 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Metrics for Multi-Object Tracking
Apr 06, 2021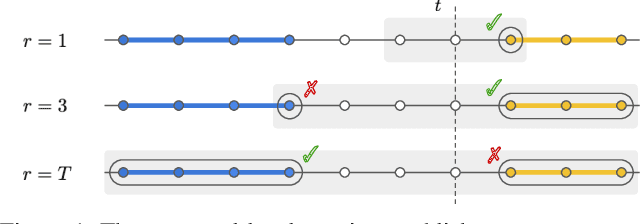
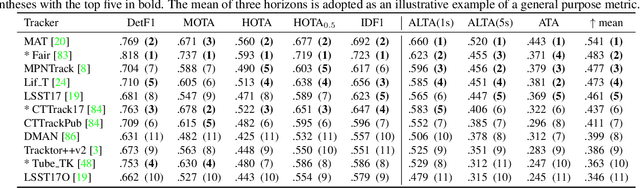
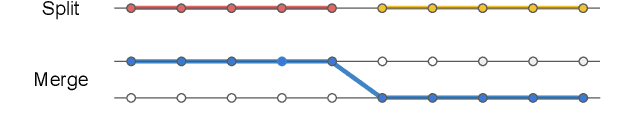
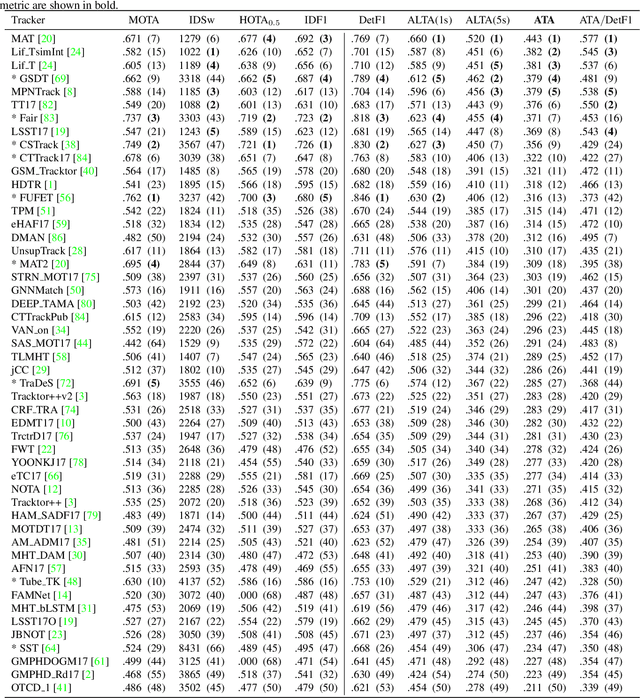
This paper introduces temporally local metrics for Multi-Object Tracking. These metrics are obtained by restricting existing metrics based on track matching to a finite temporal horizon, and provide new insight into the ability of trackers to maintain identity over time. Moreover, the horizon parameter offers a novel, meaningful mechanism by which to define the relative importance of detection and association, a common dilemma in applications where imperfect association is tolerable. It is shown that the historical Average Tracking Accuracy (ATA) metric exhibits superior sensitivity to association, enabling its proposed local variant, ALTA, to capture a wide range of characteristics. In particular, ALTA is better equipped to identify advances in association independent of detection. The paper further presents an error decomposition for ATA that reveals the impact of four distinct error types and is equally applicable to ALTA. The diagnostic capabilities of ALTA are demonstrated on the MOT 2017 and Waymo Open Dataset benchmarks.
