 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUserBERT: Contrastive User Model Pre-training
Sep 03, 2021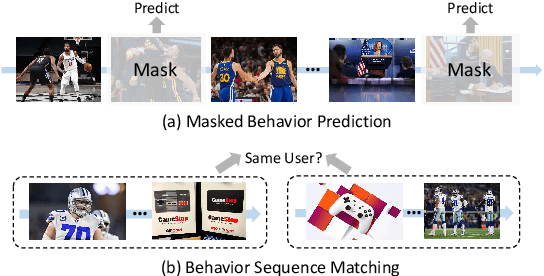
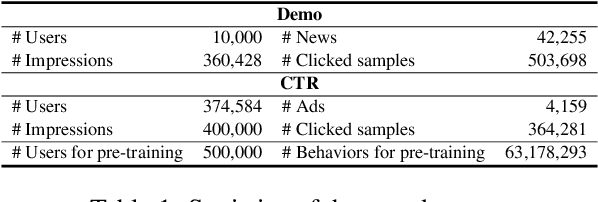
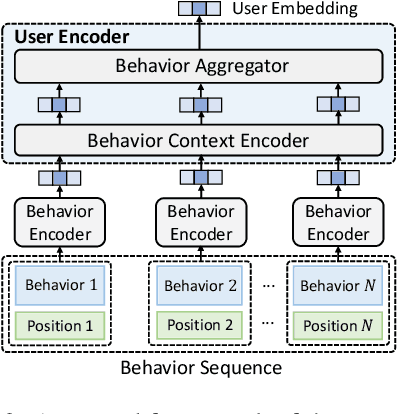
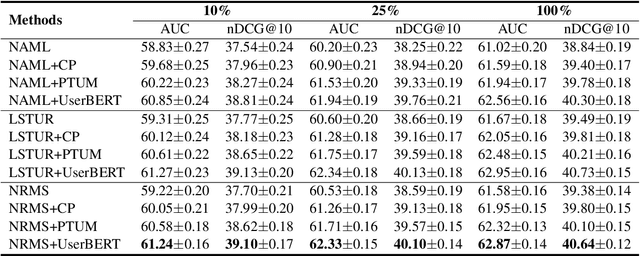
User modeling is critical for personalized web applications. Existing user modeling methods usually train user models from user behaviors with task-specific labeled data. However, labeled data in a target task may be insufficient for training accurate user models. Fortunately, there are usually rich unlabeled user behavior data which encode rich information of user characteristics and interests. Thus, pre-training user models on unlabeled user behavior data has the potential to improve user modeling for many downstream tasks. In this paper, we propose a contrastive user model pre-training method named UserBERT. Two self-supervision tasks are incorporated in UserBERT for user model pre-training on unlabeled user behavior data to empower user modeling. The first one is masked behavior prediction, which aims to model the relatedness between user behaviors. The second one is behavior sequence matching, which aims to capture the inherent user interests that are consistent in different periods. In addition, we propose a medium-hard negative sampling framework to select informative negative samples for better contrastive pre-training. We maintain a synchronously updated candidate behavior pool and an asynchronously updated candidate behavior sequence pool to select the locally hardest negative behaviors and behavior sequences in an efficient way. Extensive experiments on two real-world datasets in different tasks show that UserBERT can effectively improve various user models.
