 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNASTAR: Noise Adaptive Speech Enhancement with Target-Conditional Resampling
Jun 18, 2022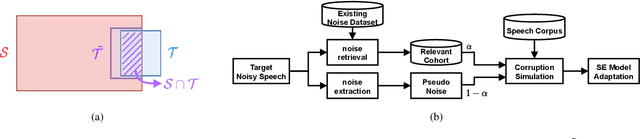
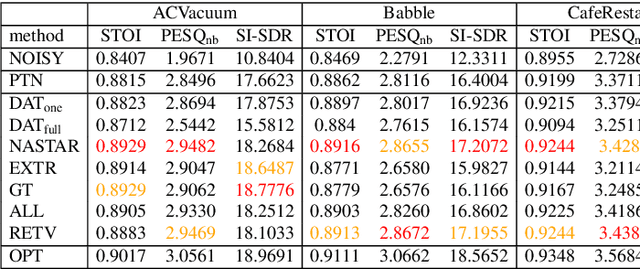
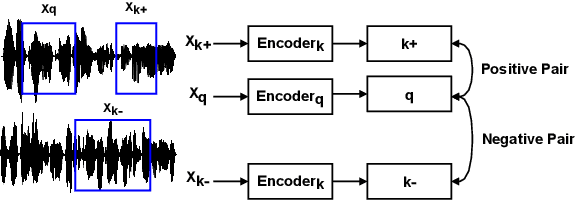
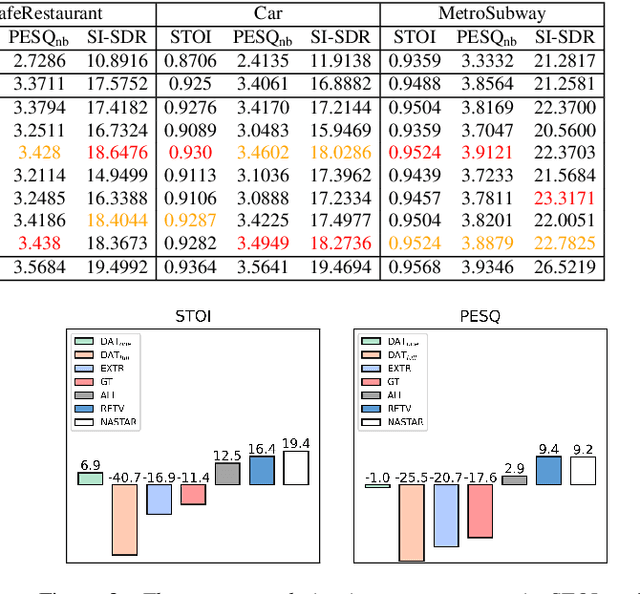
For deep learning-based speech enhancement (SE) systems, the training-test acoustic mismatch can cause notable performance degradation. To address the mismatch issue, numerous noise adaptation strategies have been derived. In this paper, we propose a novel method, called noise adaptive speech enhancement with target-conditional resampling (NASTAR), which reduces mismatches with only one sample (one-shot) of noisy speech in the target environment. NASTAR uses a feedback mechanism to simulate adaptive training data via a noise extractor and a retrieval model. The noise extractor estimates the target noise from the noisy speech, called pseudo-noise. The noise retrieval model retrieves relevant noise samples from a pool of noise signals according to the noisy speech, called relevant-cohort. The pseudo-noise and the relevant-cohort set are jointly sampled and mixed with the source speech corpus to prepare simulated training data for noise adaptation. Experimental results show that NASTAR can effectively use one noisy speech sample to adapt an SE model to a target condition. Moreover, both the noise extractor and the noise retrieval model contribute to model adaptation. To our best knowledge, NASTAR is the first work to perform one-shot noise adaptation through noise extraction and retrieval.
