 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Self-Predictive Learning for Reinforcement Learning
Dec 06, 2022



We study the learning dynamics of self-predictive learning for reinforcement learning, a family of algorithms that learn representations by minimizing the prediction error of their own future latent representations. Despite its recent empirical success, such algorithms have an apparent defect: trivial representations (such as constants) minimize the prediction error, yet it is obviously undesirable to converge to such solutions. Our central insight is that careful designs of the optimization dynamics are critical to learning meaningful representations. We identify that a faster paced optimization of the predictor and semi-gradient updates on the representation, are crucial to preventing the representation collapse. Then in an idealized setup, we show self-predictive learning dynamics carries out spectral decomposition on the state transition matrix, effectively capturing information of the transition dynamics. Building on the theoretical insights, we propose bidirectional self-predictive learning, a novel self-predictive algorithm that learns two representations simultaneously. We examine the robustness of our theoretical insights with a number of small-scale experiments and showcase the promise of the novel representation learning algorithm with large-scale experiments.
Learning Dynamics and Generalization in Reinforcement Learning
Jun 05, 2022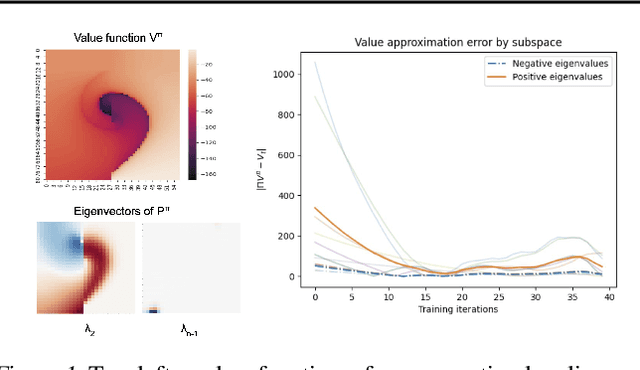
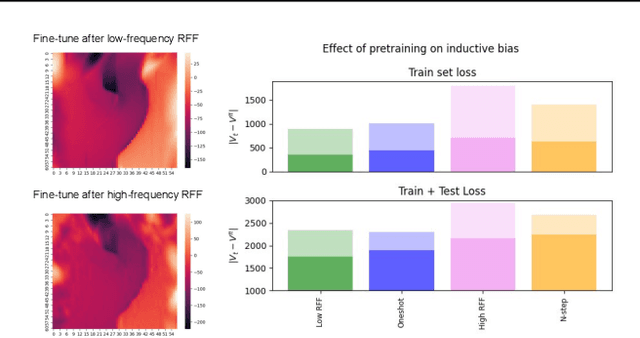
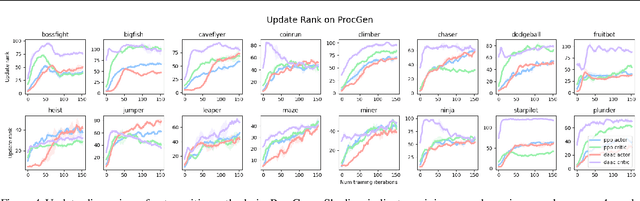
Solving a reinforcement learning (RL) problem poses two competing challenges: fitting a potentially discontinuous value function, and generalizing well to new observations. In this paper, we analyze the learning dynamics of temporal difference algorithms to gain novel insight into the tension between these two objectives. We show theoretically that temporal difference learning encourages agents to fit non-smooth components of the value function early in training, and at the same time induces the second-order effect of discouraging generalization. We corroborate these findings in deep RL agents trained on a range of environments, finding that neural networks trained using temporal difference algorithms on dense reward tasks exhibit weaker generalization between states than randomly initialized networks and networks trained with policy gradient methods. Finally, we investigate how post-training policy distillation may avoid this pitfall, and show that this approach improves generalization to novel environments in the ProcGen suite and improves robustness to input perturbations.