Smart Bird: Learnable Sparse Attention for Efficient and Effective Transformer
Sep 02, 2021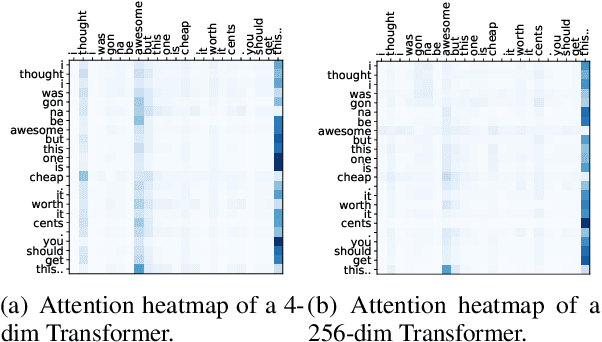
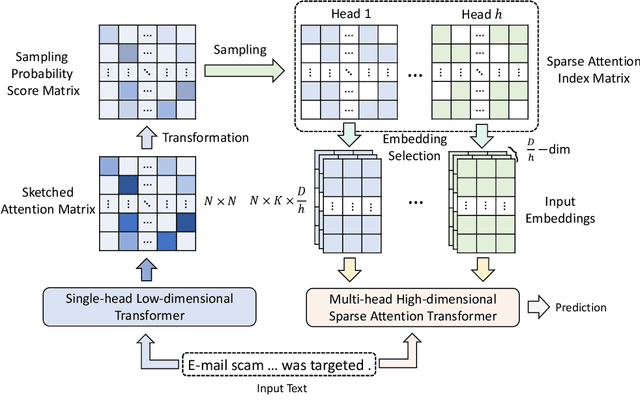

Transformer has achieved great success in NLP. However, the quadratic complexity of the self-attention mechanism in Transformer makes it inefficient in handling long sequences. Many existing works explore to accelerate Transformers by computing sparse self-attention instead of a dense one, which usually attends to tokens at certain positions or randomly selected tokens. However, manually selected or random tokens may be uninformative for context modeling. In this paper, we propose Smart Bird, which is an efficient and effective Transformer with learnable sparse attention. In Smart Bird, we first compute a sketched attention matrix with a single-head low-dimensional Transformer, which aims to find potential important interactions between tokens. We then sample token pairs based on their probability scores derived from the sketched attention matrix to generate different sparse attention index matrices for different attention heads. Finally, we select token embeddings according to the index matrices to form the input of sparse attention networks. Extensive experiments on six benchmark datasets for different tasks validate the efficiency and effectiveness of Smart Bird in text modeling.
FedKD: Communication Efficient Federated Learning via Knowledge Distillation
Aug 30, 2021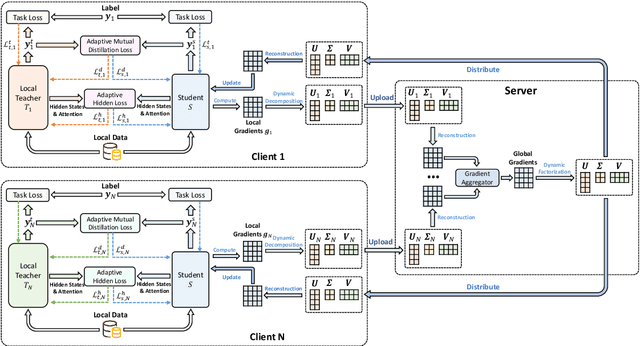
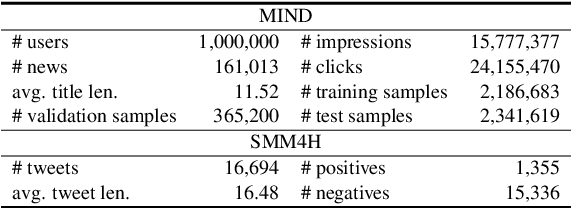
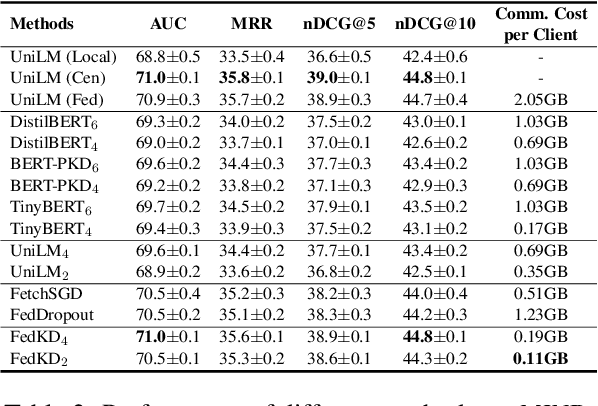
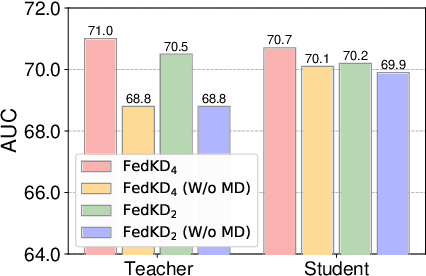
Federated learning is widely used to learn intelligent models from decentralized data. In federated learning, clients need to communicate their local model updates in each iteration of model learning. However, model updates are large in size if the model contains numerous parameters, and there usually needs many rounds of communication until model converges. Thus, the communication