Continual Learning for Visual Search with Backward Consistent Feature Embedding
May 26, 2022
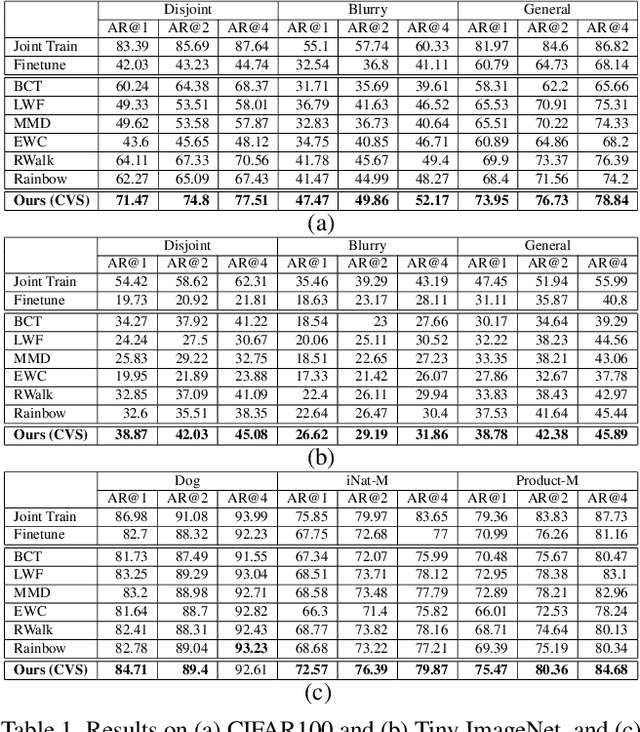
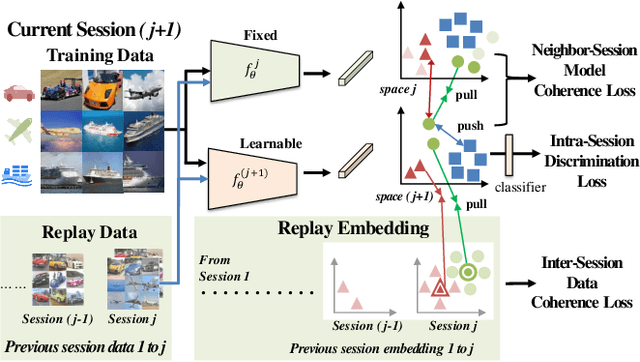
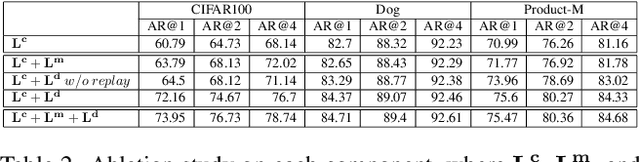
In visual search, the gallery set could be incrementally growing and added to the database in practice. However, existing methods rely on the model trained on the entire dataset, ignoring the continual updating of the model. Besides, as the model updates, the new model must re-extract features for the entire gallery set to maintain compatible feature space, imposing a high computational cost for a large gallery set. To address the issues of long-term visual search, we introduce a continual learning (CL) approach that can handle the incrementally growing gallery set with backward embedding consistency. We enforce the losses of inter-session data coherence, neighbor-session model coherence, and intra-session discrimination to conduct a continual learner. In addition to the disjoint setup, our CL solution also tackles the situation of increasingly adding new classes for the blurry boundary without assuming all categories known in the beginning and during model update. To our knowledge, this is the first CL method both tackling the issue of backward-consistent feature embedding and allowing novel classes to occur in the new sessions. Extensive experiments on various benchmarks show the efficacy of our approach under a wide range of setups.