Learning Complex 3D Human Self-Contact
Dec 18, 2020



Monocular estimation of three dimensional human self-contact is fundamental for detailed scene analysis including body language understanding and behaviour modeling. Existing 3d reconstruction methods do not focus on body regions in self-contact and consequently recover configurations that are either far from each other or self-intersecting, when they should just touch. This leads to perceptually incorrect estimates and limits impact in those very fine-grained analysis domains where detailed 3d models are expected to play an important role. To address such challenges we detect self-contact and design 3d losses to explicitly enforce it. Specifically, we develop a model for Self-Contact Prediction (SCP), that estimates the body surface signature of self-contact, leveraging the localization of self-contact in the image, during both training and inference. We collect two large datasets to support learning and evaluation: (1) HumanSC3D, an accurate 3d motion capture repository containing $1,032$ sequences with $5,058$ contact events and $1,246,487$ ground truth 3d poses synchronized with images collected from multiple views, and (2) FlickrSC3D, a repository of $3,969$ images, containing $25,297$ surface-to-surface correspondences with annotated image spatial support. We also illustrate how more expressive 3d reconstructions can be recovered under self-contact signature constraints and present monocular detection of face-touch as one of the multiple applications made possible by more accurate self-contact models.
Embodied Visual Active Learning for Semantic Segmentation
Dec 17, 2020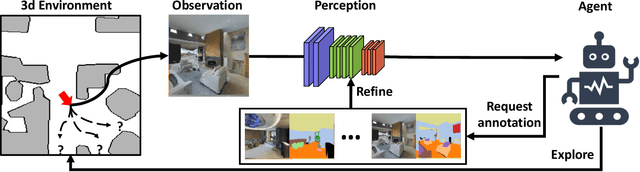
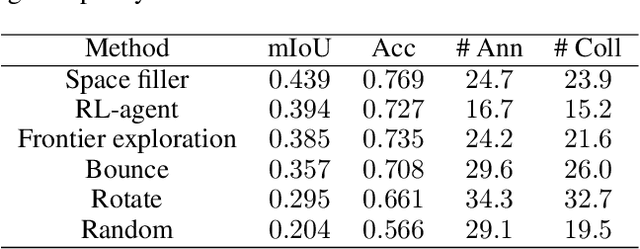
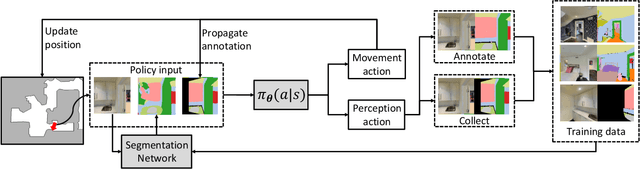
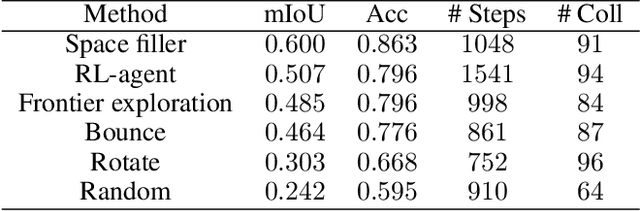
We study the task of embodied visual active learning, where an agent is set to explore a 3d environment with the goal to acquire visual scene understanding by actively selecting views for which to request annotation. While accurate on some benchmarks, today's deep visual recognition pipelines tend to not generalize well in certain real-world scenarios, or for unusual viewpoints. Robotic perception, in turn, requires the capability to refine the recognition capabilities for the conditions where the mobile system operates, including cluttered indoor environments or poor illumination. This motivates the proposed task, where an agent is placed in a novel environment with the objective of improving its visual recognition capability. To study embodied visual active learning, we develop a battery of agents - both learnt and pre-specified - and with different levels of knowledge of the environment. The agents are equipped with a semantic segmentation network and seek to acquire informative views, move and explore in order to propagate annotations in the neighbourhood of those views, then refine the underlying segmentation network by online retraining. The trainable method uses deep reinforcement learning with a reward function that balances two competing objectives: task performance, represented as visual recognition accuracy, which requires exploring the environment, and the necessary amount of annotated data requested during active exploration. We extensively evaluate the proposed models using the photorealistic Matterport3D simulator and show that a fully learnt method outperforms comparable pre-specified counterparts, even when requesting fewer annotations.
