 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal RIS Placement in a Multi-User MISO System with User Randomness
Nov 06, 2025



It is well established that the performance of reconfigurable intelligent surface (RIS)-assisted systems critically depends on the optimal placement of the RIS. Previous works consider either simple coverage maximization or simultaneous optimization of the placement of the RIS along with the beamforming and reflection coefficients, most of which assume that the location of the RIS, base station (BS), and users are known. However, in practice, only the spatial variation of user density and obstacle configuration are likely to be known prior to deployment of the system. Thus, we formulate a non-convex problem that optimizes the position of the RIS over the expected minimum signal-to-interference-plus-noise ratio (SINR) of the system with user randomness, assuming that the system employs joint beamforming after deployment. To solve this problem, we propose a recursive coarse-to-fine methodology that constructs a set of candidate locations for RIS placement based on the obstacle configuration and evaluates them over multiple instantiations from the user distribution. The search is recursively refined within the optimal region identified in each stage to determine the final optimal region for RIS deployment. Numerical results are presented to corroborate our findings.
Coherence-Aware Distributed Learning under Heterogeneous Downlink Impairments
Oct 29, 2025The performance of federated learning (FL) over wireless networks critically depends on accurate and timely channel state information (CSI) across distributed devices. This requirement is tightly linked to how rapidly the channel gains vary, i.e., the coherence intervals. In practice, edge devices often exhibit unequal coherence times due to differences in mobility and scattering environments, leading to unequal demands for pilot signaling and channel estimation resources. Conventional FL schemes that overlook this coherence disparity can suffer from severe communication inefficiencies and training overhead. This paper proposes a coherence-aware, communication-efficient framework for joint channel training and model updating in practical wireless FL systems operating under heterogeneous fading dynamics. Focusing on downlink impairments, we introduce a resource-reuse strategy based on product superposition, enabling the parameter server to efficiently schedule both static and dynamic devices by embedding global model updates for static devices within pilot transmissions intended for mobile devices. We theoretically analyze the convergence behavior of the proposed scheme and quantify its gains in expected communication efficiency and training accuracy. Experiments demonstrate the effectiveness of the proposed framework under mobility-induced dynamics and offer useful insights for the practical deployment of FL over wireless channels.
TAP: Two-Stage Adaptive Personalization of Multi-task and Multi-Modal Foundation Models in Federated Learning
Sep 30, 2025



Federated Learning (FL), despite demonstrating impressive capabilities in the training of multiple models in a decentralized manner, has been shown to produce a final model not necessarily well-suited to the needs of each client. While extensive work has been conducted on how to create tailored personalized models, called Personalized Federated Learning (PFL), less attention has been given to personalization via fine-tuning of foundation models with multi-task and multi-modal properties. Moreover, there exists a lack of understanding in the literature on how to fine-tune and personalize such models in a setting that is heterogeneous across clients not only in data, but also in tasks and modalities. To address this gap in the literature, we propose TAP (Two-Stage Adaptive Personalization), which (i) leverages mismatched model architectures between the clients and server to selectively conduct replacement operations when it benefits a client's local tasks and (ii) engages in post-FL knowledge distillation for capturing beneficial general knowledge without compromising personalization. We also introduce the first convergence analysis of the server model under its modality-task pair architecture, and demonstrate that as the number of modality-task pairs increases, its ability to cater to all tasks suffers. Through extensive experiments, we demonstrate the effectiveness of our proposed algorithm across a variety of datasets and tasks in comparison to a multitude of baselines. Implementation code is publicly available at https://github.com/lee3296/TAP.
RCCDA: Adaptive Model Updates in the Presence of Concept Drift under a Constrained Resource Budget
May 30, 2025