STR-GQN: Scene Representation and Rendering for Unknown Cameras Based on Spatial Transformation Routing
Aug 06, 2021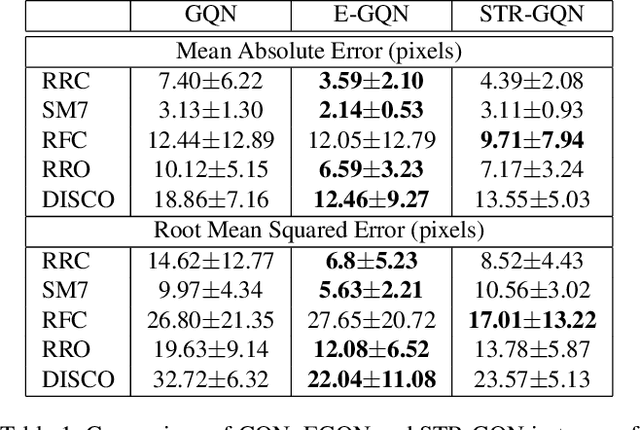
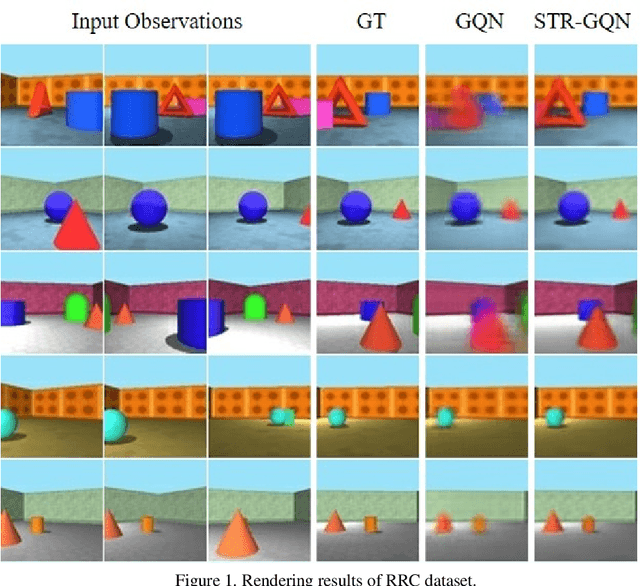
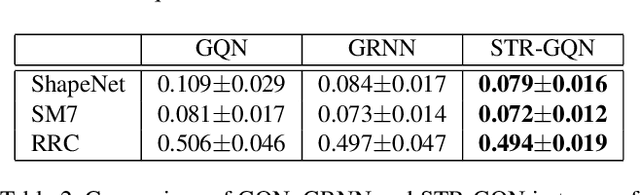

Geometry-aware modules are widely applied in recent deep learning architectures for scene representation and rendering. However, these modules require intrinsic camera information that might not be obtained accurately. In this paper, we propose a Spatial Transformation Routing (STR) mechanism to model the spatial properties without applying any geometric prior. The STR mechanism treats the spatial transformation as the message passing process, and the relation between the view poses and the routing weights is modeled by an end-to-end trainable neural network. Besides, an Occupancy Concept Mapping (OCM) framework is proposed to provide explainable rationals for scene-fusion processes. We conducted experiments on several datasets and show that the proposed STR mechanism improves the performance of the Generative Query Network (GQN). The visualization results reveal that the routing process can pass the observed information from one location of some view to the associated location in the other view, which demonstrates the advantage of the proposed model in terms of spatial cognition.
Part-Aware Measurement for Robust Multi-View Multi-Human 3D Pose Estimation and Tracking
Jun 22, 2021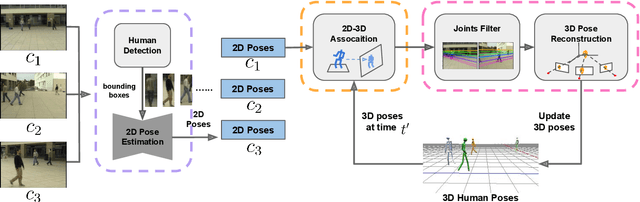
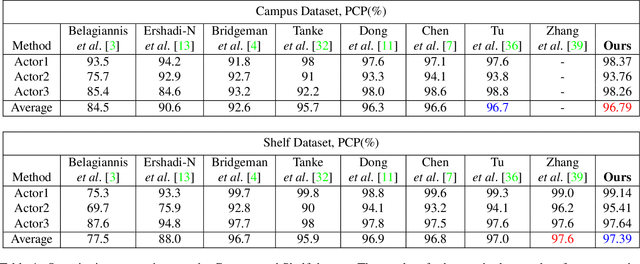
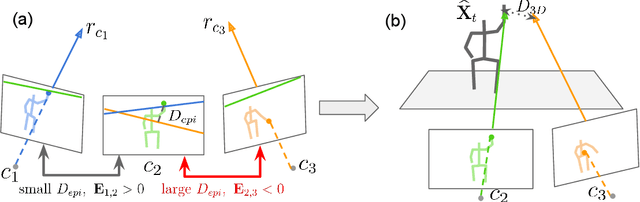
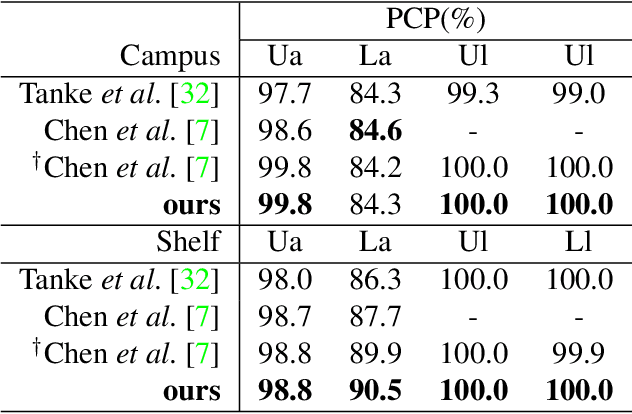
This paper introduces an approach for multi-human 3D pose estimation and tracking based on calibrated multi-view. The main challenge lies in finding the cross-view and temporal correspondences correctly even when several human pose estimations are noisy. Compare to previous solutions that construct 3D poses from multiple views, our approach takes advantage of temporal consistency to match the 2D poses estimated with previously constructed 3D skeletons in every view. Therefore cross-view and temporal associations are accomplished simultaneously. Since the performance suffers from mistaken association and noisy predictions, we design two strategies for aiming better correspondences and 3D reconstruction. Specifically, we propose a part-aware