LoopReg: Self-supervised Learning of Implicit Surface Correspondences, Pose and Shape for 3D Human Mesh Registration
Oct 23, 2020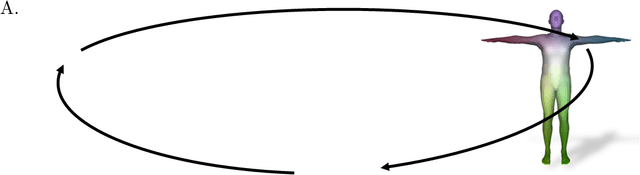
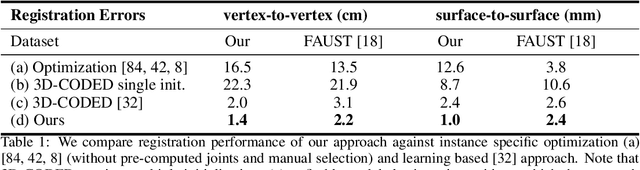

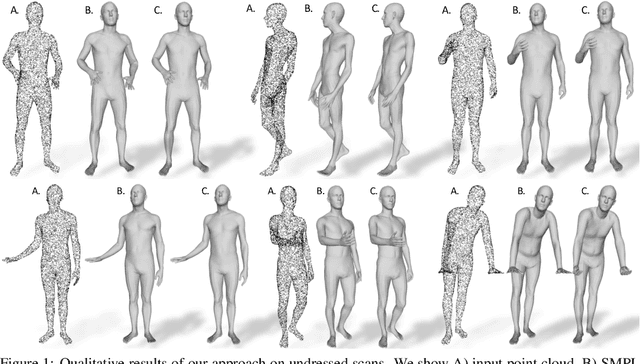
We address the problem of fitting 3D human models to 3D scans of dressed humans. Classical methods optimize both the data-to-model correspondences and the human model parameters (pose and shape), but are reliable only when initialized close to the solution. Some methods initialize the optimization based on fully supervised correspondence predictors, which is not differentiable end-to-end, and can only process a single scan at a time. Our main contribution is LoopReg, an end-to-end learning framework to register a corpus of scans to a common 3D human model. The key idea is to create a self-supervised loop. A backward map, parameterized by a Neural Network, predicts the correspondence from every scan point to the surface of the human model. A forward map, parameterized by a human model, transforms the corresponding points back to the scan based on the model parameters (pose and shape), thus closing the loop. Formulating this closed loop is not straightforward because it is not trivial to force the output of the NN to be on the surface of the human model - outside this surface the human model is not even defined. To this end, we propose two key innovations. First, we define the canonical surface implicitly as the zero level set of a distance field in R3, which in contrast to morecommon UV parameterizations, does not require cutting the surface, does not have discontinuities, and does not induce distortion. Second, we diffuse the human model to the 3D domain R3. This allows to map the NN predictions forward,even when they slightly deviate from the zero level set. Results demonstrate that we can train LoopRegmainly self-supervised - following a supervised warm-start, the model becomes increasingly more accurate as additional unlabelled raw scans are processed. Our code and pre-trained models can be downloaded for research.
