 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerturbed-History Exploration in Stochastic Linear Bandits
Mar 21, 2019
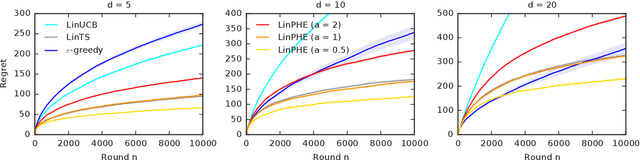
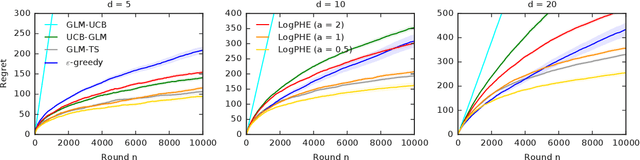
We propose a new online algorithm for minimizing the cumulative regret in stochastic linear bandits. The key idea is to build a perturbed history, which mixes the history of observed rewards with a pseudo-history of randomly generated i.i.d. pseudo-rewards. Our algorithm, perturbed-history exploration in a linear bandit (LinPHE), estimates a linear model from its perturbed history and pulls the arm with the highest value under that model. We prove a $\tilde{O}(d \sqrt{n})$ gap-free bound on the expected $n$-round regret of LinPHE, where $d$ is the number of features. Our analysis relies on novel concentration and anti-concentration bounds on the weighted sum of Bernoulli random variables. To show the generality of our design, we extend LinPHE to a logistic reward model. We evaluate both algorithms empirically and show that they are practical.
Perturbed-History Exploration in Stochastic Multi-Armed Bandits
Feb 26, 2019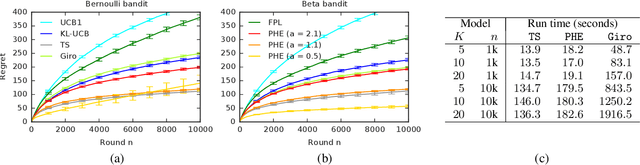
We propose an online algorithm for cumulative regret minimization in a stochastic multi-armed bandit. The algorithm adds $O(t)$ i.i.d. pseudo-rewards to its history in round $t$ and then pulls the arm with the highest estimated value in its perturbed history. Therefore, we call it perturbed-history exploration (PHE). The pseudo-rewards are designed to offset the underestimated values of arms in round $t$ with a sufficiently high probability. We analyze PHE in a $K$-armed bandit and prove a $O(K \Delta^{-1} \log n)$ bound on its $n$-round regret, where $\Delta$ is the minimum gap between the expected rewards of the optimal and suboptimal arms. The key to our analysis is a novel argument that shows that randomized Bernoulli rewards lead to optimism. We compare PHE empirically to several baselines and show that it is competitive with the best of them.
Seq2Slate: Re-ranking and Slate Optimization with RNNs
Oct 04, 2018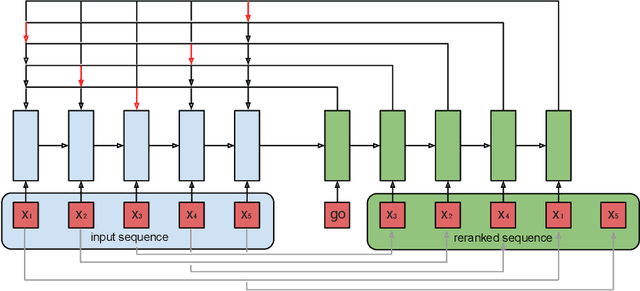
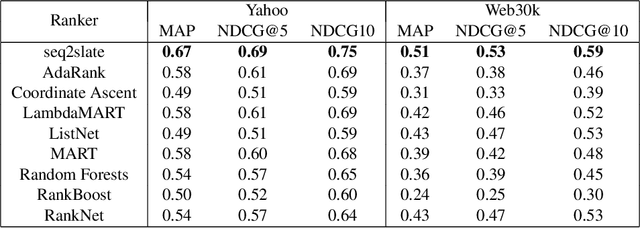

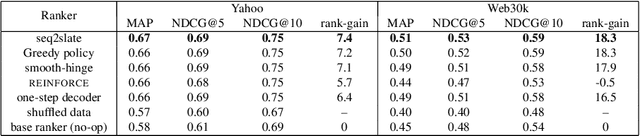
Ranking is a central task in machine learning and information retrieval. In this task, it is especially important to present the user with a slate of items that is appealing as a whole. This in turn requires taking into account interactions between items, since intuitively, placing an item on the slate affects the decision of which other items should be placed alongside it. In this work, we propose a sequence-to-sequence model for ranking called seq2slate. At each step, the model predicts the next item to place on the slate given the items already selected. The recurrent nature of the model allows complex dependencies between items to be captured directly in a flexible and scalable way. We show how to learn the model end-to-end from weak supervision in the form of easily obtained click-through data. We further demonstrate the usefulness of our approach in experiments on standard ranking benchmarks as well as in a real-world recommendation system.