cost in federated learning can be quite heavy. In this paper, we propose a communication efficient federated learning method based on knowledge distillation. Instead of directly communicating the large models between clients and server, we propose an adaptive mutual distillation framework to reciprocally learn a student and a teacher model on each client, where only the student model is shared by different clients and updated collaboratively to reduce the communication cost. Both the teacher and student on each client are learned on its local data and the knowledge distilled from each other, where their distillation intensities are controlled by their prediction quality. To further reduce the communication cost, we propose a dynamic gradient approximation method based on singular value decomposition to approximate the exchanged gradients with dynamic precision. Extensive experiments on benchmark datasets in different tasks show that our approach can effectively reduce the communication cost and achieve competitive results.
Is News Recommendation a Sequential Recommendation Task?
Aug 26, 2021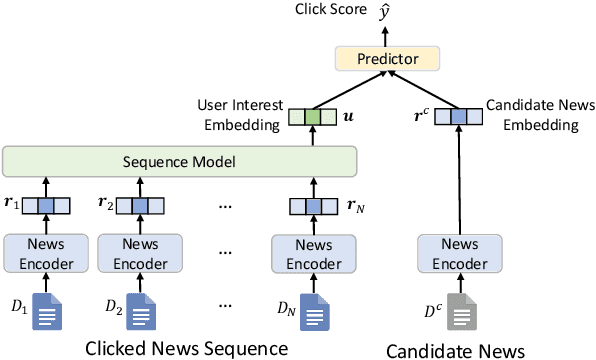
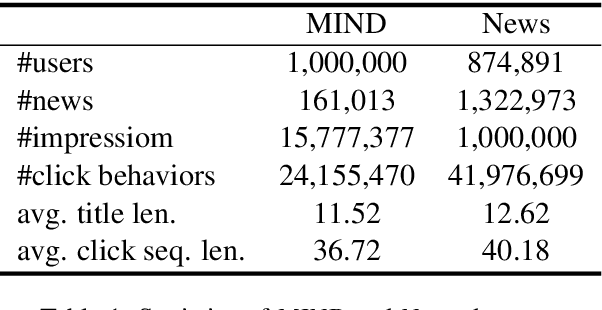
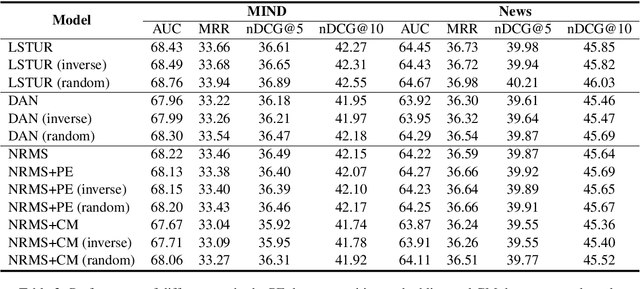
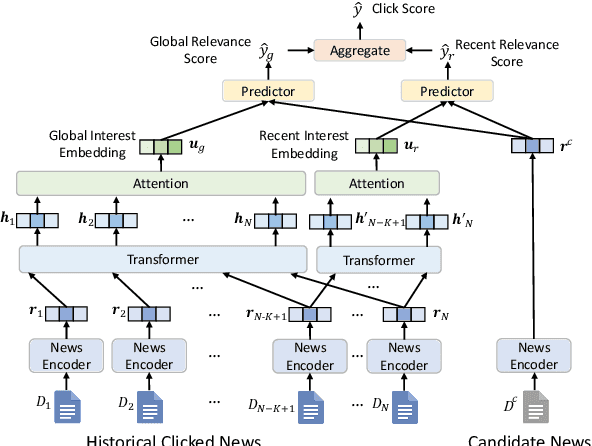
News recommendation is often modeled as a sequential recommendation task, which assumes that there are rich short-term dependencies over historical clicked news. However, in news recommendation scenarios users usually have strong preferences on the temporal diversity of news information and may not tend to click similar news successively, which is very different from many sequential recommendation scenarios such as e-commerce recommendation. In this paper, we study whether news recommendation can be regarded as a standard sequential recommendation problem. Through extensive experiments on two real-world datasets, we find that modeling news recommendation as a sequential recommendation problem is suboptimal. To handle this