 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConQUR: Mitigating Delusional Bias in Deep Q-learning
Feb 27, 2020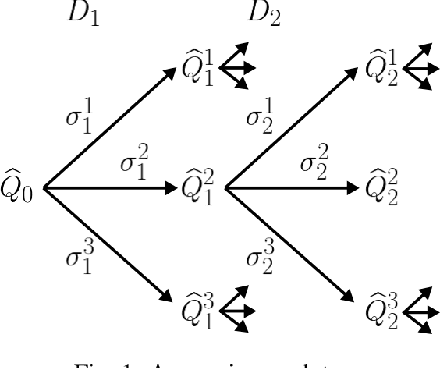
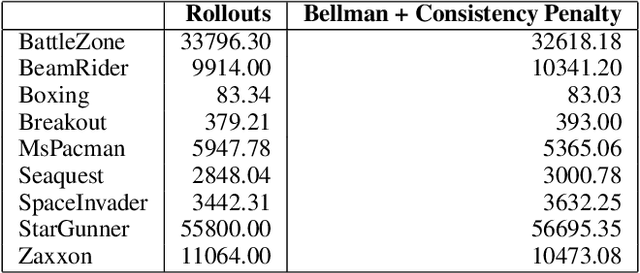
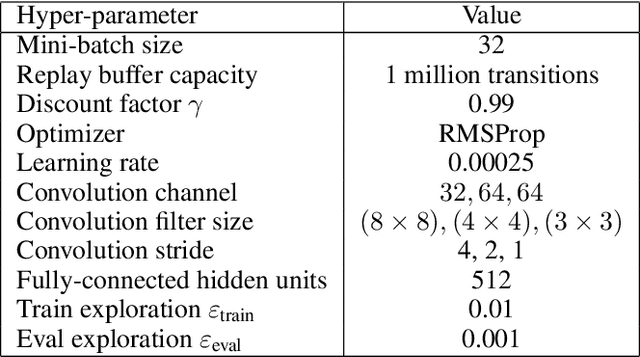
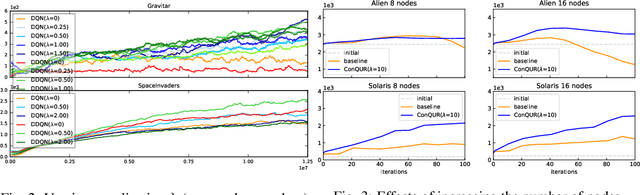
Delusional bias is a fundamental source of error in approximate Q-learning. To date, the only techniques that explicitly address delusion require comprehensive search using tabular value estimates. In this paper, we develop efficient methods to mitigate delusional bias by training Q-approximators with labels that are "consistent" with the underlying greedy policy class. We introduce a simple penalization scheme that encourages Q-labels used across training batches to remain (jointly) consistent with the expressible policy class. We also propose a search framework that allows multiple Q-approximators to be generated and tracked, thus mitigating the effect of premature (implicit) policy commitments. Experimental results demonstrate that these methods can improve the performance of Q-learning in a variety of Atari games, sometimes dramatically.