* NeurIPS'20 (Oral)
Neural Descent for Visual 3D Human Pose and Shape
Aug 16, 2020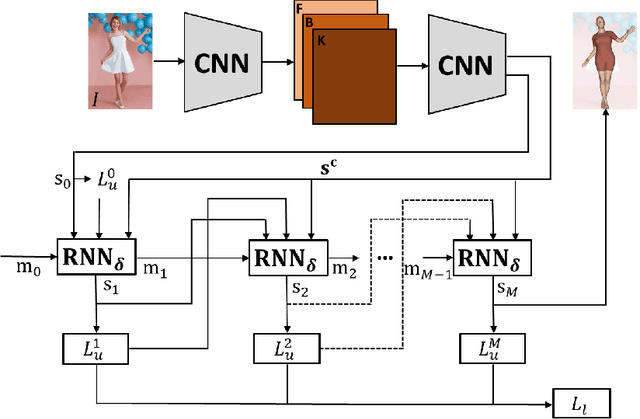
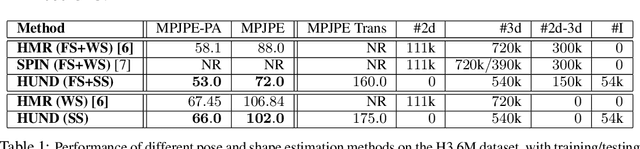

We present deep neural network methodology to reconstruct the 3d pose and shape of people, given an input RGB image. We rely on a recently introduced, expressivefull body statistical 3d human model, GHUM, trained end-to-end, and learn to reconstruct its pose and shape state in a self-supervised regime. Central to our methodology, is a learning to learn and optimize approach, referred to as HUmanNeural Descent (HUND), which avoids both second-order differentiation when training the model parameters,and expensive state gradient descent in order to accurately minimize a semantic differentiable rendering loss at test time. Instead, we rely on novel recurrent stages to update the pose and shape parameters such that not only losses are minimized effectively, but the process is meta-regularized in order to ensure end-progress. HUND's symmetry between training and testing makes it the first 3d human sensing architecture to natively support different operating regimes including self-supervised ones. In diverse tests, we show that HUND achieves very competitive results in datasets like H3.6M and 3DPW, aswell as good quality 3d reconstructions for complex imagery collected in-the-wild.
Combining Implicit Function Learning and Parametric Models for 3D Human Reconstruction
Jul 22, 2020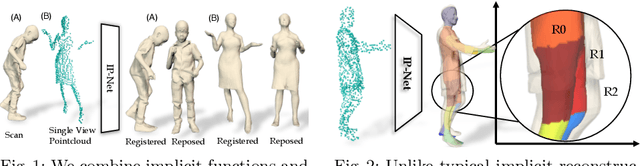

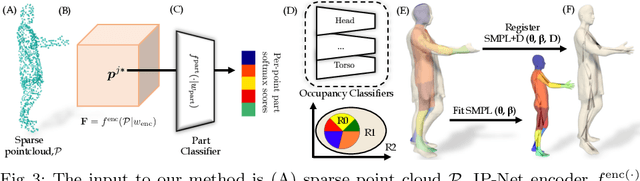
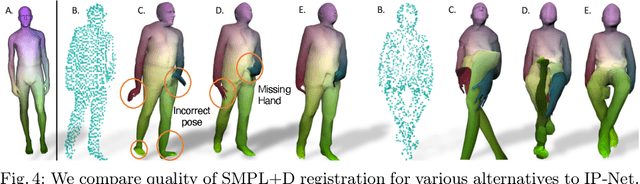
Implicit functions represented as deep learning approximations are powerful for reconstructing 3D surfaces. However, they can only produce static surfaces that are not controllable, which provides limited ability to modify the resulting model by editing its pose or shape parameters. Nevertheless, such features are essential in building flexible models for both computer graphics and computer vision. In this work, we present methodology that combines detail-rich implicit functions and parametric representations in order to reconstruct 3D models of people that remain controllable and accurate even in the presence of clothing. Given sparse 3D point clouds sampled on the surface of a dressed person, we use an Implicit Part Network (IP-Net)to jointly predict the outer 3D surface of the dressed person, the and inner body surface, and the semantic correspondences to a parametric body model. We subsequently use correspondences to fit the body model to our inner surface and then non-rigidly deform it (under a parametric body + displacement model) to the outer surface in order to capture garment, face and hair detail. In quantitative and qualitative experiments with both full body data and hand scans we show that the proposed methodology generalizes, and is effective even given incomplete point clouds collected from single-view depth images. Our models and code can be downloaded from http://virtualhumans.mpi-inf.mpg.de/ipnet.