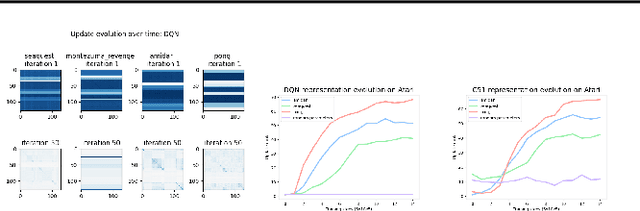
Understanding and Preventing Capacity Loss in Reinforcement Learning
Apr 20, 2022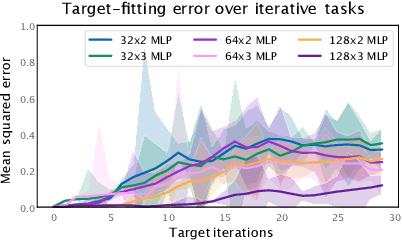
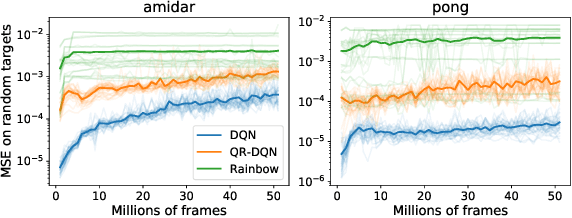

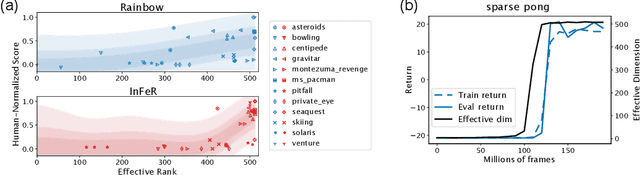
The reinforcement learning (RL) problem is rife with sources of non-stationarity, making it a notoriously difficult problem domain for the application of neural networks. We identify a mechanism by which non-stationary prediction targets can prevent learning progress in deep RL agents: \textit{capacity loss}, whereby networks trained on a sequence of target values lose their ability to quickly update their predictions over time. We demonstrate that capacity loss occurs in a range of RL agents and environments, and is particularly damaging to performance in sparse-reward tasks. We then present a simple regularizer, Initial Feature Regularization (InFeR), that mitigates this phenomenon by regressing a subspace of features towards its value at initialization, leading to significant performance improvements in sparse-reward environments such as Montezuma's Revenge. We conclude that preventing capacity loss is crucial to enable agents to maximally benefit from the learning signals they obtain throughout the entire training trajectory.
DARTS without a Validation Set: Optimizing the Marginal Likelihood
Dec 24, 2021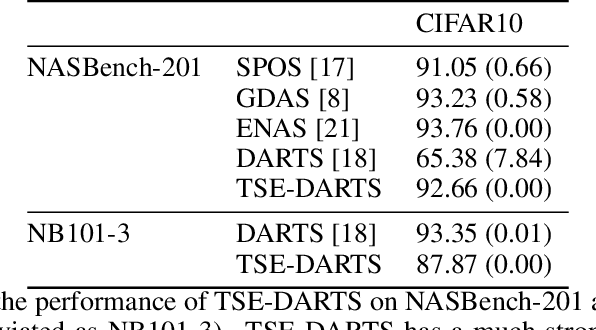
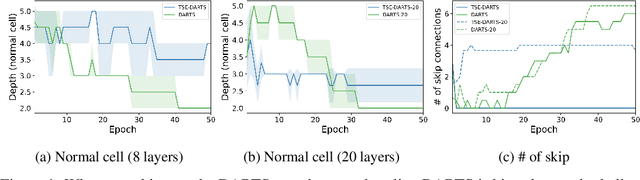
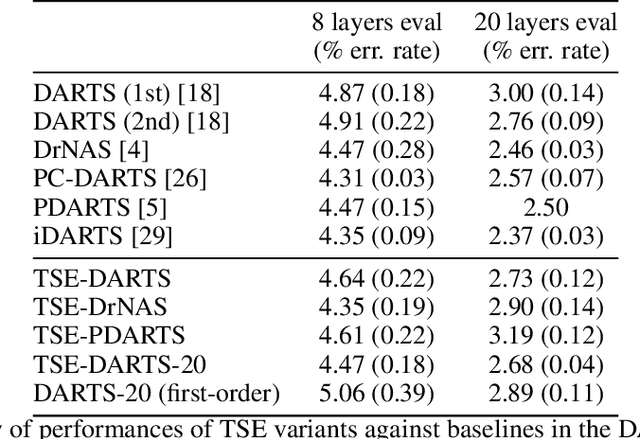
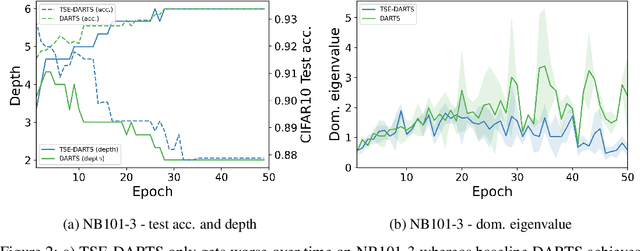
The success of neural architecture search (NAS) has historically been limited by excessive compute requirements. While modern weight-sharing NAS methods such as DARTS are able to finish the search in single-digit GPU days, extracting the final best architecture from the shared weights is notoriously unreliable. Training-Speed-Estimate (TSE), a recently developed generalization