Differentiable Bandit Exploration
Feb 17, 2020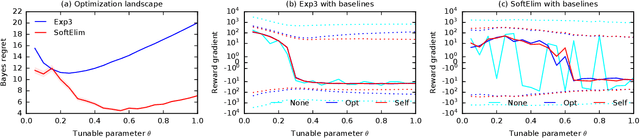
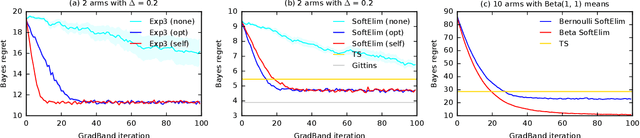
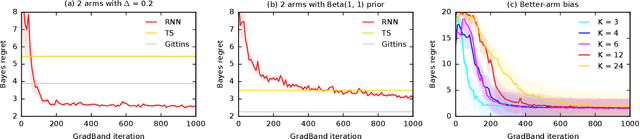
We learn bandit policies that maximize the average reward over bandit instances drawn from an unknown distribution $\mathcal{P}$, from a sample from $\mathcal{P}$. Our approach is an instance of meta-learning and its appeal is that the properties of $\mathcal{P}$ can be exploited without restricting it. We parameterize our policies in a differentiable way and optimize them by policy gradients - an approach that is easy to implement and pleasantly general. Then the challenge is to design effective gradient estimators and good policy classes. To make policy gradients practical, we introduce novel variance reduction techniques. We experiment with various bandit policy classes, including neural networks and a novel soft-elimination policy. The latter has regret guarantees and is a natural starting point for our optimization. Our experiments highlight the versatility of our approach. We also observe that neural network policies can learn implicit biases, which are only expressed through sampled bandit instances during training.
Data Efficient Training for Reinforcement Learning with Adaptive Behavior Policy Sharing
Feb 12, 2020
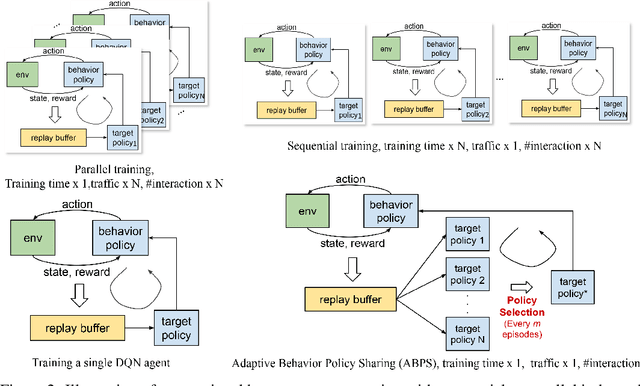
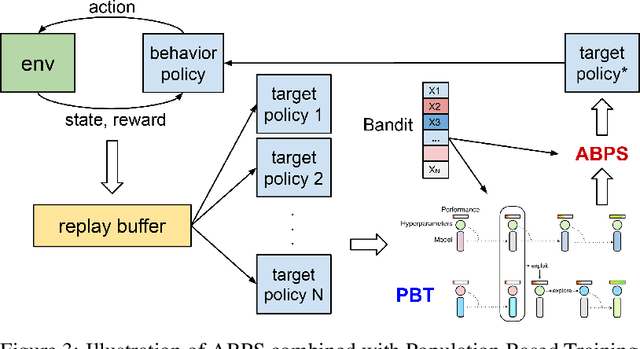
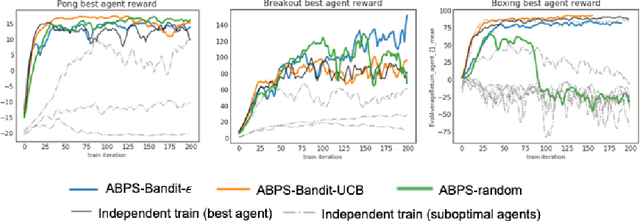
Deep Reinforcement Learning (RL) is proven powerful for decision making in simulated environments. However, training deep RL model is challenging in real world applications such as production-scale health-care or recommender systems because of the expensiveness of interaction and limitation of budget at deployment. One aspect of the data inefficiency comes from the expensive hyper-parameter tuning when optimizing deep neural networks. We propose Adaptive Behavior Policy Sharing (ABPS), a data-efficient training algorithm that allows sharing of experience collected by behavior policy that is adaptively selected from a pool of agents trained with an ensemble of hyper-parameters. We further extend ABPS to evolve hyper-parameters during training by hybridizing ABPS with an adapted version of Population Based Training (ABPS-PBT). We conduct experiments with multiple Atari games with up to 16 hyper-parameter/architecture setups. ABPS achieves superior overall performance, reduced variance on top 25% agents, and equivalent performance on the best agent compared to conventional hyper-parameter tuning with independent training, even though ABPS only requires the same number of environmental interactions as training a single agent. We also show that ABPS-PBT further improves the convergence speed and reduces the variance.