Post-hoc Calibration of Neural Networks
Jun 23, 2020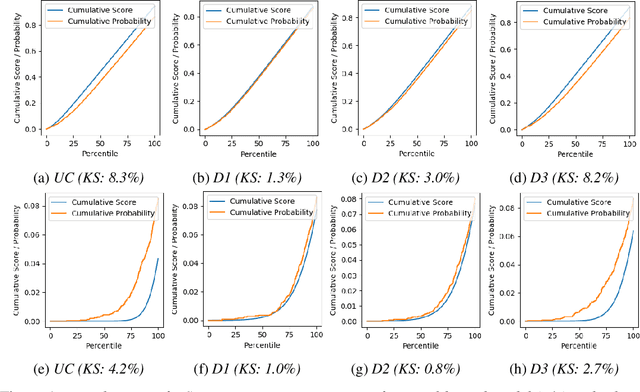

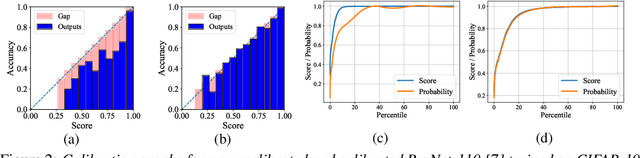
Calibration of neural networks is a critical aspect to consider when incorporating machine learning models in real-world decision-making systems where the confidence of decisions are equally important as the decisions themselves. In recent years, there is a surge of research on neural network calibration and the majority of the works can be categorized into post-hoc calibration methods, defined as methods that learn an additional function to calibrate an already trained base network. In this work, we intend to understand the post-hoc calibration methods from a theoretical point of view. Especially, it is known that minimizing Negative Log-Likelihood (NLL) will lead to a calibrated network on the training set if the global optimum is attained (Bishop, 1994). Nevertheless, it is not clear learning an additional function in a post-hoc manner would lead to calibration in the theoretical sense. To this end, we prove that even though the base network ($f$) does not lead to the global optimum of NLL, by adding additional layers ($g$) and minimizing NLL by optimizing the parameters of $g$ one can obtain a calibrated network $g \circ f$. This not only provides a less stringent condition to obtain a calibrated network but also provides a theoretical justification of post-hoc calibration methods. Our experiments on various image classification benchmarks confirm the theory.