Planning and Learning with Stochastic Action Sets
May 07, 2018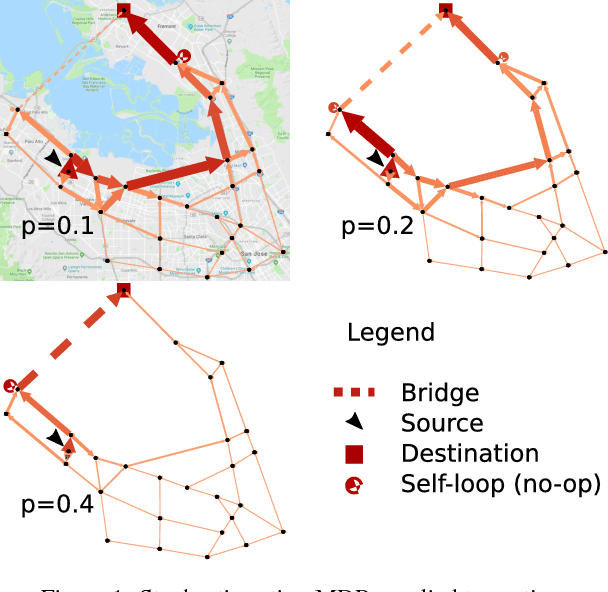
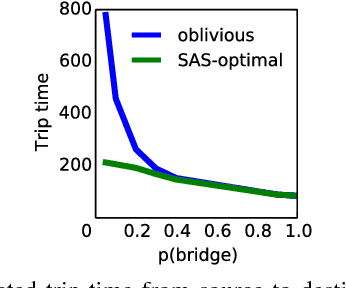
In many practical uses of reinforcement learning (RL) the set of actions available at a given state is a random variable, with realizations governed by an exogenous stochastic process. Somewhat surprisingly, the foundations for such sequential decision processes have been unaddressed. In this work, we formalize and investigate MDPs with stochastic action sets (SAS-MDPs) to provide these foundations. We show that optimal policies and value functions in this model have a structure that admits a compact representation. From an RL perspective, we show that Q-learning with sampled action sets is sound. In model-based settings, we consider two important special cases: when individual actions are available with independent probabilities; and a sampling-based model for unknown distributions. We develop poly-time value and policy iteration methods for both cases; and in the first, we offer a poly-time linear programming solution.