challenge, we further propose a temporal diversity-aware news recommendation method that can promote candidate news that are diverse from recently clicked news, which can help predict future clicks more accurately. Experiments show that our approach can consistently improve various news recommendation methods.
Personalized News Recommendation: A Survey
Jul 08, 2021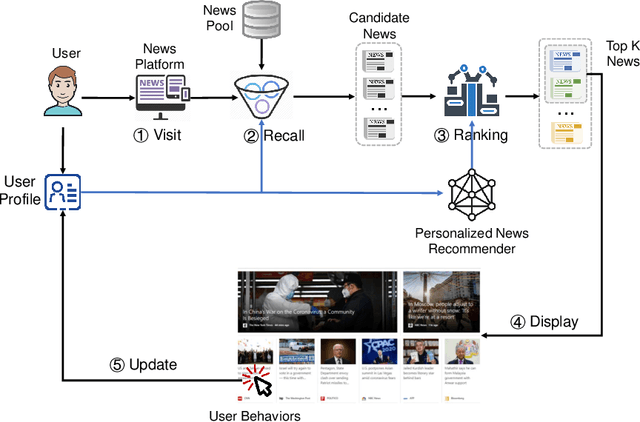

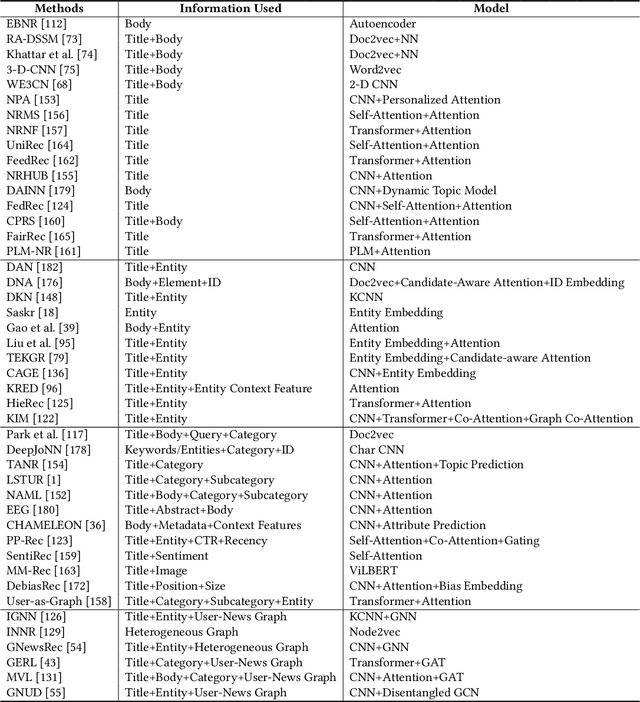
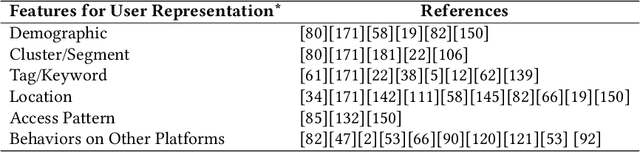
Personalized news recommendation is an important technique to help users find their interested news information and alleviate their information overload. It has been extensively studied over decades and has achieved notable success in improving users' news reading experience. However, there are still many unsolved problems and challenges that need to be further studied. To help researchers master the advances in personalized news recommendation over the past years, in this paper we present a comprehensive overview of personalized news recommendation. Instead of following the conventional taxonomy of news recommendation methods, in this paper we propose a novel perspective to understand personalized news recommendation based on its core problems and the associated techniques and challenges. We first review the techniques for tackling each core problem in a personalized news recommender system and the challenges they face. Next, we introduce the public datasets and evaluation methods for personalized news recommendation. We then discuss the key points on improving the responsibility of personalized news recommender systems. Finally, we raise several research directions that are worth investigating in the future. This paper can provide up-to-date and comprehensive views to help readers understand the personalized news recommendation field. We hope this paper can facilitate research on personalized news recommendation and as well as related fields in natural language processing and data mining.