estimator with a Bayesian marginal likelihood interpretation, has previously been used in place of the validation loss for gradient-based optimization in DARTS. This prevents the DARTS skip connection collapse, which significantly improves performance on NASBench-201 and the original DARTS search space. We extend those results by applying various DARTS diagnostics and show several unusual behaviors arising from not using a validation set. Furthermore, our experiments yield concrete examples of the depth gap and topology selection in DARTS having a strongly negative impact on the search performance despite generally receiving limited attention in the literature compared to the operations selection.
Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning
Jun 04, 2021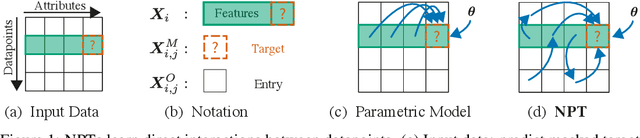
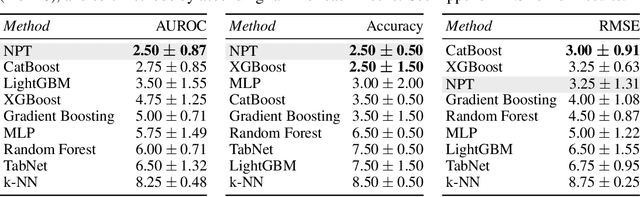
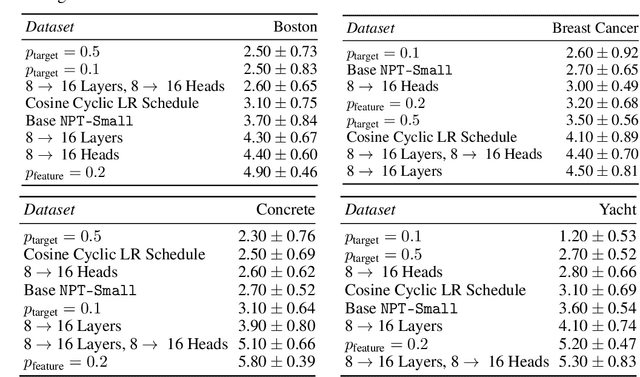
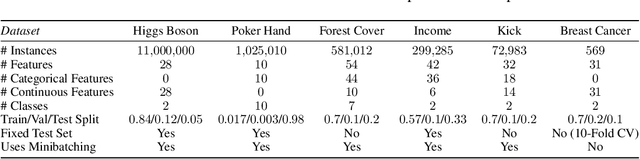
We challenge a common assumption underlying most supervised deep learning: that a model makes a prediction depending only on its parameters and the features of a single input. To this end, we introduce a general-purpose deep learning architecture that takes as input the entire dataset instead of processing one datapoint at a time. Our approach uses self-attention to reason about relationships between datapoints explicitly, which can be seen as realizing non-parametric models using parametric attention mechanisms. However, unlike conventional non-parametric models, we let the model learn end-to-end from the data how to make use of other datapoints for prediction. Empirically, our models solve cross-datapoint lookup and complex reasoning tasks unsolvable by traditional deep learning models. We show highly competitive results on tabular data, early results on CIFAR-10, and give insight into how the model makes use of the interactions between points.