BRPO: Batch Residual Policy Optimization
Feb 08, 2020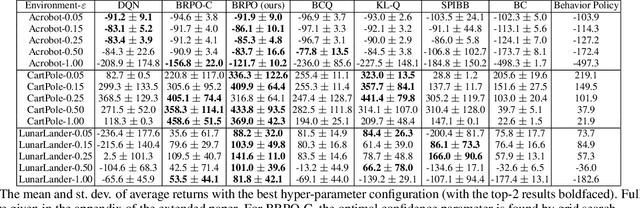

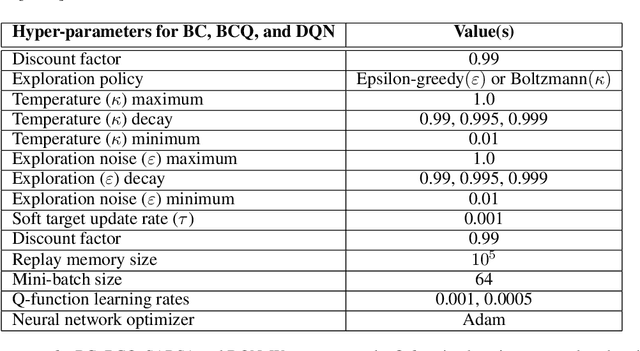
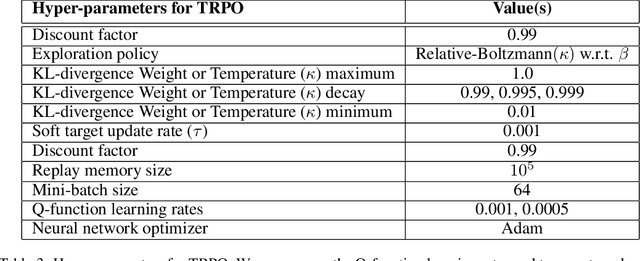
In batch reinforcement learning (RL), one often constrains a learned policy to be close to the behavior (data-generating) policy, e.g., by constraining the learned action distribution to differ from the behavior policy by some maximum degree that is the same at each state. This can cause batch RL to be overly conservative, unable to exploit large policy changes at frequently-visited, high-confidence states without risking poor performance at sparsely-visited states. To remedy this, we propose residual policies, where the allowable deviation of the learned policy is state-action-dependent. We derive a new for RL method, BRPO, which learns both the policy and allowable deviation that jointly maximize a lower bound on policy performance. We show that BRPO achieves the state-of-the-art performance in a number of tasks.
Gradient-based Optimization for Bayesian Preference Elicitation
Nov 20, 2019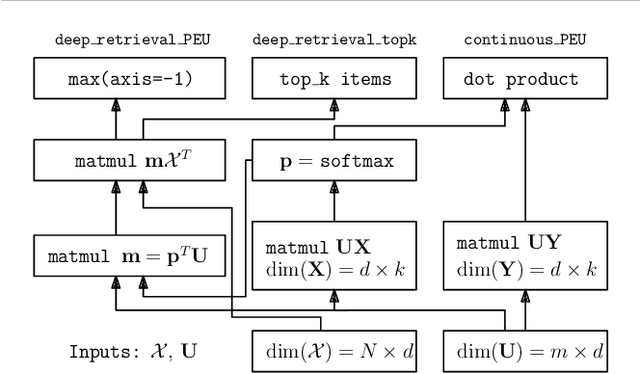

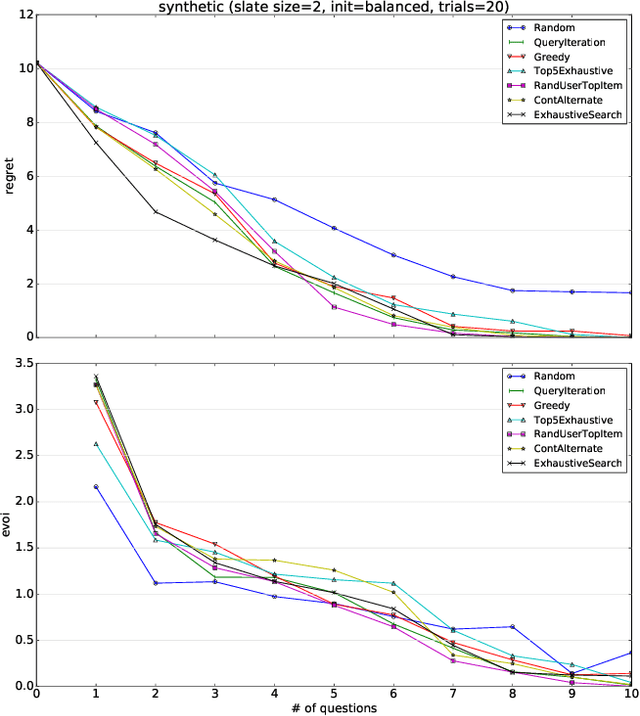
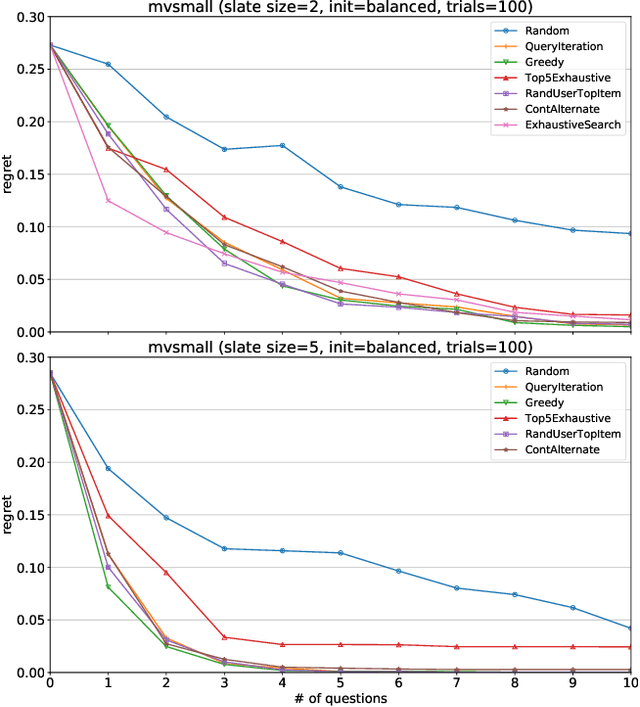
Effective techniques for eliciting user preferences have taken on added importance as recommender systems (RSs) become increasingly interactive and conversational. A common and conceptually appealing Bayesian criterion for selecting queries is expected value of information (EVOI). Unfortunately, it is computationally prohibitive to construct queries with maximum EVOI in RSs with large item spaces. We tackle this issue by introducing a continuous formulation of EVOI as a differentiable network that can be optimized using gradient methods available in modern machine learning (ML) computational frameworks (e.g., TensorFlow, PyTorch). We exploit this to develop a novel, scalable Monte Carlo method for EVOI optimization, which is more scalable for large item spaces than methods requiring explicit enumeration of items. While we emphasize the use of this approach for pairwise (or k-wise) comparisons of items, we also demonstrate how our method can be adapted to queries involving subsets of item attributes or "partial items," which are often more cognitively manageable for users. Experiments show that our gradient-based EVOI technique achieves state-of-the-art performance across several domains while scaling to large item spaces.