measurement for 2D-3D association and a filter that can cope with 2D outliers during reconstruction. Our approach is efficient and effective comparing to state-of-the-art methods; it achieves competitive results on two benchmarks: 96.8% on Campus and 97.4% on Shelf. Moreover, we extends the length of Campus evaluation frames to be more challenging and our proposal also reach well-performed result.
Video-based Person Re-identification without Bells and Whistles
May 22, 2021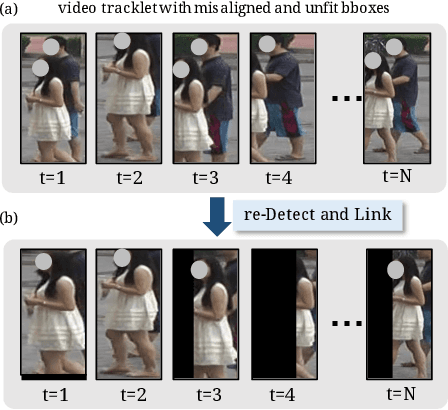
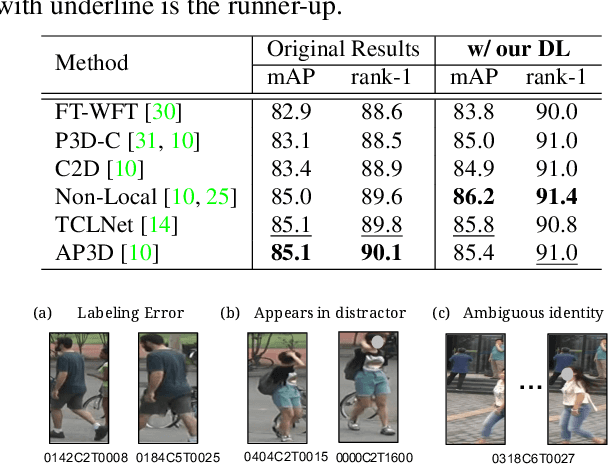
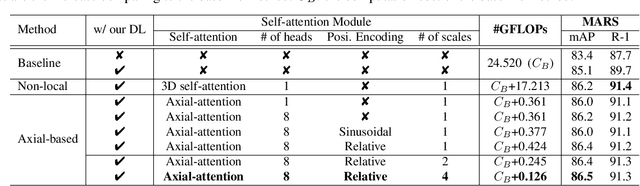
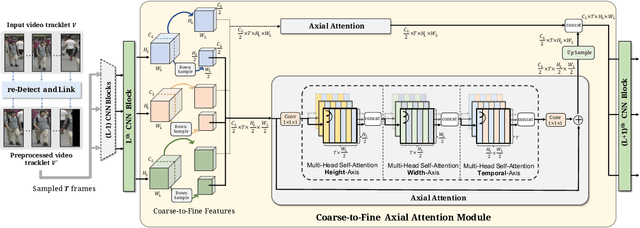
Video-based person re-identification (Re-ID) aims at matching the video tracklets with cropped video frames for identifying the pedestrians under different cameras. However, there exists severe spatial and temporal misalignment for those cropped tracklets due to the imperfect detection and tracking results generated with obsolete methods. To address this issue, we present a simple re-Detect and Link (DL) module which can effectively reduce those unexpected noise through applying the deep learning-based detection and tracking on the cropped tracklets. Furthermore, we introduce an improved model called Coarse-to-Fine Axial-Attention Network (CF-AAN). Based on the typical Non-local Network, we replace the non-local module with three 1-D position-sensitive axial attentions, in addition to our proposed coarse-to-fine structure. With the developed CF-AAN, compared to the original non-local operation, we can not only significantly reduce the computation cost but also obtain the state-of-the-art performance (91.3% in rank-1 and 86.5% in mAP) on the large-scale MARS dataset. Meanwhile, by simply adopting our DL module for data alignment, to our surprise, several baseline models can achieve better or comparable results with the current state-of-the-arts. Besides, we discover the errors not only for the identity labels of tracklets but also for the evaluation protocol for the test data of MARS. We hope that our work can help the community for the further development of invariant representation without the hassle of the spatial and temporal alignment and dataset noise. The code, corrected labels, evaluation protocol, and the aligned data will be available at https://github.com/jackie840129/CF-AAN.