Provable Guarantees on the Robustness of Decision Rules to Causal Interventions
May 19, 2021
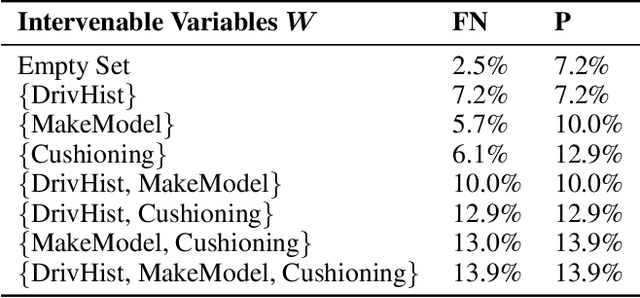
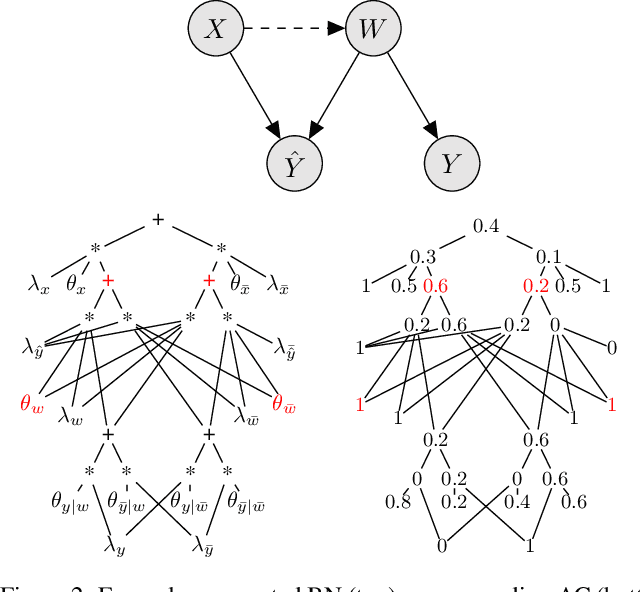
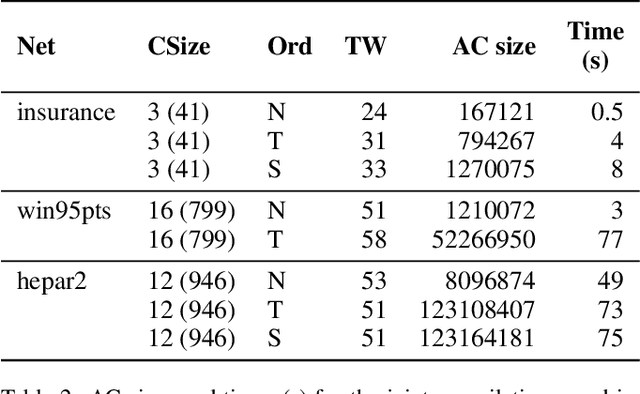
Robustness of decision rules to shifts in the data-generating process is crucial to the successful deployment of decision-making systems. Such shifts can be viewed as interventions on a causal graph, which capture (possibly hypothetical) changes in the data-generating process, whether due to natural reasons or by the action of an adversary. We consider causal Bayesian networks and formally define the interventional robustness problem, a novel model-based notion of robustness for decision functions that measures worst-case performance with respect to a set of interventions that denote changes to parameters and/or causal influences. By relying on a tractable representation of Bayesian networks as arithmetic circuits, we provide efficient algorithms for computing guaranteed upper and lower bounds on the interventional robustness probabilities. Experimental results demonstrate that the methods yield useful and interpretable bounds for a range of practical networks, paving the way towards provably causally robust decision-making systems.