CAQL: Continuous Action Q-Learning
Oct 09, 2019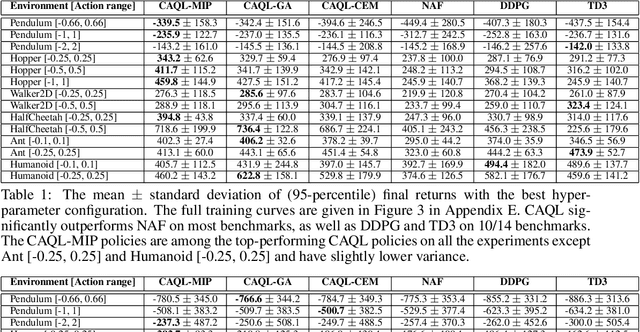
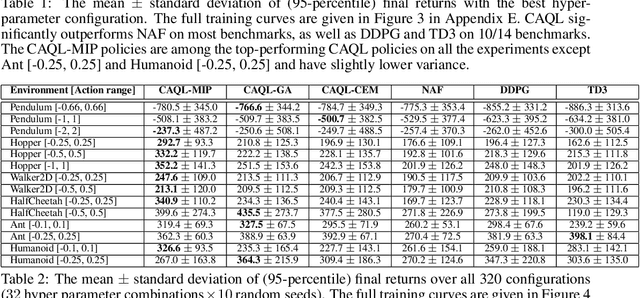
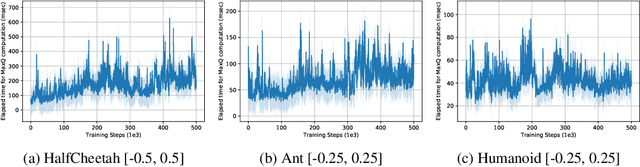
Value-based reinforcement learning (RL) methods like Q-learning have shown success in a variety of domains. One challenge in applying Q-learning to continuous-action RL problems, however, is the continuous action maximization (max-Q) required for optimal Bellman backup. In this work, we develop CAQL, a (class of) algorithm(s) for continuous-action Q-learning that can use several plug-and-play optimizers for the max-Q problem. Leveraging recent optimization results for deep neural networks, we show that max-Q can be solved optimally using mixed-integer programming (MIP). When the Q-function representation has sufficient power, MIP-based optimization gives rise to better policies and is more robust than approximate methods (e.g., gradient ascent, cross-entropy search). We further develop several techniques to accelerate inference in CAQL, which despite their approximate nature, perform well. We compare CAQL with state-of-the-art RL algorithms on benchmark continuous-control problems that have different degrees of action constraints and show that CAQL outperforms policy-based methods in heavily constrained environments, often dramatically.
RecSim: A Configurable Simulation Platform for Recommender Systems
Sep 26, 2019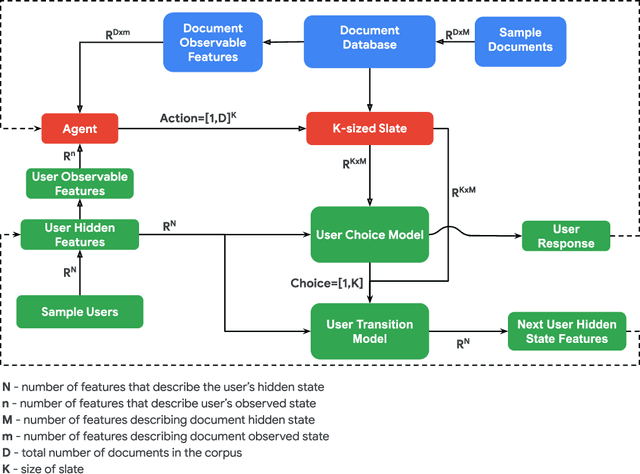
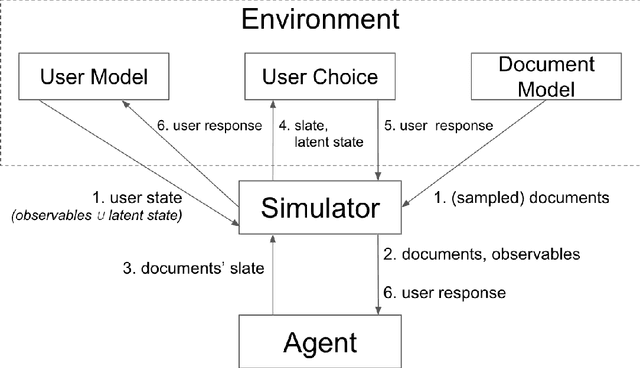
We propose RecSim, a configurable platform for authoring simulation environments for recommender systems (RSs) that naturally supports sequential interaction with users. RecSim allows the creation of new environments that reflect particular aspects of user behavior and item structure at a level of abstraction well-suited to pushing the limits of current reinforcement learning (RL) and RS techniques in sequential interactive recommendation problems. Environments can be easily configured that vary assumptions about: user preferences and item familiarity; user latent state and its dynamics; and choice models and other user response behavior. We outline how RecSim offers value to RL and RS researchers and practitioners, and how it can serve as a vehicle for academic-industrial collaboration.