Compacting, Picking and Growing for Unforgetting Continual Learning
Oct 30, 2019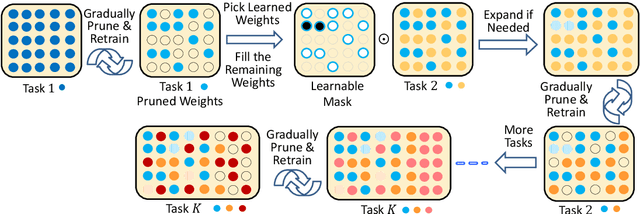

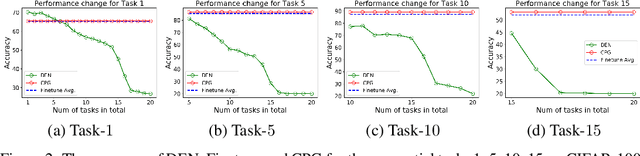
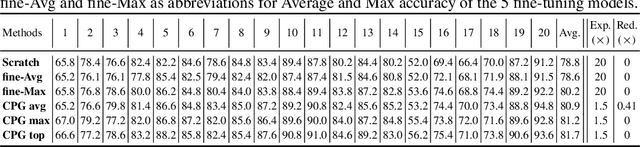
Continual lifelong learning is essential to many applications. In this paper, we propose a simple but effective approach to continual deep learning. Our approach leverages the principles of deep model compression, critical weights selection, and progressive networks expansion. By enforcing their integration in an iterative manner, we introduce an incremental learning method that is scalable to the number of sequential tasks in a continual learning process. Our approach is easy to implement and owns several favorable characteristics. First, it can avoid forgetting (i.e., learn new tasks while remembering all previous tasks). Second, it allows model expansion but can maintain the model compactness when handling sequential tasks. Besides, through our compaction and selection/expansion mechanism, we show that the knowledge accumulated through learning previous tasks is helpful to build a better model for the new tasks compared to training the models independently with tasks. Experimental results show that our approach can incrementally learn a deep model tackling multiple tasks without forgetting, while the model compactness is maintained with the performance more satisfiable than individual task training.
IMMVP: An Efficient Daytime and Nighttime On-Road Object Detector
Oct 28, 2019

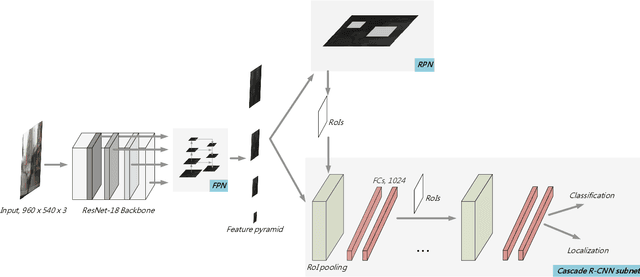

It is hard to detect on-road objects under various lighting conditions. To improve the quality of the classifier, three techniques are used. We define subclasses to separate daytime and nighttime samples. Then we skip similar samples in the training set to prevent overfitting. With the help of the outside training samples, the detection accuracy is also improved. To detect objects in an edge device, Nvidia Jetson TX2 platform, we exert the lightweight model ResNet-18 FPN as the backbone feature extractor. The FPN (Feature Pyramid Network) generates good features for detecting objects over various scales. With Cascade R-CNN technique, the bounding boxes are iteratively refined for better results.