DebiasGAN: Eliminating Position Bias in News Recommendation with Adversarial Learning
Jun 11, 2021

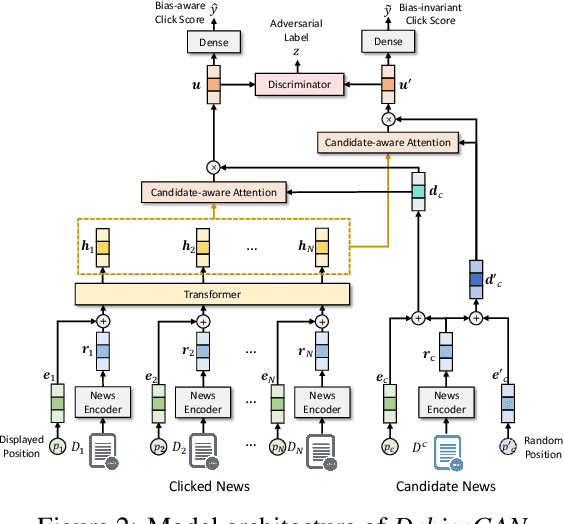
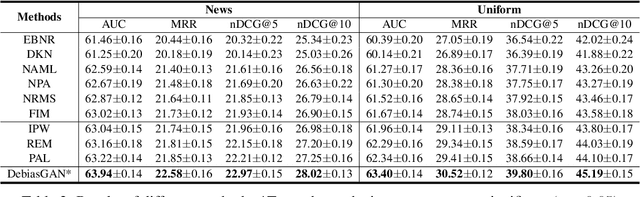
News recommendation is important for improving news reading experience of users. Users' news click behaviors are widely used for inferring user interests and predicting future clicks. However, click behaviors are heavily affected by the biases brought by the positions of news displayed on the webpage. It is important to eliminate the effect of position biases on the recommendation model to accurately target user interests. In this paper, we propose a news recommendation method named DebiasGAN that can effectively eliminate the effect of position biases via adversarial learning. We use a bias-aware click model to capture the influence of position bias on click behaviors, and we use a bias-invariant click model with random candidate news positions to estimate the ideally unbiased click scores. We apply adversarial learning techniques to the hidden representations learned by the two models to help the bias-invariant click model capture the bias-independent interest of users on news. Experimental results on two real-world datasets show that DebiasGAN can effectively improve the accuracy of news recommendation by eliminating position biases.