Robustness to Pruning Predicts Generalization in Deep Neural Networks
Mar 10, 2021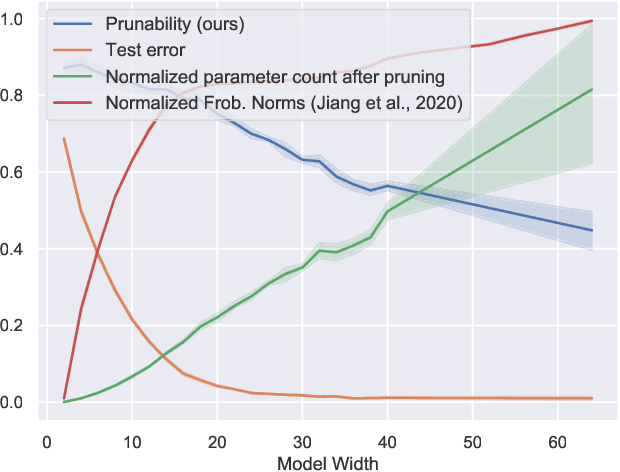
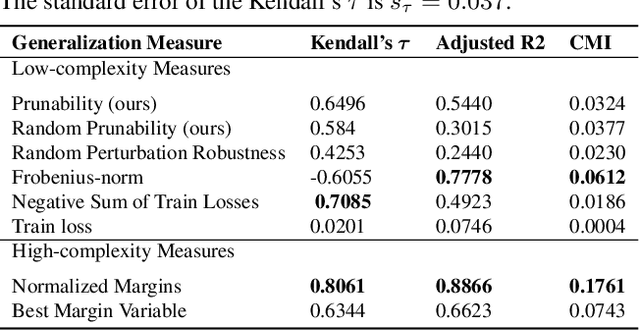
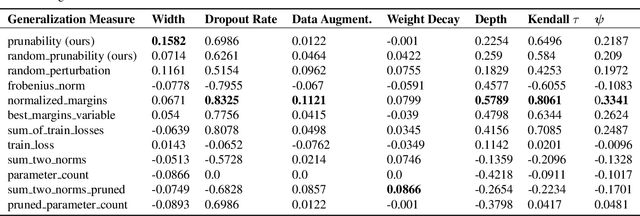
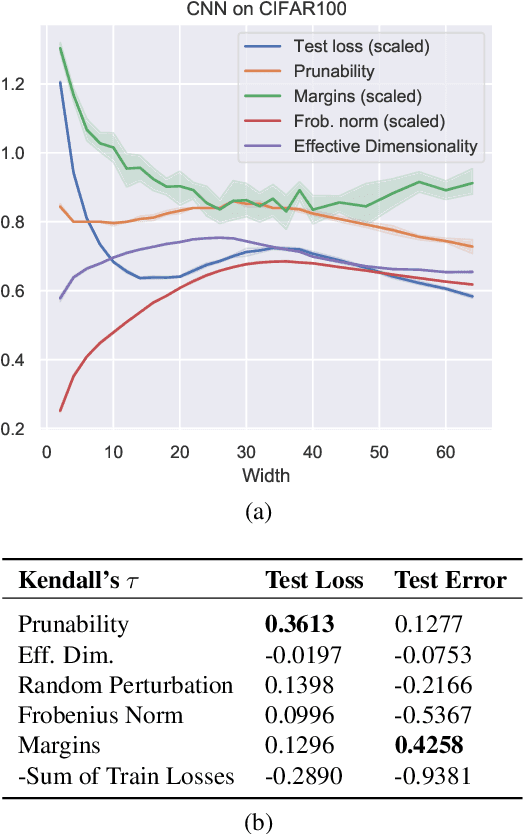
Existing generalization measures that aim to capture a model's simplicity based on parameter counts or norms fail to explain generalization in overparameterized deep neural networks. In this paper, we introduce a new, theoretically motivated measure of a network's simplicity which we call prunability: the smallest \emph{fraction} of the network's parameters that can be kept while pruning without adversely affecting its training loss. We show that this measure is highly predictive of a model's generalization performance across a large set of convolutional networks trained on CIFAR-10, does not grow with network size unlike existing pruning-based measures, and exhibits high correlation with test set loss even in a particularly challenging double descent setting. Lastly, we show that the success of prunability cannot be explained by its relation to known complexity measures based on models' margin, flatness of minima and optimization speed, finding that our new measure is similar to -- but more predictive than -- existing flatness-based measures, and that its predictions exhibit low mutual information with those of other baselines.