Learning Conditional Random Fields with Augmented Observations for Partially Observed Action Recognition
Dec 05, 2018
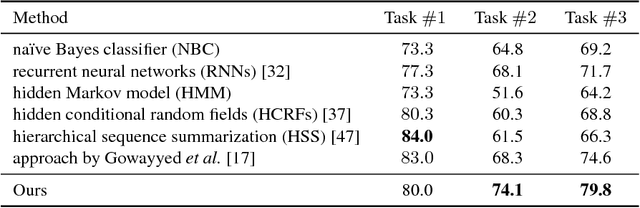
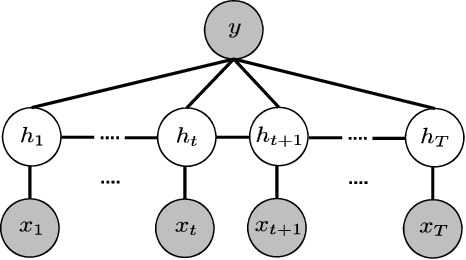
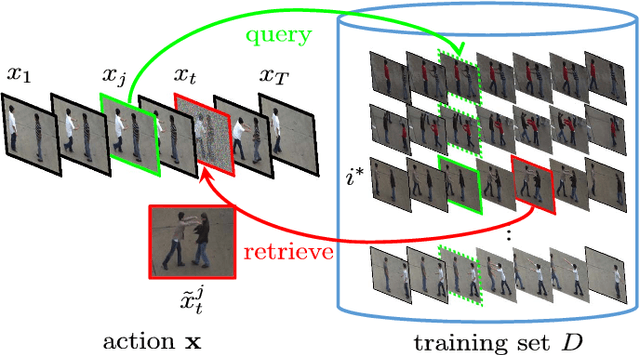
This paper aims at recognizing partially observed human actions in videos. Action videos acquired in uncontrolled environments often contain corrupt frames, which make actions partially observed. Furthermore, these frames can last for arbitrary lengths of time and appear irregularly. They are inconsistent with training data and degrade the performance of pre-trained action recognition systems. We present an approach to address this issue. For each training and testing actions, we divide it into segments and explore the mutual dependency between temporal segments. This property states that the similarity of two actions at one segment often implies their similarity at another. We augment each segment with extra alternatives retrieved from training data. The augmentation algorithm is designed in a way where a few alternatives are good enough to replace the original segment where corrupt frames occur. Our approach is developed upon hidden conditional random fields and leverages the flexibility of hidden variables for uncertainty handling. It turns out that our approach integrates corrupt segment detection and alternative selection into the process of prediction, and can recognize partially observed actions more accurately. It is evaluated on both fully observed actions and partially observed ones with either synthetic or real corrupt frames. The experimental results manifest its general applicability and superior performance, especially when corrupt frames are present in the action videos.
Data-specific Adaptive Threshold for Face Recognition and Authentication
Oct 26, 2018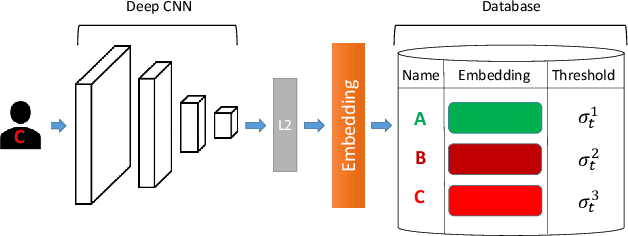
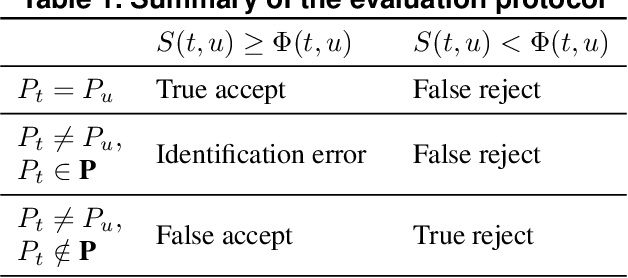
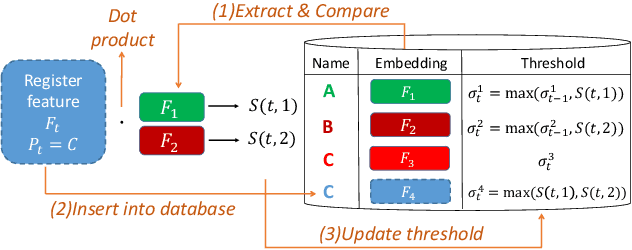
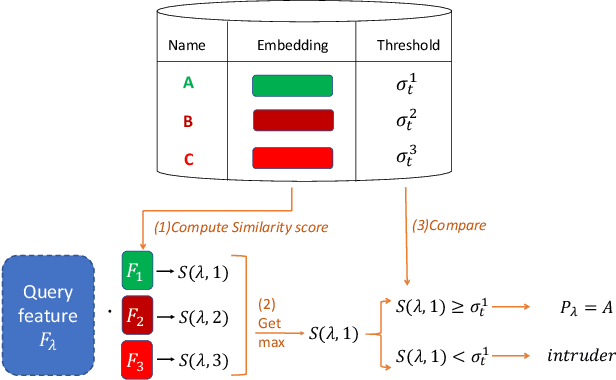
