 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNC-Reg : Neural Cortical Maps for Rigid Registration
Jan 26, 2026We introduce neural cortical maps, a continuous and compact neural representation for cortical feature maps, as an alternative to traditional discrete structures such as grids and meshes. It can learn from meshes of arbitrary size and provide learnt features at any resolution. Neural cortical maps enable efficient optimization on the sphere and achieve runtimes up to 30 times faster than classic barycentric interpolation (for the same number of iterations). As a proof of concept, we investigate rigid registration of cortical surfaces and propose NC-Reg, a novel iterative algorithm that involves the use of neural cortical feature maps, gradient descent optimization and a simulated annealing strategy. Through ablation studies and subject-to-template experiments, our method demonstrates sub-degree accuracy ($<1^\circ$ from the global optimum), and serves as a promising robust pre-alignment strategy, which is critical in clinical settings.
VAE with Hyperspherical Coordinates: Improving Anomaly Detection from Hypervolume-Compressed Latent Space
Jan 25, 2026Variational autoencoders (VAE) encode data into lower-dimensional latent vectors before decoding those vectors back to data. Once trained, one can hope to detect out-of-distribution (abnormal) latent vectors, but several issues arise when the latent space is high dimensional. This includes an exponential growth of the hypervolume with the dimension, which severely affects the generative capacity of the VAE. In this paper, we draw insights from high dimensional statistics: in these regimes, the latent vectors of a standard VAE are distributed on the `equators' of a hypersphere, challenging the detection of anomalies. We propose to formulate the latent variables of a VAE using hyperspherical coordinates, which allows compressing the latent vectors towards a given direction on the hypersphere, thereby allowing for a more expressive approximate posterior. We show that this improves both the fully unsupervised and OOD anomaly detection ability of the VAE, achieving the best performance on the datasets we considered, outperforming existing methods. For the unsupervised and OOD modalities, respectively, these are: i) detecting unusual landscape from the Mars Rover camera and unusual Galaxies from ground based imagery (complex, real world datasets); ii) standard benchmarks like Cifar10 and subsets of ImageNet as the in-distribution (ID) class.
Multi-View Consistent Wound Segmentation With Neural Fields
Jan 23, 2026Wound care is often challenged by the economic and logistical burdens that consistently afflict patients and hospitals worldwide. In recent decades, healthcare professionals have sought support from computer vision and machine learning algorithms. In particular, wound segmentation has gained interest due to its ability to provide professionals with fast, automatic tissue assessment from standard RGB images. Some approaches have extended segmentation to 3D, enabling more complete and precise healing progress tracking. However, inferring multi-view consistent 3D structures from 2D images remains a challenge. In this paper, we evaluate WoundNeRF, a NeRF SDF-based method for estimating robust wound segmentations from automatically generated annotations. We demonstrate the potential of this paradigm in recovering accurate segmentations by comparing it against state-of-the-art Vision Transformer networks and conventional rasterisation-based algorithms. The code will be released to facilitate further development in this promising paradigm.
DIS2: Disentanglement Meets Distillation with Classwise Attention for Robust Remote Sensing Segmentation under Missing Modalities
Jan 20, 2026The efficacy of multimodal learning in remote sensing (RS) is severely undermined by missing modalities. The challenge is exacerbated by the RS highly heterogeneous data and huge scale variation. Consequently, paradigms proven effective in other domains often fail when confronted with these unique data characteristics. Conventional disentanglement learning, which relies on significant feature overlap between modalities (modality-invariant), is insufficient for this heterogeneity. Similarly, knowledge distillation becomes an ill-posed mimicry task where a student fails to focus on the necessary compensatory knowledge, leaving the semantic gap unaddressed. Our work is therefore built upon three pillars uniquely designed for RS: (1) principled missing information compensation, (2) class-specific modality contribution, and (3) multi-resolution feature importance. We propose a novel method DIS2, a new paradigm shifting from modality-shared feature dependence and untargeted imitation to active, guided missing features compensation. Its core novelty lies in a reformulated synergy between disentanglement learning and knowledge distillation, termed DLKD. Compensatory features are explicitly captured which, when fused with the features of the available modality, approximate the ideal fused representation of the full-modality case. To address the class-specific challenge, our Classwise Feature Learning Module (CFLM) adaptively learn discriminative evidence for each target depending on signal availability. Both DLKD and CFLM are supported by a hierarchical hybrid fusion (HF) structure using features across resolutions to strengthen prediction. Extensive experiments validate that our proposed approach significantly outperforms state-of-the-art methods across benchmarks.
