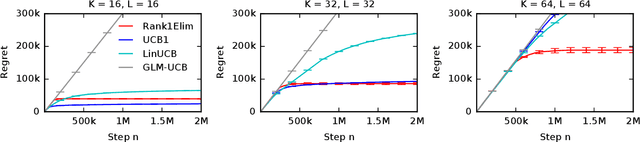
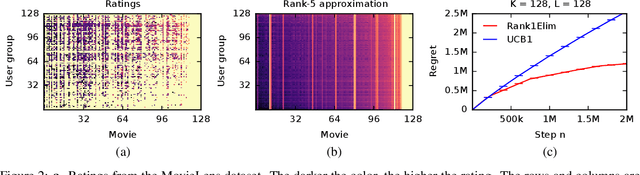
We propose stochastic rank-$1$ bandits, a class of online learning problems where at each step a learning agent chooses a pair of row and column arms, and receives the product of their values as a reward. The main challenge of the problem is that the individual values of the row and column are unobserved. We assume that these values are stochastic and drawn independently. We propose a computationally-efficient algorithm for solving our problem, which we call Rank1Elim. We derive a $O((K + L) (1 / \Delta) \log n)$ upper bound on its $n$-step regret, where $K$ is the number of rows, $L$ is the number of columns, and $\Delta$ is the minimum of the row and column gaps; under the assumption that the mean row and column rewards are bounded away from zero. To the best of our knowledge, we present the first bandit algorithm that finds the maximum entry of a rank-$1$ matrix whose regret is linear in $K + L$, $1 / \Delta$, and $\log n$. We also derive a nearly matching lower bound. Finally, we evaluate Rank1Elim empirically on multiple problems. We observe that it leverages the structure of our problems and can learn near-optimal solutions even if our modeling assumptions are mildly violated.
Sequential Learning without Feedback
Oct 18, 2016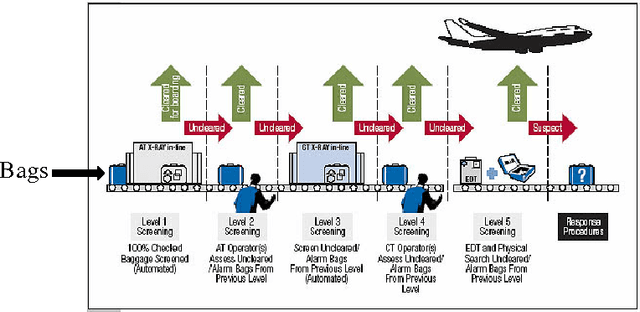
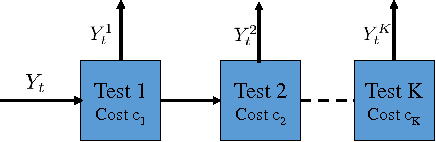

In many security and healthcare systems a sequence of features/sensors/tests are used for detection and diagnosis. Each test outputs a prediction of the latent state, and carries with it inherent costs. Our objective is to {\it learn} strategies for selecting tests to optimize accuracy \& costs. Unfortunately it is often impossible to acquire in-situ ground truth annotations and we are left with the problem of unsupervised sensor selection (USS). We pose USS as a version of stochastic partial monitoring problem with an {\it unusual} reward structure (even noisy annotations are unavailable). Unsurprisingly no learner can achieve sublinear regret without further assumptions. To this end we propose the notion of weak-dominance. This is a condition on the joint probability distribution of test outputs and latent state and says that whenever a test is accurate on an example, a later test in the sequence is likely to be accurate as well. We empirically verify that weak dominance holds on real datasets and prove that it is a maximal condition for achieving sublinear regret. We reduce USS to a special case of multi-armed bandit problem with side information and develop polynomial time algorithms that achieve sublinear regret.
The End of Optimism? An Asymptotic Analysis of Finite-Armed Linear Bandits
Oct 14, 2016Stochastic linear bandits are a natural and simple generalisation of finite-armed bandits with numerous practical applications. Current approaches focus on generalising existing techniques for finite-armed bandits, notably the optimism principle and Thompson sampling. While prior work has mostly been in the worst-case setting, we analyse the asymptotic instance-dependent regret and show matching upper and lower bounds on what is achievable. Surprisingly, our results show that no algorithm based on optimism or Thompson sampling will ever achieve the optimal rate, and indeed, can be arbitrarily far from optimal, even in very simple cases. This is a disturbing result because these techniques are standard tools that are widely used for sequential optimisation. For example, for generalised linear bandits and reinforcement learning.