Many face recognition systems boost the performance using deep learning models, but only a few researches go into the mechanisms for dealing with online registration. Although we can obtain discriminative facial features through the state-of-the-art deep model training, how to decide the best threshold for practical use remains a challenge. We develop a technique of adaptive threshold mechanism to improve the recognition accuracy. We also design a face recognition system along with the registering procedure to handle online registration. Furthermore, we introduce a new evaluation protocol to better evaluate the performance of an algorithm for real-world scenarios. Under our proposed protocol, our method can achieve a 22\% accuracy improvement on the LFW dataset.
Stingray Detection of Aerial Images Using Augmented Training Images Generated by A Conditional Generative Model
Jun 25, 2018

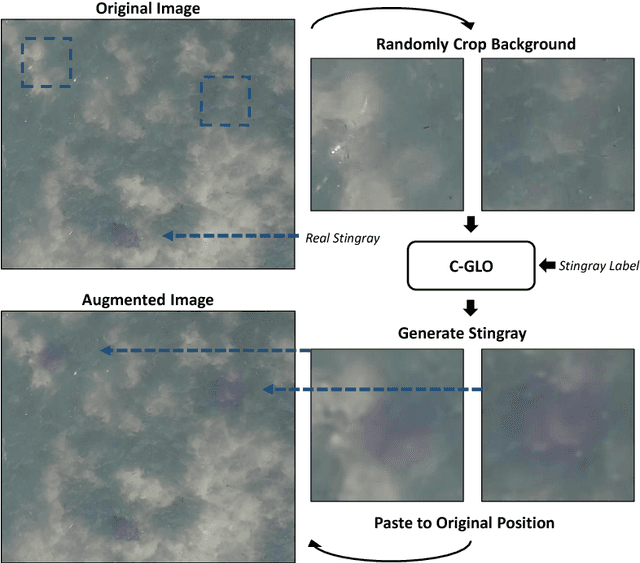
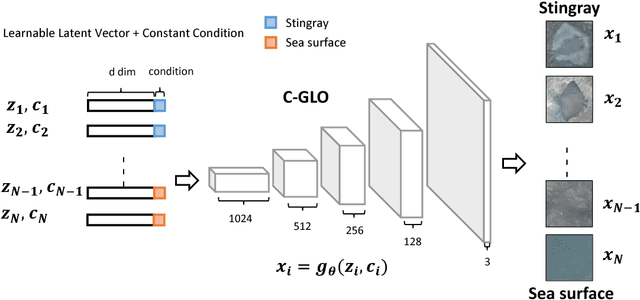
In this paper, we present an object detection method that tackles the stingray detection problem based on aerial images. In this problem, the images are aerially captured on a sea-surface area by using an Unmanned Aerial Vehicle (UAV), and the stingrays swimming under (but close to) the sea surface are the target we want to detect and locate. To this end, we use a deep object detection method, faster RCNN, to train a stingray detector based on a limited training set of images. To boost the performance, we develop a new generative approach, conditional GLO, to increase the training samples of stingray, which is an extension of the Generative Latent Optimization (GLO) approach. Unlike traditional data augmentation methods that generate new data only for image classification, our proposed method that mixes foreground and background together can generate new data for an object detection task, and thus improve the training efficacy of a CNN detector. Experimental results show that satisfiable performance can be obtained by using our approach on stingray detection in aerial images.