On The Effect of Auxiliary Tasks on Representation Dynamics
Feb 25, 2021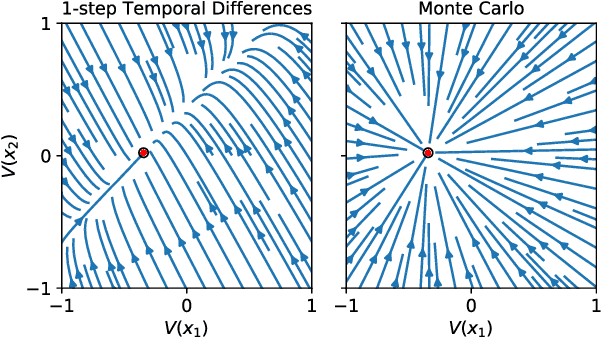

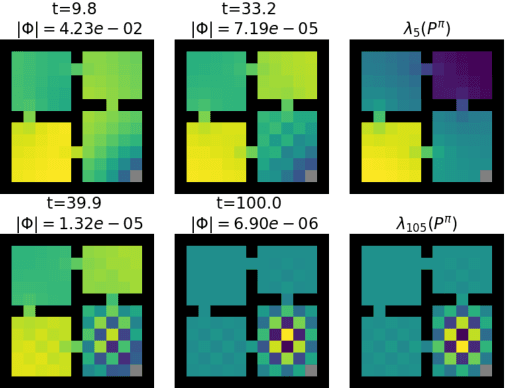

While auxiliary tasks play a key role in shaping the representations learnt by reinforcement learning agents, much is still unknown about the mechanisms through which this is achieved. This work develops our understanding of the relationship between auxiliary tasks, environment structure, and representations by analysing the dynamics of temporal difference algorithms. Through this approach, we establish a connection between the spectral decomposition of the transition operator and the representations induced by a variety of auxiliary tasks. We then leverage insights from these theoretical results to inform the selection of auxiliary tasks for deep reinforcement learning agents in sparse-reward environments.