Learning with a Strong Adversary
Jan 16, 2016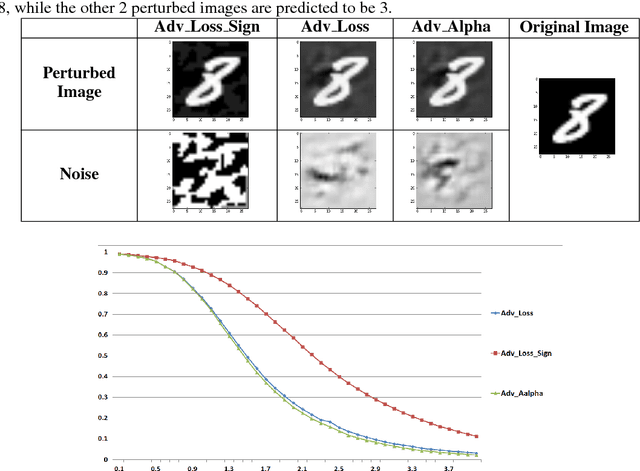
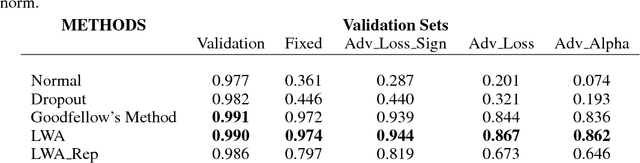
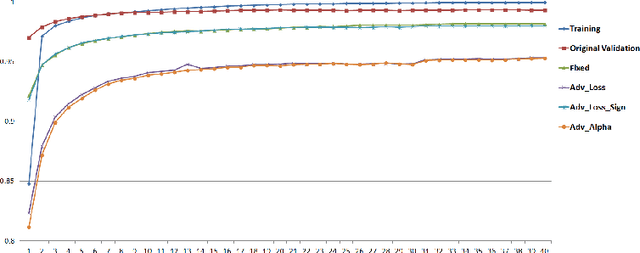
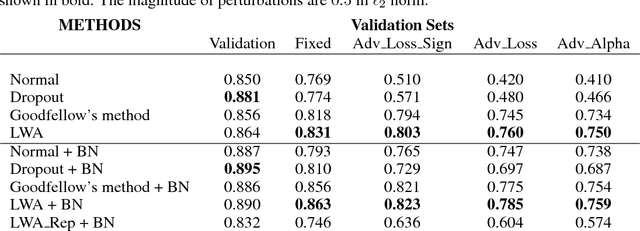
The robustness of neural networks to intended perturbations has recently attracted significant attention. In this paper, we propose a new method, \emph{learning with a strong adversary}, that learns robust classifiers from supervised data. The proposed method takes finding adversarial examples as an intermediate step. A new and simple way of finding adversarial examples is presented and experimentally shown to be efficient. Experimental results demonstrate that resulting learning method greatly improves the robustness of the classification models produced.
Combinatorial Cascading Bandits
Nov 17, 2015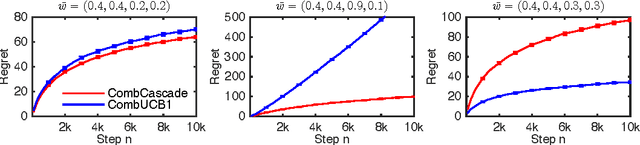
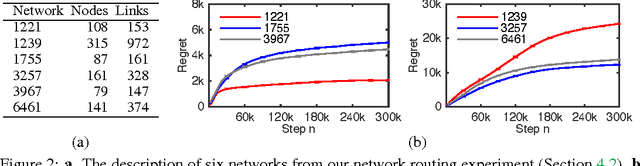
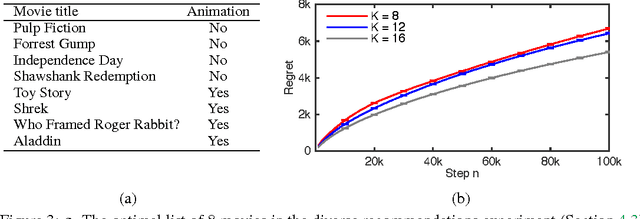
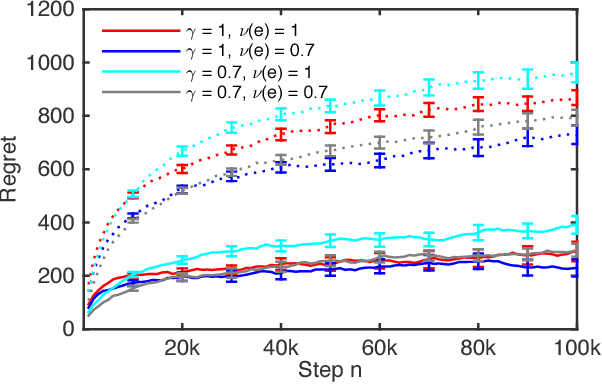
We propose combinatorial cascading bandits, a class of partial monitoring problems where at each step a learning agent chooses a tuple of ground items subject to constraints and receives a reward if and only if the weights of all chosen items are one. The weights of the items are binary, stochastic, and drawn independently of each other. The agent observes the index of the first chosen item whose weight is zero. This observation model arises in network routing, for instance, where the learning agent may only observe the first link in the routing path which is down, and blocks the path. We