Safe Exploration for Identifying Linear Systems via Robust Optimization
Nov 30, 2017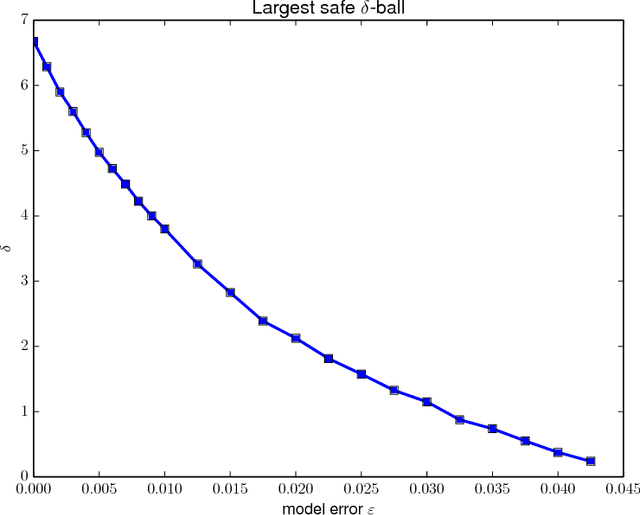
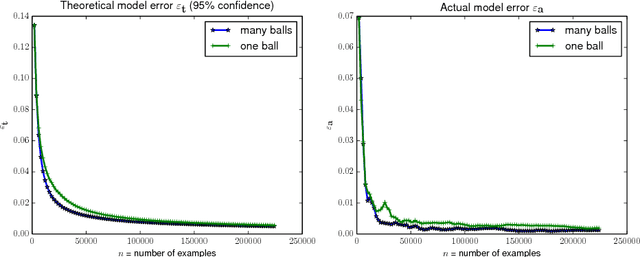
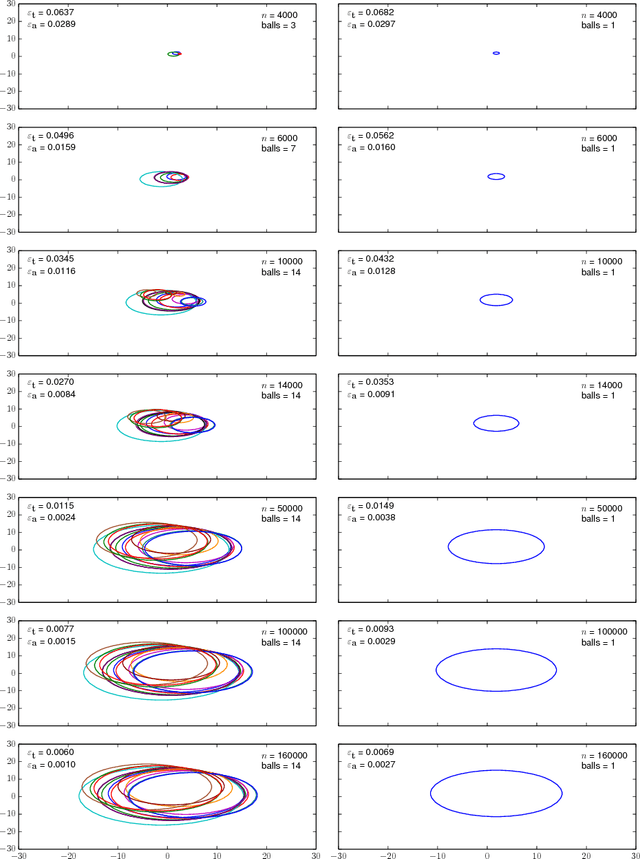
Safely exploring an unknown dynamical system is critical to the deployment of reinforcement learning (RL) in physical systems where failures may have catastrophic consequences. In scenarios where one knows little about the dynamics, diverse transition data covering relevant regions of state-action space is needed to apply either model-based or model-free RL. Motivated by the cooling of Google's data centers, we study how one can safely identify the parameters of a system model with a desired accuracy and confidence level. In particular, we focus on learning an unknown linear system with Gaussian noise assuming only that, initially, a nominal safe action is known. Define safety as satisfying specific linear constraints on the state space (e.g., requirements on process variable) that must hold over the span of an entire trajectory, and given a Probably Approximately Correct (PAC) style bound on the estimation error of model parameters, we show how to compute safe regions of action space by gradually growing a ball around the nominal safe action. One can apply any exploration strategy where actions are chosen from such safe regions. Experiments on a stylized model of data center cooling dynamics show how computing proper safe regions can increase the sample efficiency of safe exploration.