HOTFLoc++: End-to-End Hierarchical LiDAR Place Recognition, Re-Ranking, and 6-DoF Metric Localisation in Forests
Nov 12, 2025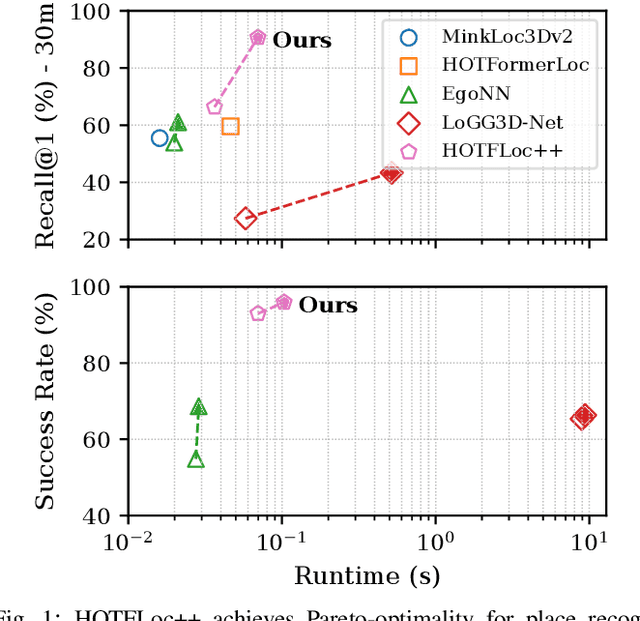
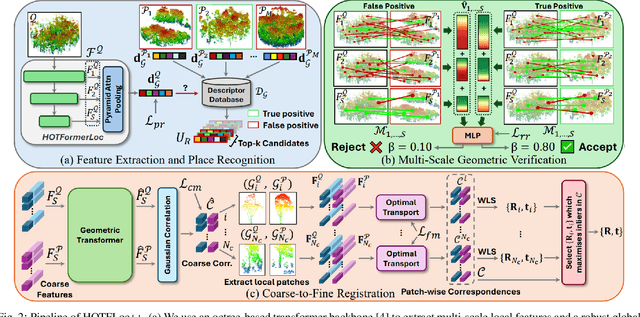
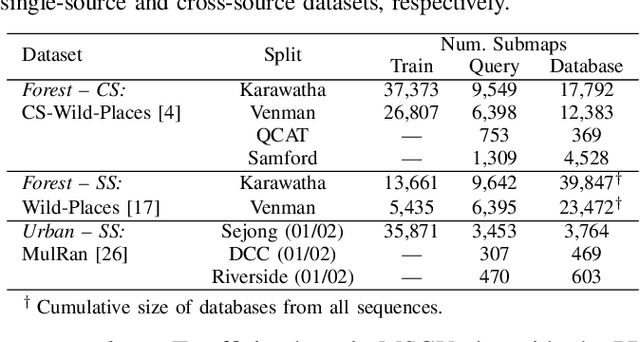

This article presents HOTFLoc++, an end-to-end framework for LiDAR place recognition, re-ranking, and 6-DoF metric localisation in forests. Leveraging an octree-based transformer, our approach extracts hierarchical local descriptors at multiple granularities to increase robustness to clutter, self-similarity, and viewpoint changes in challenging scenarios, including ground-to-ground and ground-to-aerial in forest and urban environments. We propose a learnable multi-scale geometric verification module to reduce re-ranking failures in the presence of degraded single-scale correspondences. Our coarse-to-fine registration approach achieves comparable or lower localisation errors to baselines, with runtime improvements of two orders of magnitude over RANSAC for dense point clouds. Experimental results on public datasets show the superiority of our approach compared to state-of-the-art methods, achieving an average Recall@1 of 90.7% on CS-Wild-Places: an improvement of 29.6 percentage points over baselines, while maintaining high performance on single-source benchmarks with an average Recall@1 of 91.7% and 96.0% on Wild-Places and MulRan, respectively. Our method achieves under 2 m and 5 degrees error for 97.2% of 6-DoF registration attempts, with our multi-scale re-ranking module reducing localisation errors by ~2$\times$ on average. The code will be available upon acceptance.
DeepForgeSeal: Latent Space-Driven Semi-Fragile Watermarking for Deepfake Detection Using Multi-Agent Adversarial Reinforcement Learning
Nov 07, 2025Rapid advances in generative AI have led to increasingly realistic deepfakes, posing growing challenges for law enforcement and public trust. Existing passive deepfake detectors struggle to keep pace, largely due to their dependence on specific forgery artifacts, which limits their ability to generalize to new deepfake types. Proactive deepfake detection using watermarks has emerged to address the challenge of identifying high-quality synthetic media. However, these methods often struggle to balance robustness against benign distortions with sensitivity to malicious tampering. This paper introduces a novel deep learning framework that harnesses high-dimensional latent space representations and the Multi-Agent Adversarial Reinforcement Learning (MAARL) paradigm to develop a robust and adaptive watermarking approach. Specifically, we develop a learnable watermark embedder that operates in the latent space, capturing high-level image semantics, while offering precise control over message encoding and extraction. The MAARL paradigm empowers the learnable watermarking agent to pursue an optimal balance between robustness and fragility by interacting with a dynamic curriculum of benign and malicious image manipulations simulated by an adversarial attacker agent. Comprehensive evaluations on the CelebA and CelebA-HQ benchmarks reveal that our method consistently outperforms state-of-the-art approaches, achieving improvements of over 4.5% on CelebA and more than 5.3% on CelebA-HQ under challenging manipulation scenarios.