propose a UCB-like algorithm for solving our problems, CombCascade; and prove gap-dependent and gap-free upper bounds on its $n$-step regret. Our proofs build on recent work in stochastic combinatorial semi-bandits but also address two novel challenges of our setting, a non-linear reward function and partial observability. We evaluate CombCascade on two real-world problems and show that it performs well even when our modeling assumptions are violated. We also demonstrate that our setting requires a new learning algorithm.
Cascading Bandits: Learning to Rank in the Cascade Model
May 18, 2015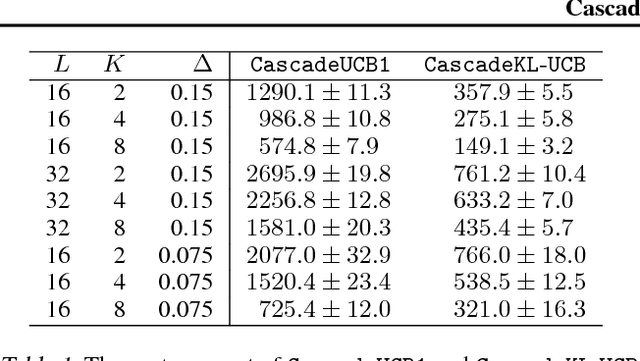
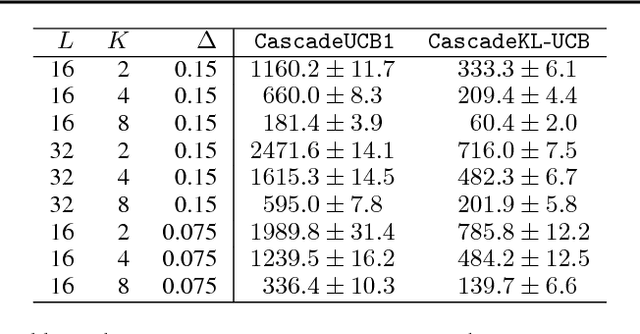
A search engine usually outputs a list of $K$ web pages. The user examines this list, from the first web page to the last, and chooses the first attractive page. This model of user behavior is known as the cascade model. In this paper, we propose cascading bandits, a learning variant of the cascade model where the objective is to identify $K$ most attractive items. We formulate our problem as a stochastic combinatorial partial monitoring problem. We propose two algorithms for solving it, CascadeUCB1 and CascadeKL-UCB. We also prove gap-dependent upper bounds on the regret of these algorithms and derive a lower bound on the regret in cascading bandits. The lower bound matches the upper bound of CascadeKL-UCB up to a logarithmic factor. We experiment with our algorithms on several problems. The algorithms perform surprisingly well even when our modeling assumptions are violated.