PP-Rec: News Recommendation with Personalized User Interest and Time-aware News Popularity
Jun 10, 2021
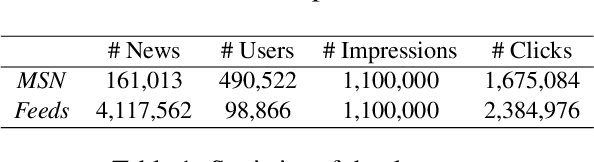
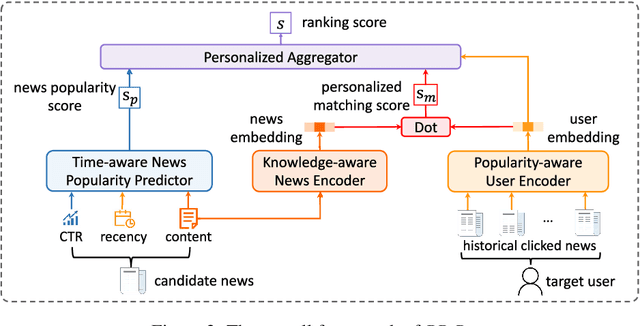
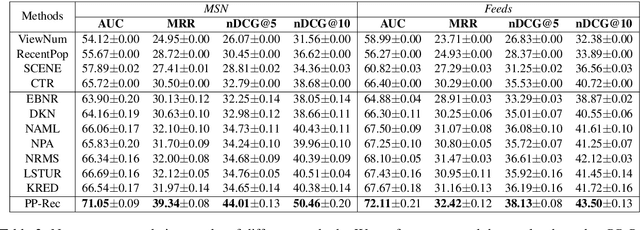
Personalized news recommendation methods are widely used in online news services. These methods usually recommend news based on the matching between news content and user interest inferred from historical behaviors. However, these methods usually have difficulties in making accurate recommendations to cold-start users, and tend to recommend similar news with those users have read. In general, popular news usually contain important information and can attract users with different interests. Besides, they are usually diverse in content and topic. Thus, in this paper we propose to incorporate news popularity information to alleviate the cold-start and diversity problems for personalized news recommendation. In our method, the ranking score for recommending a candidate news to a target user is the combination of a personalized matching score and a news popularity score. The former is used to capture the personalized user interest in news. The latter is used to measure time-aware popularity of candidate news, which is predicted based on news content, recency, and real-time CTR using a unified framework. Besides, we propose a popularity-aware user encoder to eliminate the popularity bias in user behaviors for accurate interest modeling. Experiments on two real-world datasets show our method can effectively improve the accuracy and diversity for news recommendation.
HieRec: Hierarchical User Interest Modeling for Personalized News Recommendation
Jun 08, 2021

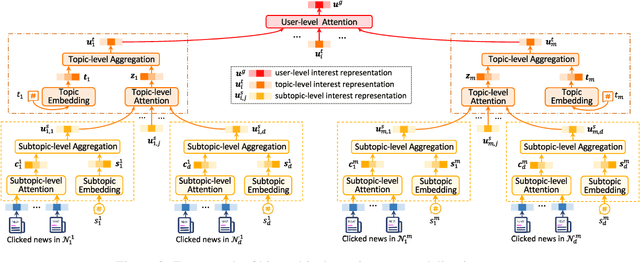
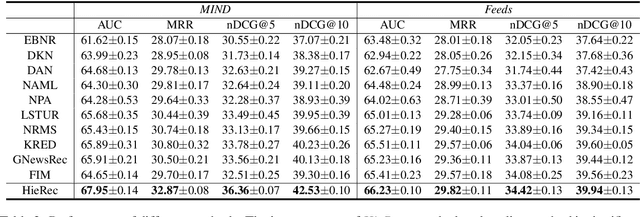
User interest modeling is critical for personalized news recommendation. Existing news recommendation methods usually learn a single user embedding for each user from their previous behaviors to represent their overall interest. However, user interest is usually diverse and multi-grained, which is difficult to be accurately modeled by a single user embedding. In this paper, we propose a news recommendation method with hierarchical user interest modeling, named HieRec. Instead of a single user embedding, in our method each user is represented in a hierarchical interest tree to better capture their diverse and multi-grained interest in news. We use a three-level hierarchy to represent 1) overall user interest; 2) user interest in coarse-grained topics like sports; and 3) user interest in fine-grained topics like football. Moreover, we propose a hierarchical user interest matching framework to match candidate news with different levels of user interest for more accurate user interest targeting. Extensive experiments on two real-world datasets validate our method can effectively improve the performance of user modeling for personalized news recommendation.