PsiPhi-Learning: Reinforcement Learning with Demonstrations using Successor Features and Inverse Temporal Difference Learning
Feb 24, 2021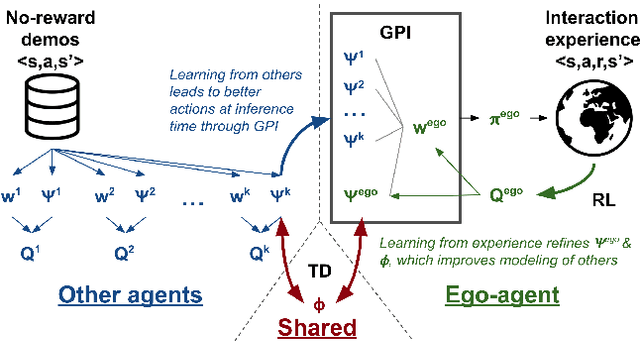
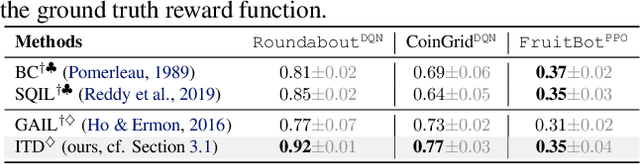

We study reinforcement learning (RL) with no-reward demonstrations, a setting in which an RL agent has access to additional data from the interaction of other agents with the same environment. However, it has no access to the rewards or goals of these agents, and their objectives and levels of expertise may vary widely. These assumptions are common in multi-agent settings, such as autonomous driving. To effectively use this data, we turn to the framework of successor features. This allows us to disentangle shared features and dynamics of the environment from agent-specific rewards and policies. We propose a multi-task inverse reinforcement learning (IRL) algorithm, called \emph{inverse temporal difference learning} (ITD), that learns shared state features, alongside per-agent successor features and preference vectors, purely from demonstrations without reward labels. We further show how to seamlessly integrate ITD with learning from online environment interactions, arriving at a novel algorithm for reinforcement learning with demonstrations, called $\Psi \Phi$-learning (pronounced `Sci-Fi'). We provide empirical evidence for the effectiveness of $\Psi \Phi$-learning as a method for improving RL, IRL, imitation, and few-shot transfer, and derive worst-case bounds for its performance in zero-shot transfer to new tasks.
A Bayesian Perspective on Training Speed and Model Selection
Oct 27, 2020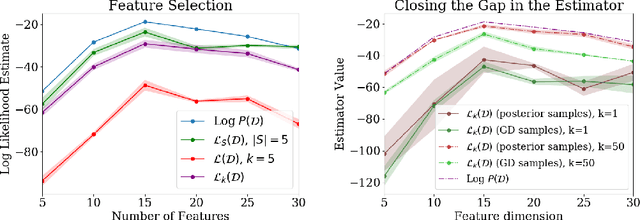
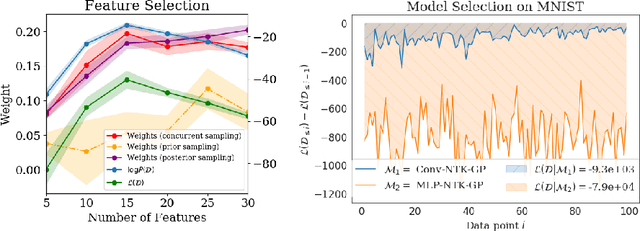
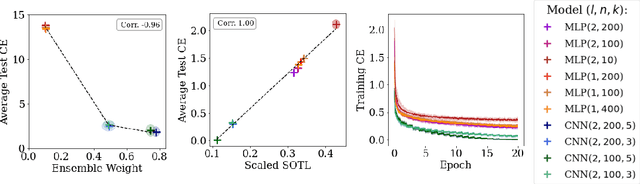
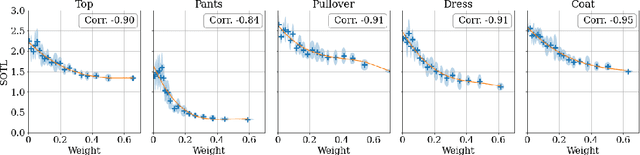
We take a Bayesian perspective to illustrate a connection between training speed and the marginal likelihood in linear models. This provides two major insights: first, that a measure of a model's training speed can be used to estimate its marginal likelihood. Second, that this measure, under certain conditions, predicts the relative weighting of models in linear model combinations trained to minimize a regression loss. We verify our results in model selection tasks for linear models and for the infinite-width limit of deep neural networks. We further provide encouraging empirical evidence that the intuition developed in these settings also holds for deep neural networks trained with stochastic gradient descent. Our results suggest a promising new direction towards explaining why neural networks trained with stochastic gradient descent are biased towards functions that generalize well.