Tight Regret Bounds for Stochastic Combinatorial Semi-Bandits
Jan 27, 2015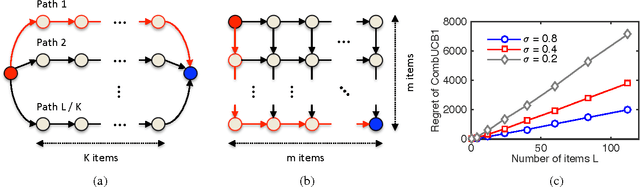
A stochastic combinatorial semi-bandit is an online learning problem where at each step a learning agent chooses a subset of ground items subject to constraints, and then observes stochastic weights of these items and receives their sum as a payoff. In this paper, we close the problem of computationally and sample efficient learning in stochastic combinatorial semi-bandits. In particular, we analyze a UCB-like algorithm for solving the problem, which is known to be computationally efficient; and prove $O(K L (1 / \Delta) \log n)$ and $O(\sqrt{K L n \log n})$ upper bounds on its $n$-step regret, where $L$ is the number of ground items, $K$ is the maximum number of chosen items, and $\Delta$ is the gap between the expected returns of the optimal and best suboptimal solutions. The gap-dependent bound is tight up to a constant factor and the gap-free bound is tight up to a polylogarithmic factor.
On Minimax Optimal Offline Policy Evaluation
Sep 12, 2014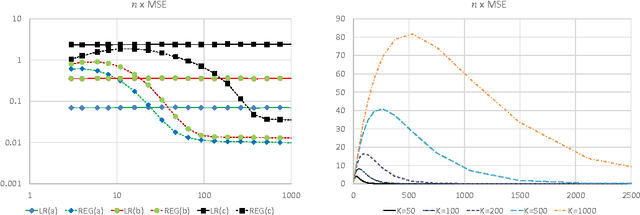
This paper studies the off-policy evaluation problem, where one aims to estimate the value of a target policy based on a sample of observations collected by another policy. We first consider the multi-armed bandit case, establish a minimax risk lower bound, and analyze the risk of two standard estimators. It is shown, and verified in simulation, that one is minimax optimal up to a constant, while another can be arbitrarily worse, despite its empirical success and popularity. The results are applied to related problems in contextual bandits and fixed-horizon Markov decision processes, and are also related to semi-supervised learning.
Bayesian Optimal Control of Smoothly Parameterized Systems: The Lazy Posterior Sampling Algorithm
Jun 16, 2014

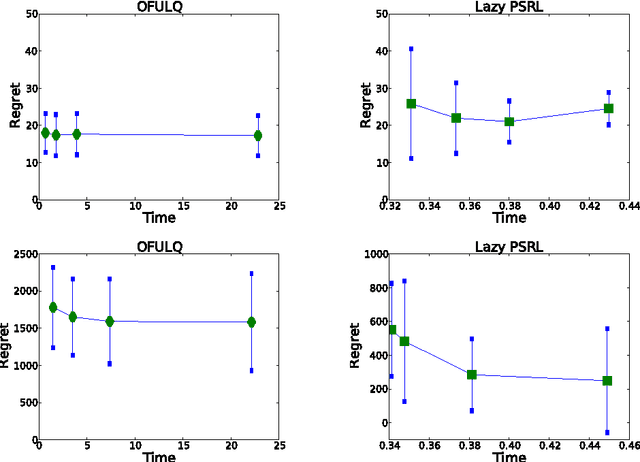
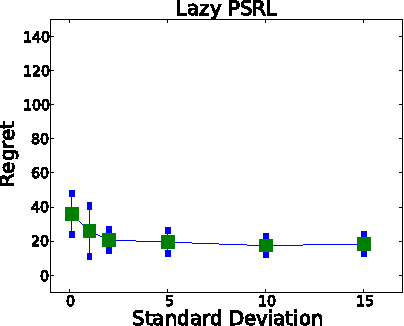
We study Bayesian optimal control of a general class of smoothly parameterized Markov decision problems. Since computing the optimal control is computationally expensive, we design an algorithm that trades off performance for computational efficiency. The algorithm is a lazy posterior sampling method that maintains a distribution over the unknown parameter. The algorithm changes its policy only when the variance of the distribution is reduced sufficiently. Importantly, we analyze the algorithm and show the precise nature of the performance vs. computation tradeoff. Finally, we show the effectiveness of the method on a web server control application.
Online Learning in Markov Decision Processes with Adversarially Chosen Transition Probability Distributions
Mar 12, 2013

We study the problem of learning Markov decision processes with finite state and action spaces when the transition probability distributions and loss functions are chosen adversarially and are allowed to change with time. We introduce an algorithm whose regret with respect to any policy in a comparison class grows as the square root of the number of rounds of the game, provided the transition probabilities satisfy a uniform mixing condition. Our approach is efficient as long as the comparison class is polynomial and we can compute expectations over sample paths for each policy. Designing an efficient algorithm with small regret for the general case remains an open problem.