Hi-Transformer: Hierarchical Interactive Transformer for Efficient and Effective Long Document Modeling
Jun 02, 2021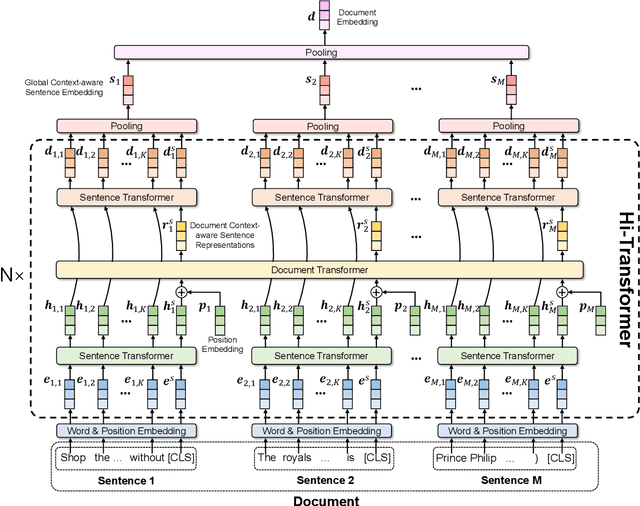

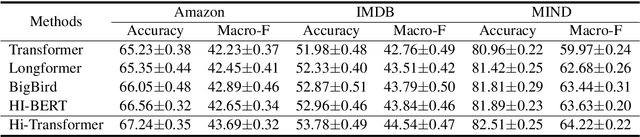
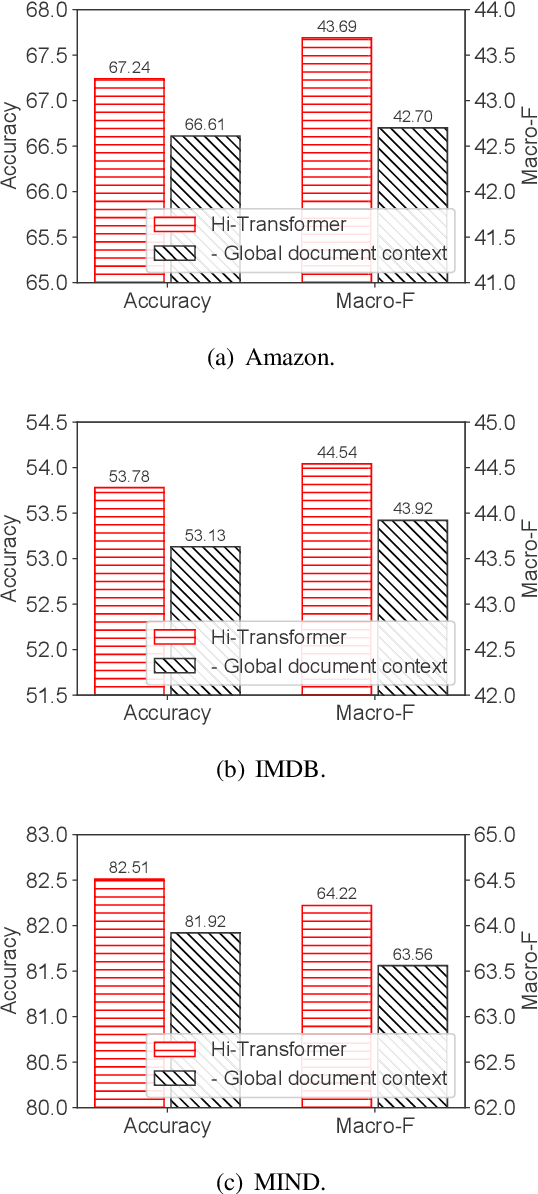
Transformer is important for text modeling. However, it has difficulty in handling long documents due to the quadratic complexity with input text length. In order to handle this problem, we propose a hierarchical interactive Transformer (Hi-Transformer) for efficient and effective long document modeling. Hi-Transformer models documents in a hierarchical way, i.e., first learns sentence representations and then learns document representations. It can effectively reduce the complexity and meanwhile capture global document context in the modeling of each sentence. More specifically, we first use a sentence Transformer to learn the representations of each sentence. Then we use a document Transformer to model the global document context from these sentence representations. Next, we use another sentence Transformer to enhance sentence modeling using the global document context. Finally, we use hierarchical pooling method to obtain document embedding. Extensive experiments on three benchmark datasets validate the efficiency and effectiveness of Hi-Transformer in long document modeling.