Proceedings of the Sixteenth Conference on Uncertainty in Artificial Intelligence (2000)
Aug 28, 2014This is the Proceedings of the Sixteenth Conference on Uncertainty in Artificial Intelligence, which was held in San Francisco, CA, June 30 - July 3, 2000
Structured Reachability Analysis for Markov Decision Processes
Apr 23, 2013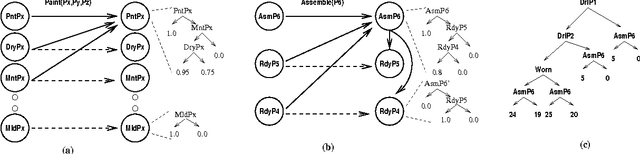
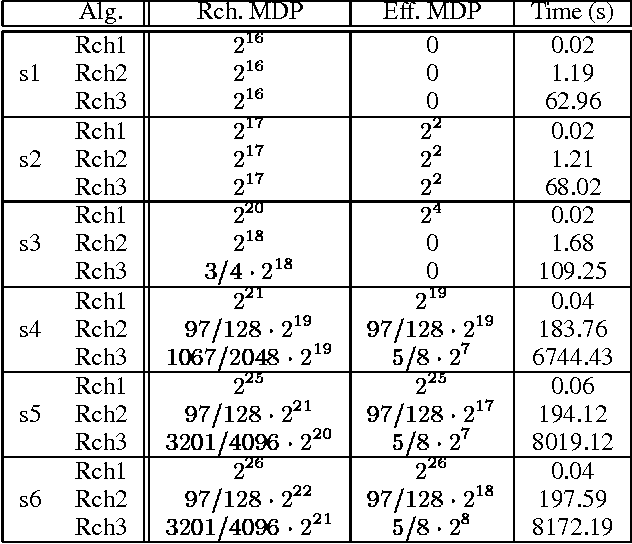
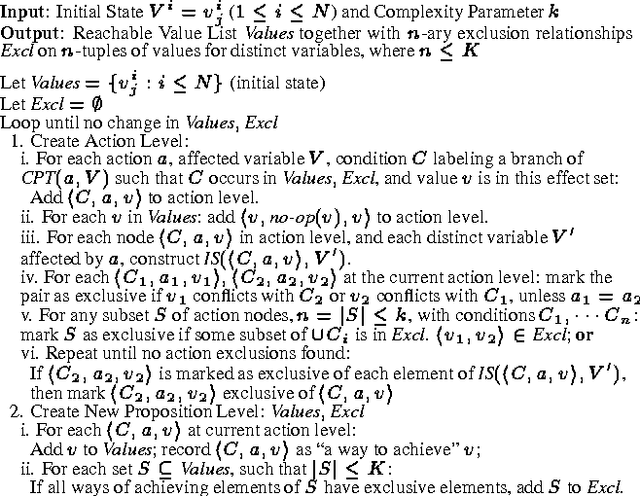
Recent research in decision theoretic planning has focussed on making the solution of Markov decision processes (MDPs) more feasible. We develop a family of algorithms for structured reachability analysis of MDPs that are suitable when an initial state (or set of states) is known. Using compact, structured representations of MDPs (e.g., Bayesian networks), our methods, which vary in the tradeoff between complexity and accuracy, produce structured descriptions of (estimated) reachable states that can be used to eliminate variables or variable values from the problem description, reducing the size of the MDP and making it easier to solve. One contribution of our work is the extension of ideas from GRAPHPLAN to deal with the distributed nature of action representations typically embodied within Bayes nets and the problem of correlated action effects. We also demonstrate that our algorithm can be made more complete by using k-ary constraints instead of binary constraints. Another contribution is the illustration of how the compact representation of reachability constraints can be exploited by several existing (exact and approximate) abstraction algorithms for MDPs.
Modal Logics for Qualitative Possibility and Beliefs
Mar 13, 2013
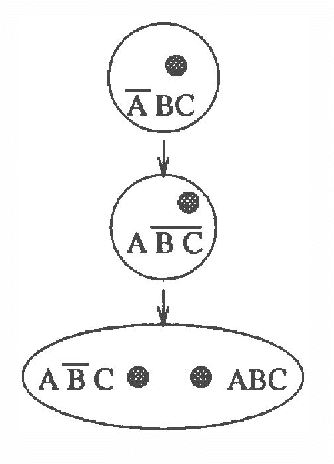
Possibilistic logic has been proposed as a numerical formalism for reasoning with uncertainty. There has been interest in developing qualitative accounts of possibility, as well as an explanation of the relationship between possibility and modal logics. We present two modal logics that can be used to represent and reason with qualitative statements of possibility and necessity. Within this modal framework, we are able to identify interesting relationships between possibilistic logic, beliefs and conditionals. In particular, the most natural conditional definable via possibilistic means for default reasoning is identical to Pearl's conditional for e-semantics.
