 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale
Jan 14, 2022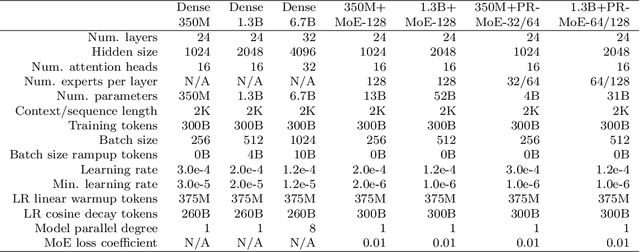
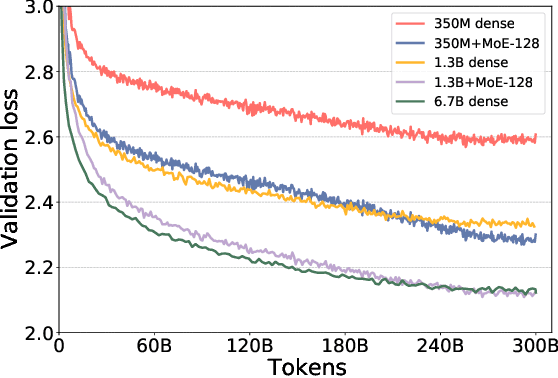
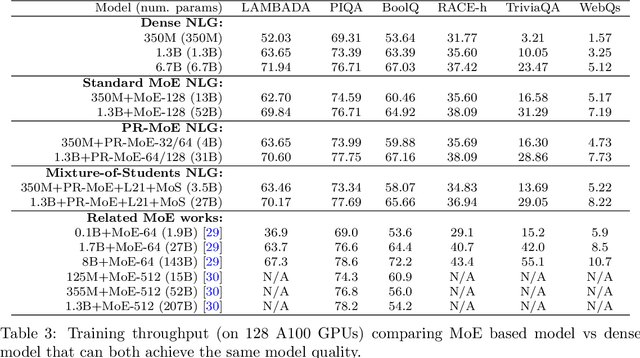
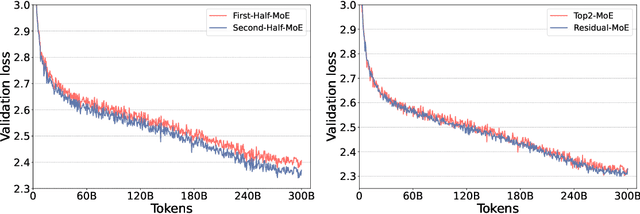
As the training of giant dense models hits the boundary on the availability and capability of the hardware resources today, Mixture-of-Experts (MoE) models become one of the most promising model architectures due to their significant training cost reduction compared to a quality-equivalent dense model. Its training cost saving is demonstrated from encoder-decoder models (prior works) to a 5x saving for auto-aggressive language models (this work along with parallel explorations). However, due to the much larger model size and unique architecture, how to provide fast MoE model inference remains challenging and unsolved, limiting its practical usage. To tackle this, we present DeepSpeed-MoE, an end-to-end MoE training and inference solution as part of the DeepSpeed library, including novel MoE architecture designs and model compression techniques that reduce MoE model size by up to 3.7x, and a highly optimized inference system that provides 7.3x better latency and cost compared to existing MoE inference solutions. DeepSpeed-MoE offers an unprecedented scale and efficiency to serve massive MoE models with up to 4.5x faster and 9x cheaper inference compared to quality-equivalent dense models. We hope our innovations and systems help open a promising path to new directions in the large model landscape, a shift from dense to sparse MoE models, where training and deploying higher-quality models with fewer resources becomes more widely possible.
