 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAny 3D Scene is Worth 1K Tokens: 3D-Grounded Representation for Scene Generation at Scale
Apr 13, 20263D scene generation has long been dominated by 2D multi-view or video diffusion models. This is due not only to the lack of scene-level 3D latent representation, but also to the fact that most scene-level 3D visual data exists in the form of multi-view images or videos, which are naturally compatible with 2D diffusion architectures. Typically, these 2D-based approaches degrade 3D spatial extrapolation to 2D temporal extension, which introduces two fundamental issues: (i) representing 3D scenes via 2D views leads to significant representation redundancy, and (ii) latent space rooted in 2D inherently limits the spatial consistency of the generated 3D scenes. In this paper, we propose, for the first time, to perform 3D scene generation directly within an implicit 3D latent space to address these limitations. First, we repurpose frozen 2D representation encoders to construct our 3D Representation Autoencoder (3DRAE), which grounds view-coupled 2D semantic representations into a view-decoupled 3D latent representation. This enables representing 3D scenes observed from arbitrary numbers of views--at any resolution and aspect ratio--with fixed complexity and rich semantics. Then we introduce 3D Diffusion Transformer (3DDiT), which performs diffusion modeling in this 3D latent space, achieving remarkably efficient and spatially consistent 3D scene generation while supporting diverse conditioning configurations. Moreover, since our approach directly generates a 3D scene representation, it can be decoded to images and optional point maps along arbitrary camera trajectories without requiring per-trajectory diffusion sampling pass, which is common in 2D-based approaches.
Realistic Safety-critical Scenarios Search for Autonomous Driving System via Behavior Tree
May 11, 2023The simulation-based testing of Autonomous Driving Systems (ADSs) has gained significant attention. However, current approaches often fall short of accurately assessing ADSs for two reasons: over-reliance on expert knowledge and the utilization of simplistic evaluation metrics. That leads to discrepancies between simulated scenarios and naturalistic driving environments. To address this, we propose the Matrix-Fuzzer, a behavior tree-based testing framework, to automatically generate realistic safety-critical test scenarios. Our approach involves the $log2BT$ method, which abstracts logged road-users' trajectories to behavior sequences. Furthermore, we vary the properties of behaviors from real-world driving distributions and then use an adaptive algorithm to explore the input space. Meanwhile, we design a general evaluation engine that guides the algorithm toward critical areas, thus reducing the generation of invalid scenarios. Our approach is demonstrated in our Matrix Simulator. The experimental results show that: (1) Our $log2BT$ achieves satisfactory trajectory reconstructions. (2) Our approach is able to find the most types of safety-critical scenarios, but only generating around 30% of the total scenarios compared with the baseline algorithm. Specifically, it improves the ratio of the critical violations to total scenarios and the ratio of the types to total scenarios by at least 10x and 5x, respectively, while reducing the ratio of the invalid scenarios to total scenarios by at least 58% in two case studies.
Autonomous Underwater Vehicle-Manipulator Systems Path Planning with RRTAUVMS Algorithm
Sep 11, 2021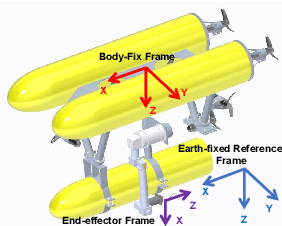

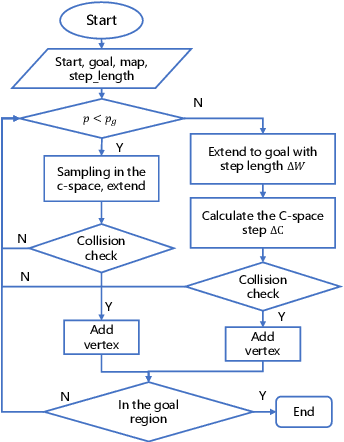

Autonomous Underwater Vehicle-Manipulator systems (AUVMS) is a new tool for ocean exploration, the AUVMS path planning problem is addressed in this paper. AUVMS is a high dimension system with a large difference in inertia distribution, also it works in a complex environment with obstacles. By integrating the rapidly-exploring random tree(RRT) algorithm with the AUVMS kinematics model, the proposed RRTAUVMS algorithm could randomly sample in the configuration space(C-Space), and also grow the tree directly towards the workspace goal in the task space. The RRTAUVMS can also deal with the redundant mapping of workspace planning goal and configuration space goal. Compared with the traditional RRT algorithm, the efficiency of the AUVMS path planning can be significantly improved.
Improving the Generalization of End-to-End Driving through Procedural Generation
Dec 26, 2020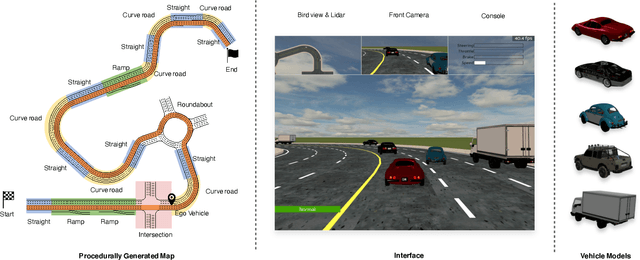

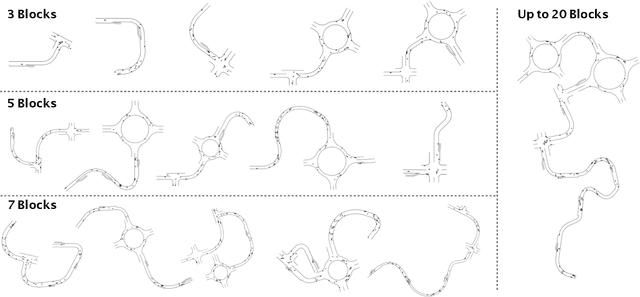
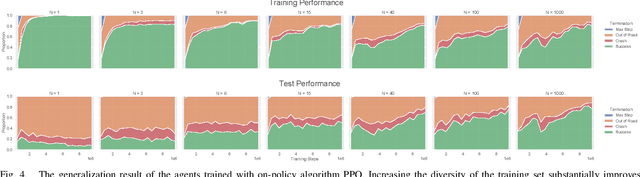
Recently there is a growing interest in the end-to-end training of autonomous driving where the entire driving pipeline from perception to control is modeled as a neural network and jointly optimized. The end-to-end driving is usually first developed and validated in simulators. However, most of the existing driving simulators only contain a fixed set of maps and a limited number of configurations. As a result the deep models are prone to overfitting training scenarios. Furthermore it is difficult to assess how well the trained models generalize to unseen scenarios. To better evaluate and improve the generalization of end-to-end driving, we introduce an open-ended and highly configurable driving simulator called PGDrive. PGDrive first defines multiple basic road blocks such as ramp, fork, and roundabout with configurable settings. Then a range of diverse maps can be assembled from those blocks with procedural generation, which are further turned into interactive environments. The experiments show that the driving agent trained by reinforcement learning on a small fixed set of maps generalizes poorly to unseen maps. We further validate that training with the increasing number of procedurally generated maps significantly improves the generalization of the agent across scenarios of different traffic densities and map structures. Code is available at: https://decisionforce.github.io/pgdrive