Calibration of Neural Networks using Splines
Jun 23, 2020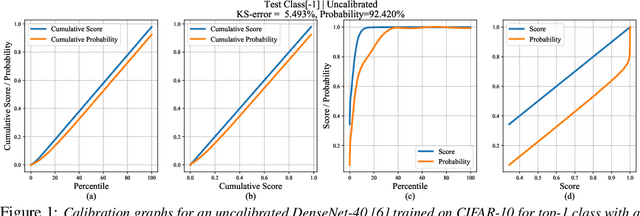
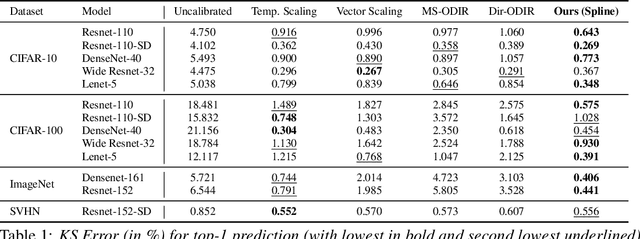
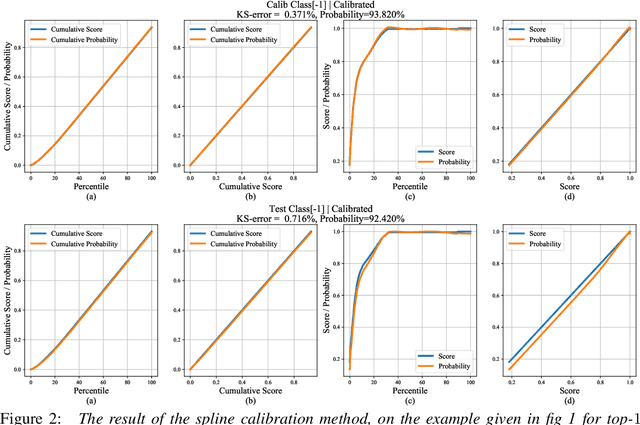
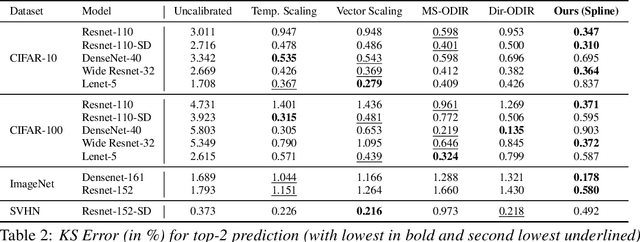
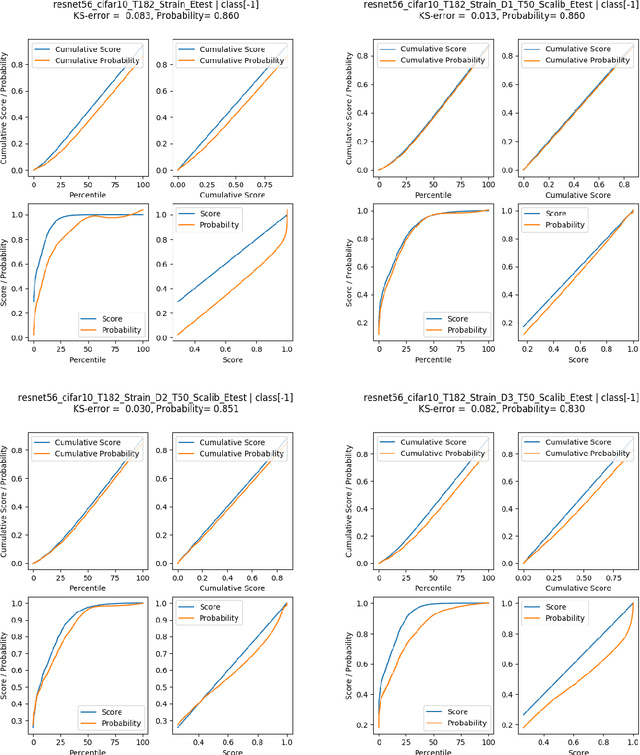
Calibrating neural networks is of utmost importance when employing them in safety-critical applications where the downstream decision making depends on the predicted probabilities. Measuring calibration error amounts to comparing two empirical distributions. In this work, we introduce a binning-free calibration measure inspired by the classical Kolmogorov-Smirnov (KS) statistical test in which the main idea is to compare the respective cumulative probability distributions. From this, by approximating the empirical cumulative distribution using a differentiable function via splines, we obtain a recalibration function, which maps the network outputs to actual (calibrated) class assignment probabilities. The spine-fitting is performed using a held-out calibration set and the obtained recalibration function is evaluated on an unseen test set. We tested our method against existing calibration approaches on various image classification datasets and our spline-based recalibration approach consistently outperforms existing methods on KS error as well as other commonly used calibration measures.