Curriculum Learning: A Regularization Method for Efficient and Stable Billion-Scale GPT Model Pre-Training
Aug 13, 2021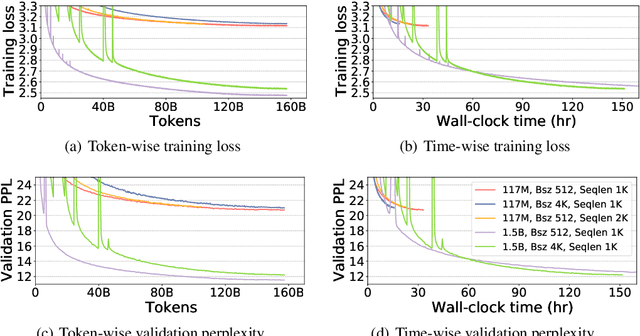
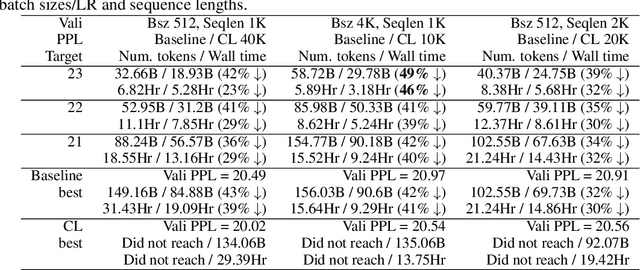
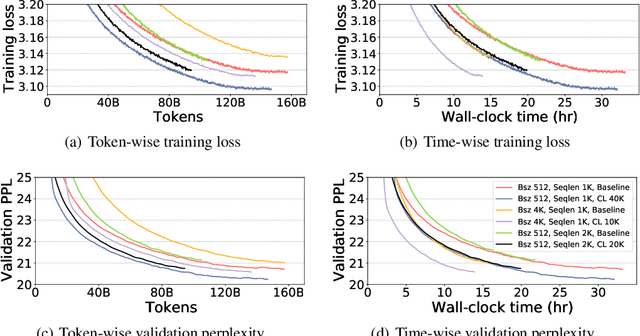
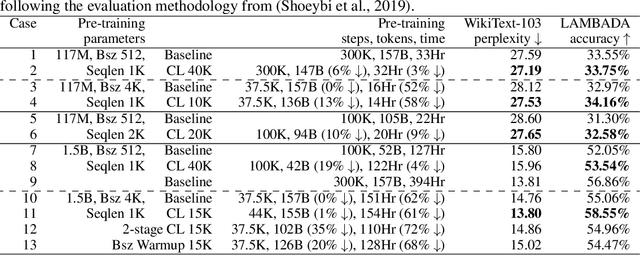
Recent works have demonstrated great success in training high-capacity autoregressive language models (GPT, GPT-2, GPT-3) on a huge amount of unlabeled text corpus for text generation. Despite showing great results, this generates two training efficiency challenges. First, training large corpora can be extremely timing consuming, and how to present training samples to the model to improve the token-wise convergence speed remains a challenging and open question. Second, many of these large models have to be trained with hundreds or even thousands of processors using data-parallelism with a very large batch size. Despite of its better compute efficiency, it has been observed that large-batch training often runs into training instability issue or converges to solutions with bad generalization performance. To overcome these two challenges, we present a study of a curriculum learning based approach, which helps improves the pre-training convergence speed of autoregressive models. More importantly, we find that curriculum learning, as a regularization method, exerts a gradient variance reduction effect and enables to train autoregressive models with much larger batch sizes and learning rates without training instability, further improving the training speed. Our evaluations demonstrate that curriculum learning enables training GPT-2 models (with up to 1.5B parameters) with 8x larger batch size and 4x larger learning rate, whereas the baseline approach struggles with training divergence. To achieve the same validation perplexity targets during pre-training, curriculum learning reduces the required number of tokens and wall clock time by up to 59% and 54%, respectively. To achieve the same or better zero-shot WikiText-103/LAMBADA evaluation results at the end of pre-training, curriculum learning reduces the required number of tokens and wall clock time by up to 13% and 61%, respectively.