One Teacher is Enough? Pre-trained Language Model Distillation from Multiple Teachers
Jun 02, 2021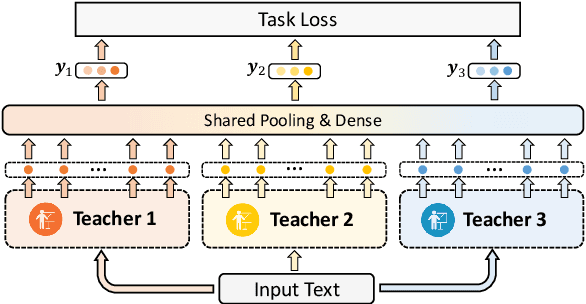
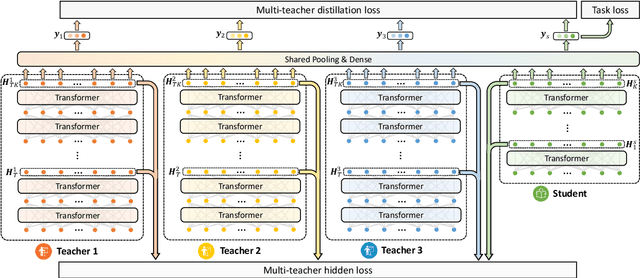
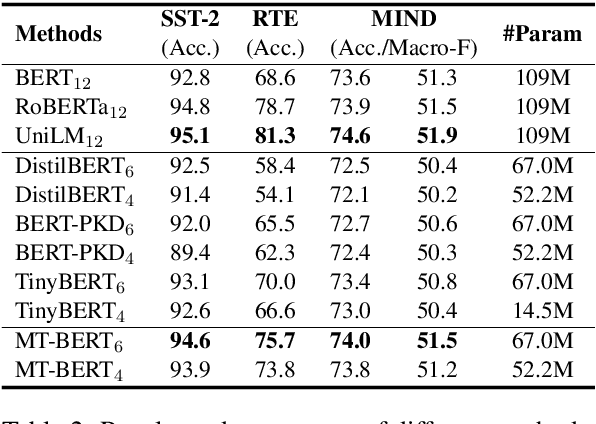
Pre-trained language models (PLMs) achieve great success in NLP. However, their huge model sizes hinder their applications in many practical systems. Knowledge distillation is a popular technique to compress PLMs, which learns a small student model from a large teacher PLM. However, the knowledge learned from a single teacher may be limited and even biased, resulting in low-quality student model. In this paper, we propose a multi-teacher knowledge distillation framework named MT-BERT for pre-trained language model compression, which can train high-quality student model from multiple teacher PLMs. In MT-BERT we design a multi-teacher co-finetuning method to jointly finetune multiple teacher PLMs in downstream tasks with shared pooling and prediction layers to align their output space for better collaborative teaching. In addition, we propose a multi-teacher hidden loss and a multi-teacher distillation loss to transfer the useful knowledge in both hidden states and soft labels from multiple teacher PLMs to the student model. Experiments on three benchmark datasets validate the effectiveness of MT-BERT in compressing PLMs.