Randomized Exploration in Generalized Linear Bandits
Jun 21, 2019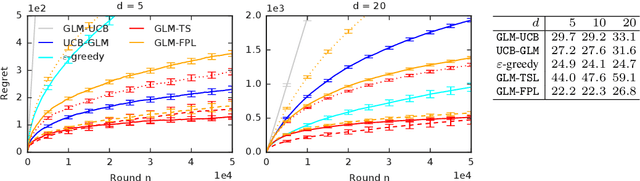
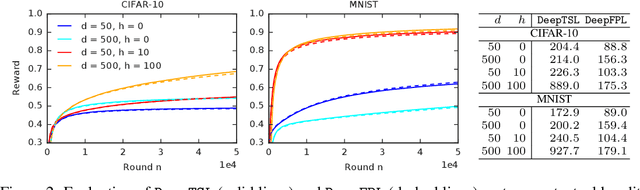
We study two randomized algorithms for generalized linear bandits, GLM-TSL and GLM-FPL. GLM-TSL samples a generalized linear model (GLM) from the Laplace approximation to the posterior distribution. GLM-FPL, a new algorithm proposed in this work, fits a GLM to a randomly perturbed history of past rewards. We prove a $\tilde{O}(d \sqrt{n} + d^2)$ upper bound on the $n$-round regret of GLM-TSL, where $d$ is the number of features. This is the first regret bound of a Thompson sampling-like algorithm in GLM bandits where the leading term is $\tilde{O}(d \sqrt{n})$. We apply both GLM-TSL and GLM-FPL to logistic and neural network bandits, and show that they perform well empirically. In more complex models, GLM-FPL is significantly faster. Our results showcase the role of randomization, beyond posterior sampling, in exploration.
Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology
May 31, 2019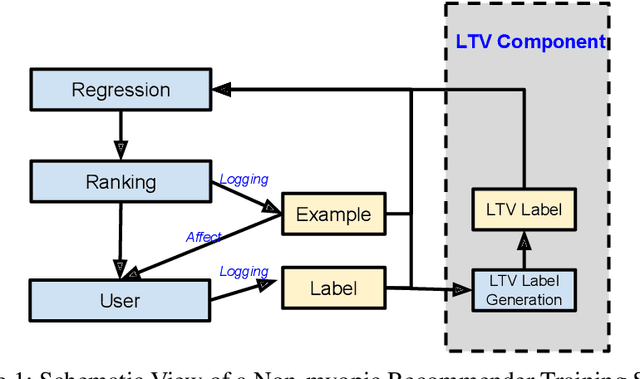
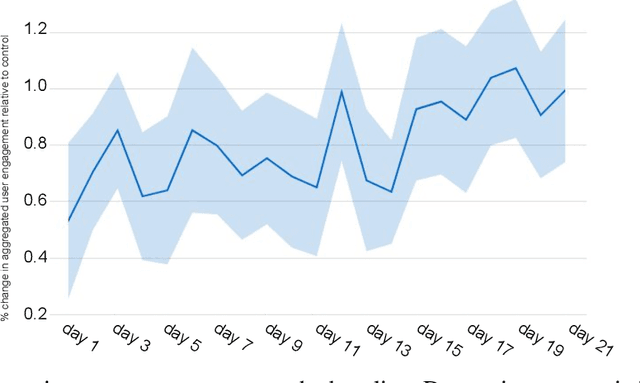
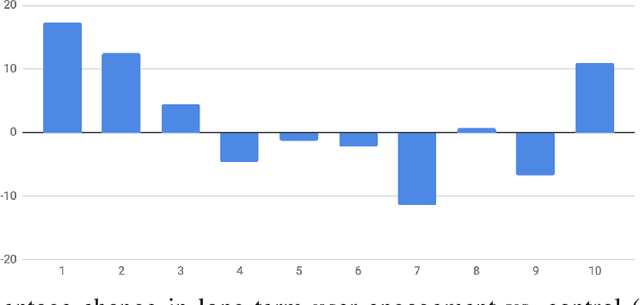
Most practical recommender systems focus on estimating immediate user engagement without considering the long-term effects of recommendations on user behavior. Reinforcement learning (RL) methods offer the potential to optimize recommendations for long-term user engagement. However, since users are often presented with slates of multiple items - which may have interacting effects on user choice - methods are required to deal with the combinatorics of the RL action space. In this work, we address the challenge of making slate-based recommendations to optimize long-term value using RL. Our contributions are three-fold. (i) We develop SLATEQ, a decomposition of value-based temporal-difference and Q-learning that renders RL tractable with slates. Under mild assumptions on user choice behavior, we show that the long-term value (LTV) of a slate can be decomposed into a tractable function of its component item-wise LTVs. (ii) We outline a methodology that leverages existing myopic learning-based recommenders to quickly develop a recommender that handles LTV. (iii) We demonstrate our methods in simulation, and validate the scalability of decomposed TD-learning using SLATEQ in live experiments on YouTube.
Advantage Amplification in Slowly Evolving Latent-State Environments
May 29, 2019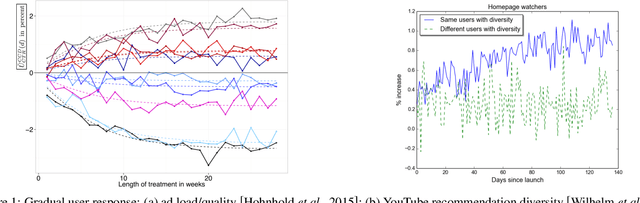
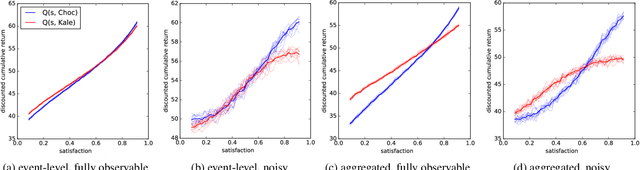
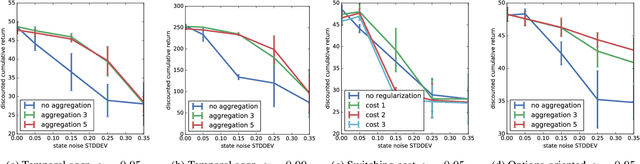
Latent-state environments with long horizons, such as those faced by recommender systems, pose significant challenges for reinforcement learning (RL). In this work, we identify and analyze several key hurdles for RL in such environments, including belief state error and small action advantage. We develop a general principle of advantage amplification that can overcome these hurdles through the use of temporal abstraction. We propose several aggregation methods and prove they induce amplification in certain settings. We also bound the loss in optimality incurred by our methods in environments where latent state evolves slowly and demonstrate their performance empirically in a stylized user-modeling task.