1-bit LAMB: Communication Efficient Large-Scale Large-Batch Training with LAMB's Convergence Speed
Apr 13, 2021
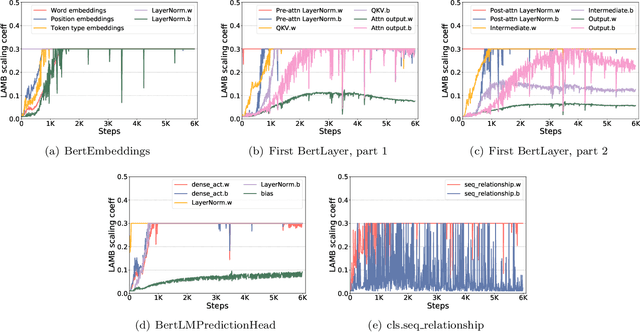
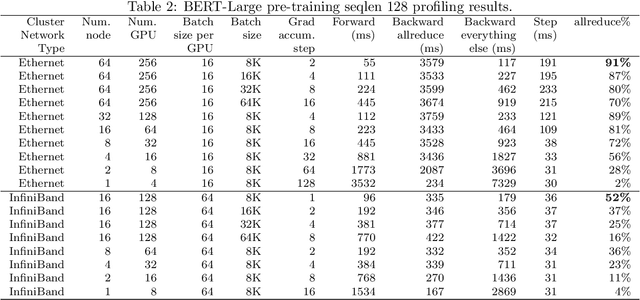
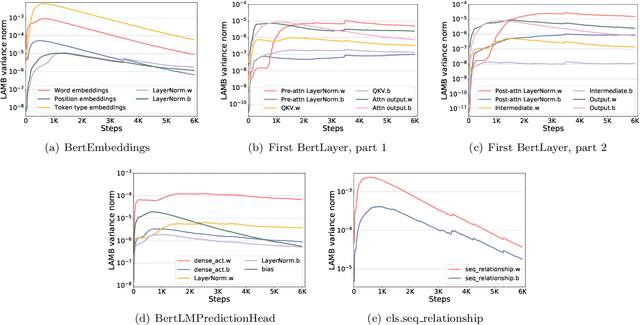
To train large models (like BERT and GPT-3) with hundreds or even thousands of GPUs, the communication has become a major bottleneck, especially on commodity systems with limited-bandwidth TCP interconnects network. On one side large-batch optimization such as LAMB algorithm was proposed to reduce the number of communications. On the other side, communication compression algorithms such as 1-bit SGD and 1-bit Adam help to reduce the volume of each communication. However, we find that simply using one of the techniques is not sufficient to solve the communication challenge, especially on low-bandwidth Ethernet networks. Motivated by this we aim to combine the power of large-batch optimization and communication compression, but we find that existing compression strategies cannot be directly applied to LAMB due to its unique adaptive layerwise learning rates. To this end, we design a new communication-efficient algorithm, 1-bit LAMB, which introduces a novel way to support adaptive layerwise learning rates even when communication is compressed. In addition, we introduce a new system implementation for compressed communication using the NCCL backend of PyTorch distributed, which improves both usability and performance compared to existing MPI-based implementation. For BERT-Large pre-training task with batch sizes from 8K to 64K, our evaluations on up to 256 GPUs demonstrate that 1-bit LAMB with NCCL-based backend is able to achieve up to 4.6x communication volume reduction, up to 2.8x end-to-end speedup (in terms of number of training samples per second), and the same convergence speed (in terms of number of pre-training samples to reach the same accuracy on fine-tuning tasks) compared to uncompressed LAMB.