The Probability of a Possibility: Adding Uncertainty to Default Rules
Mar 06, 2013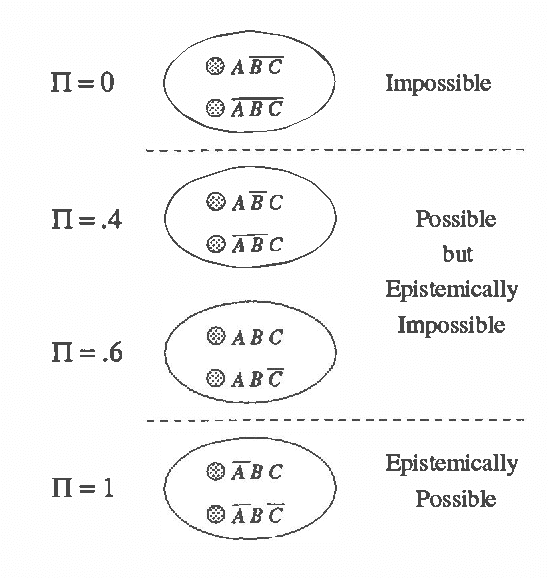
We present a semantics for adding uncertainty to conditional logics for default reasoning and belief revision. We are able to treat conditional sentences as statements of conditional probability, and express rules for revision such as "If A were believed, then B would be believed to degree p." This method of revision extends conditionalization by allowing meaningful revision by sentences whose probability is zero. This is achieved through the use of counterfactual probabilities. Thus, our system accounts for the best properties of qualitative methods of update (in particular, the AGM theory of revision) and probabilistic methods. We also show how our system can be viewed as a unification of probability theory and possibility theory, highlighting their orthogonality and providing a means for expressing the probability of a possibility. We also demonstrate the connection to Lewis's method of imaging.
Integrating Planning and Execution in Stochastic Domains
Feb 27, 2013
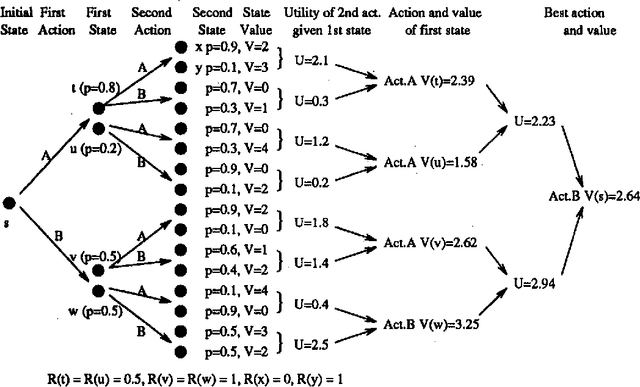
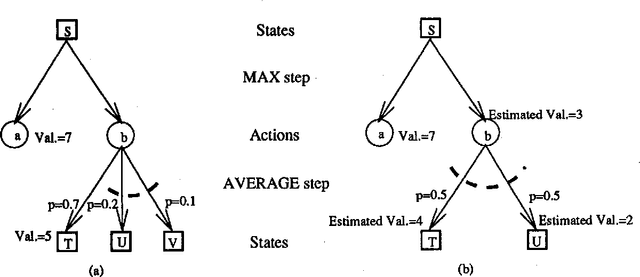
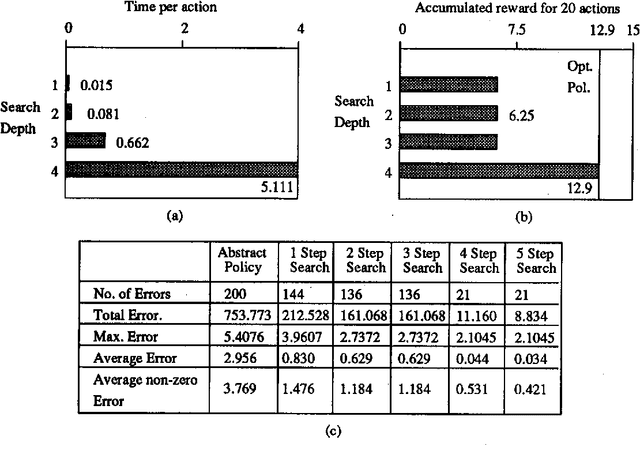
We investigate planning in time-critical domains represented as Markov Decision Processes, showing that search based techniques can be a very powerful method for finding close to optimal plans. To reduce the computational cost of planning in these domains, we execute actions as we construct the plan, and sacrifice optimality by searching to a fixed depth and using a heuristic function to estimate the value of states. Although this paper concentrates on the search algorithm, we also discuss ways of constructing heuristic functions suitable for this approach. Our results show that by interleaving search and execution, close to optimal policies can be found without the computational requirements of other approaches.