Consistency Guided Scene Flow Estimation
Jun 19, 2020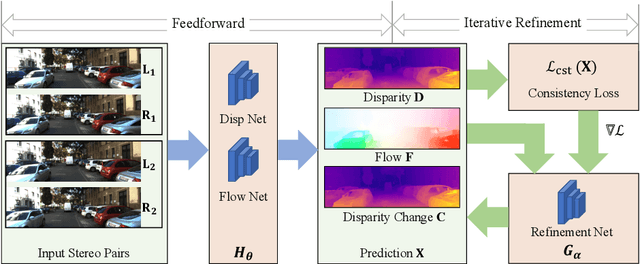


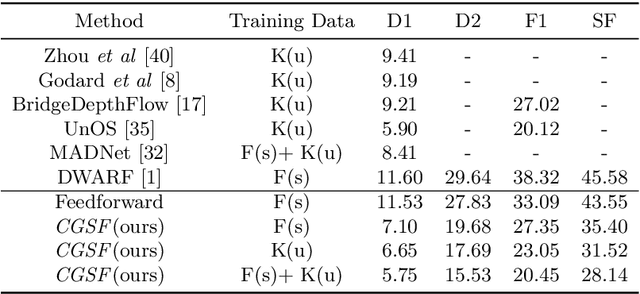
We present Consistency Guided Scene Flow Estimation (CGSF), a framework for joint estimation of 3D scene structure and motion from stereo videos. The model takes two temporal stereo pairs as input, and predicts disparity and scene flow. The model self-adapts at test time by iteratively refining its predictions. The refinement process is guided by a consistency loss, which combines stereo and temporal photo-consistency with a geometric term that couples the disparity and 3D motion. To handle the noise in the consistency loss, we further propose a learned, output refinement network, which takes the initial predictions, the loss, and the gradient as input, and efficiently predicts a correlated output update. We demonstrate with extensive experiments that the proposed model can reliably predict disparity and scene flow in many challenging scenarios, and achieves better generalization than the state-of-the-arts.
Range Conditioned Dilated Convolutions for Scale Invariant 3D Object Detection
May 20, 2020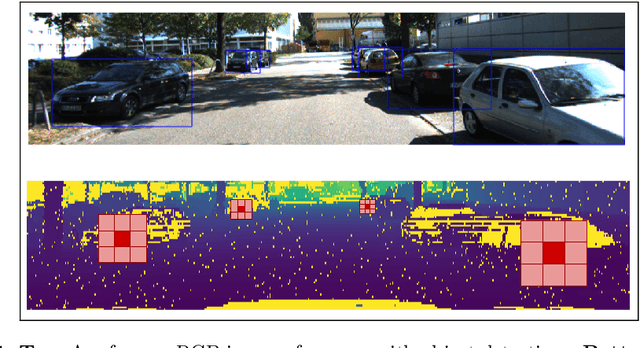

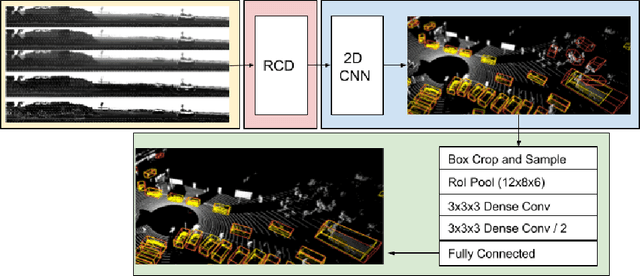
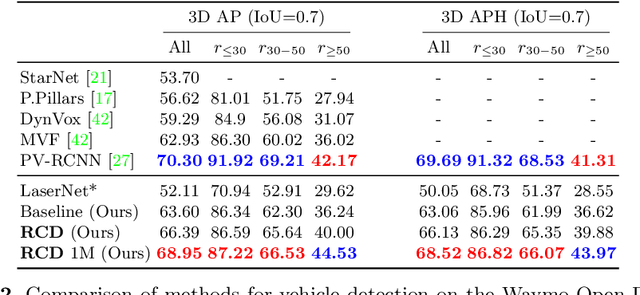
This paper presents a novel 3D object detection framework that processes LiDAR data directly on a representation of the sensor's native range images. When operating in the range image view, one faces learning challenges, including occlusion and considerable scale variation, limiting the obtainable accuracy. To address these challenges, a range-conditioned dilated block (RCD) is proposed to dynamically adjust a continuous dilation rate as a function of the measured range, achieving scale invariance. Furthermore, soft range gating helps mitigate the effect of occlusion. An end-to-end trained box-refinement network brings additional performance improvements in occluded areas, and produces more accurate bounding box predictions. On the challenging Waymo Open Dataset, our improved range-based detector outperforms state of the art at long range detection. Our framework is superior to prior multiview, voxel-based methods over all ranges, setting a new baseline for range-based 3D detection on this large scale public dataset.