1-bit Adam: Communication Efficient Large-Scale Training with Adam's Convergence Speed
Feb 04, 2021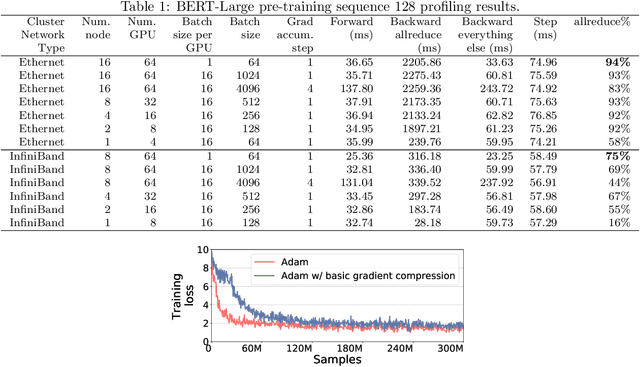
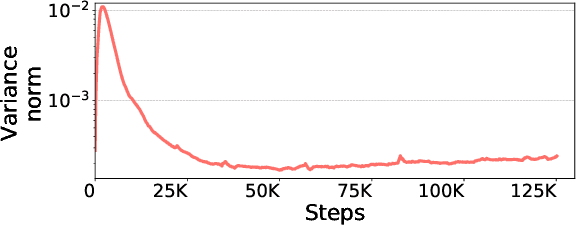
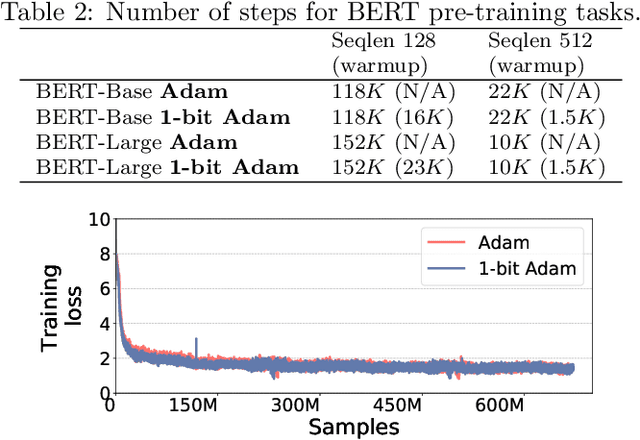

Scalable training of large models (like BERT and GPT-3) requires careful optimization rooted in model design, architecture, and system capabilities. From a system standpoint, communication has become a major bottleneck, especially on commodity systems with standard TCP interconnects that offer limited network bandwidth. Communication compression is an important technique to reduce training time on such systems. One of the most effective methods is error-compensated compression, which offers robust convergence speed even under 1-bit compression. However, state-of-the-art error compensation techniques only work with basic optimizers like SGD and momentum SGD, which are linearly dependent on the gradients. They do not work with non-linear gradient-based optimizers like Adam, which offer state-of-the-art convergence efficiency and accuracy for models like BERT. In this paper, we propose 1-bit Adam that reduces the communication volume by up to $5\times$, offers much better scalability, and provides the same convergence speed as uncompressed Adam. Our key finding is that Adam's variance (non-linear term) becomes stable (after a warmup phase) and can be used as a fixed precondition for the rest of the training (compression phase). Experiments on up to 256 GPUs show that 1-bit Adam enables up to $3.3\times$ higher throughput for BERT-Large pre-training and up to $2.9\times$ higher throughput for SQuAD fine-tuning. In addition, we provide theoretical analysis for our proposed work.
Scaling Video Analytics on Constrained Edge Nodes
May 24, 2019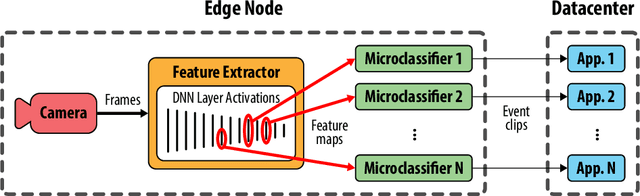
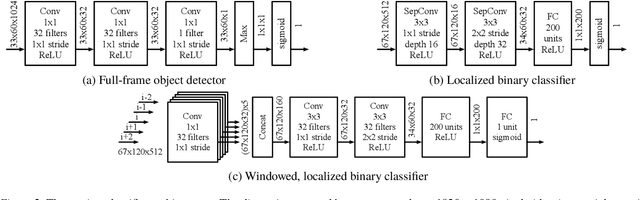


As video camera deployments continue to grow, the need to process large volumes of real-time data strains wide area network infrastructure. When per-camera bandwidth is limited, it is infeasible for applications such as traffic monitoring and pedestrian tracking to offload high-quality video streams to a datacenter. This paper presents FilterForward, a new edge-to-cloud system that enables datacenter-based applications to process content from thousands of cameras by installing lightweight edge filters that backhaul only relevant video frames. FilterForward introduces fast and expressive per-application microclassifiers that share computation to simultaneously detect dozens of events on computationally constrained edge nodes. Only matching events are transmitted to the cloud. Evaluation on two real-world camera feed datasets shows that FilterForward reduces bandwidth use by an order of magnitude while improving computational efficiency and event detection accuracy for challenging video content.