Transforming volcanic monitoring: A dataset and benchmark for onboard volcano activity detection
Oct 27, 2025Natural disasters, such as volcanic eruptions, pose significant challenges to daily life and incur considerable global economic losses. The emergence of next-generation small-satellites, capable of constellation-based operations, offers unparalleled opportunities for near-real-time monitoring and onboard processing of such events. However, a major bottleneck remains the lack of extensive annotated datasets capturing volcanic activity, which hinders the development of robust detection systems. This paper introduces a novel dataset explicitly designed for volcanic activity and eruption detection, encompassing diverse volcanoes worldwide. The dataset provides binary annotations to identify volcanic anomalies or non-anomalies, covering phenomena such as temperature anomalies, eruptions, and volcanic ash emissions. These annotations offer a foundational resource for developing and evaluating detection models, addressing a critical gap in volcanic monitoring research. Additionally, we present comprehensive benchmarks using state-of-the-art models to establish baselines for future studies. Furthermore, we explore the potential for deploying these models onboard next-generation satellites. Using the Intel Movidius Myriad X VPU as a testbed, we demonstrate the feasibility of volcanic activity detection directly onboard. This capability significantly reduces latency and enhances response times, paving the way for advanced early warning systems. This paves the way for innovative solutions in volcanic disaster management, encouraging further exploration and refinement of onboard monitoring technologies.
Wound3DAssist: A Practical Framework for 3D Wound Assessment
Aug 25, 2025



Managing chronic wounds remains a major healthcare challenge, with clinical assessment often relying on subjective and time-consuming manual documentation methods. Although 2D digital videometry frameworks aided the measurement process, these approaches struggle with perspective distortion, a limited field of view, and an inability to capture wound depth, especially in anatomically complex or curved regions. To overcome these limitations, we present Wound3DAssist, a practical framework for 3D wound assessment using monocular consumer-grade videos. Our framework generates accurate 3D models from short handheld smartphone video recordings, enabling non-contact, automatic measurements that are view-independent and robust to camera motion. We integrate 3D reconstruction, wound segmentation, tissue classification, and periwound analysis into a modular workflow. We evaluate Wound3DAssist across digital models with known geometry, silicone phantoms, and real patients. Results show that the framework supports high-quality wound bed visualization, millimeter-level accuracy, and reliable tissue composition analysis. Full assessments are completed in under 20 minutes, demonstrating feasibility for real-world clinical use.
AG-VPReID.VIR: Bridging Aerial and Ground Platforms for Video-based Visible-Infrared Person Re-ID
Jul 24, 2025Person re-identification (Re-ID) across visible and infrared modalities is crucial for 24-hour surveillance systems, but existing datasets primarily focus on ground-level perspectives. While ground-based IR systems offer nighttime capabilities, they suffer from occlusions, limited coverage, and vulnerability to obstructions--problems that aerial perspectives uniquely solve. To address these limitations, we introduce AG-VPReID.VIR, the first aerial-ground cross-modality video-based person Re-ID dataset. This dataset captures 1,837 identities across 4,861 tracklets (124,855 frames) using both UAV-mounted and fixed CCTV cameras in RGB and infrared modalities. AG-VPReID.VIR presents unique challenges including cross-viewpoint variations, modality discrepancies, and temporal dynamics. Additionally, we propose TCC-VPReID, a novel three-stream architecture designed to address the joint challenges of cross-platform and cross-modality person Re-ID. Our approach bridges the domain gaps between aerial-ground perspectives and RGB-IR modalities, through style-robust feature learning, memory-based cross-view adaptation, and intermediary-guided temporal modeling. Experiments show that AG-VPReID.VIR presents distinctive challenges compared to existing datasets, with our TCC-VPReID framework achieving significant performance gains across multiple evaluation protocols. Dataset and code are available at https://github.com/agvpreid25/AG-VPReID.VIR.
Cross-Branch Orthogonality for Improved Generalization in Face Deepfake Detection
May 08, 2025Remarkable advancements in generative AI technology have given rise to a spectrum of novel deepfake categories with unprecedented leaps in their realism, and deepfakes are increasingly becoming a nuisance to law enforcement authorities and the general public. In particular, we observe alarming levels of confusion, deception, and loss of faith regarding multimedia content within society caused by face deepfakes, and existing deepfake detectors are struggling to keep up with the pace of improvements in deepfake generation. This is primarily due to their reliance on specific forgery artifacts, which limits their ability to generalise and detect novel deepfake types. To combat the spread of malicious face deepfakes, this paper proposes a new strategy that leverages coarse-to-fine spatial information, semantic information, and their interactions while ensuring feature distinctiveness and reducing the redundancy of the modelled features. A novel feature orthogonality-based disentanglement strategy is introduced to ensure branch-level and cross-branch feature disentanglement, which allows us to integrate multiple feature vectors without adding complexity to the feature space or compromising generalisation. Comprehensive experiments on three public benchmarks: FaceForensics++, Celeb-DF, and the Deepfake Detection Challenge (DFDC) show that these design choices enable the proposed approach to outperform current state-of-the-art methods by 5% on the Celeb-DF dataset and 7% on the DFDC dataset in a cross-dataset evaluation setting.