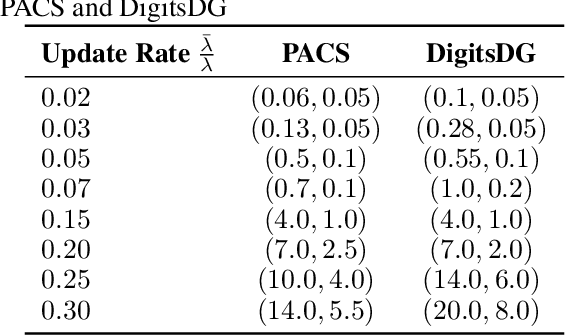
Machine learning (ML) algorithms deployed in real-world environments are often faced with the challenge of adapting models to concept drift, where the task data distributions are shifting over time. The problem becomes even more difficult when model performance must be maintained under adherence to strict resource constraints. Existing solutions often depend on drift-detection methods that produce high computational overhead for resource-constrained environments, and fail to provide strict guarantees on resource usage or theoretical performance assurances. To address these shortcomings, we propose RCCDA: a dynamic model update policy that optimizes ML training dynamics while ensuring strict compliance to predefined resource constraints, utilizing only past loss information and a tunable drift threshold. In developing our policy, we analytically characterize the evolution of model loss under concept drift with arbitrary training update decisions. Integrating these results into a Lyapunov drift-plus-penalty framework produces a lightweight policy based on a measurable accumulated loss threshold that provably limits update frequency and cost. Experimental results on three domain generalization datasets demonstrate that our policy outperforms baseline methods in inference accuracy while adhering to strict resource constraints under several schedules of concept drift, making our solution uniquely suited for real-time ML deployments.
Federated Learning for Cyber Physical Systems: A Comprehensive Survey
May 08, 2025The integration of machine learning (ML) in cyber physical systems (CPS) is a complex task due to the challenges that arise in terms of real-time decision making, safety, reliability, device heterogeneity, and data privacy. There are also open research questions that must be addressed in order to fully realize the potential of ML in CPS. Federated learning (FL), a distributed approach to ML, has become increasingly popular in recent years. It allows models to be trained using data from decentralized sources. This approach has been gaining popularity in the CPS field, as it integrates computer, communication, and physical processes. Therefore, the purpose of this work is to provide a comprehensive analysis of the most recent developments of FL-CPS, including the numerous application areas, system topologies, and algorithms developed in recent years. The paper starts by discussing recent advances in both FL and CPS, followed by their integration. Then, the paper compares the application of FL in CPS with its applications in the internet of things (IoT) in further depth to show their connections and distinctions. Furthermore, the article scrutinizes how FL is utilized in critical CPS applications, e.g., intelligent transportation systems, cybersecurity services, smart cities, and smart healthcare solutions. The study also includes critical insights and lessons learned from various FL-CPS implementations. The paper's concluding section delves into significant concerns and suggests avenues for further research in this fast-paced and dynamic era.
Learning-Based Two-Way Communications: Algorithmic Framework and Comparative Analysis
Apr 22, 2025



Machine learning (ML)-based feedback channel coding has garnered significant research interest in the past few years. However, there has been limited research exploring ML approaches in the so-called "two-way" setting where two users jointly encode messages and feedback for each other over a shared channel. In this work, we present a general architecture for ML-based two-way feedback coding, and show how several popular one-way schemes can be converted to the two-way setting through our framework. We compare such schemes against their one-way counterparts, revealing error-rate benefits of ML-based two-way coding in certain signal-to-noise ratio (SNR) regimes. We then analyze the tradeoffs between error performance and computational overhead for three state-of-the-art neural network coding models instantiated in the two-way paradigm.
Communication-Efficient Cooperative Localization: A Graph Neural Network Approach
Apr 10, 2025Cooperative localization leverages noisy inter-node distance measurements and exchanged wireless messages to estimate node positions in a wireless network. In communication-constrained environments, however, transmitting large messages becomes problematic. In this paper, we propose an approach for communication-efficient cooperative localization that addresses two main challenges. First, cooperative localization often needs to be performed over wireless networks with loopy graph topologies. Second is the need for designing an algorithm that has low localization error while simultaneously requiring a much lower communication overhead. Existing methods fall short of addressing these two challenges concurrently. To achieve this, we propose a vector quantized message passing neural network (VQ-MPNN) for cooperative localization. Through end-to-end neural network training, VQ-MPNN enables the co-design of node localization and message compression. Specifically, VQ-MPNN treats prior node positions and distance measurements as node and edge features, respectively, which are encoded as node and edge states using a graph neural network. To find an efficient representation for the node state, we construct a vector quantized codebook for all node states such that instead of sending long messages, each node only needs to transmit a codeword index. Numerical evaluations demonstrates that our proposed VQ-MPNN approach can deliver localization errors that are similar to existing approaches while reducing the overall communication overhead by an order of magnitude.
Decentralized Federated Domain Generalization with Style Sharing: A Formal Modeling and Convergence Analysis
Apr 08, 2025



Much of the federated learning (FL) literature focuses on settings where local dataset statistics remain the same between training and testing time. Recent advances in domain generalization (DG) aim to use data from source (training) domains to train a model that generalizes well to data from unseen target (testing) domains. In this paper, we are motivated by two major gaps in existing work on FL and DG: (1) the lack of formal mathematical analysis of DG objectives and training processes; and (2) DG research in FL being limited to the conventional star-topology architecture. Addressing the second gap, we develop $\textit{Decentralized Federated Domain Generalization with Style Sharing}$ ($\texttt{StyleDDG}$), a fully decentralized DG algorithm designed to allow devices in a peer-to-peer network to achieve DG based on sharing style information inferred from their datasets. Additionally, we fill the first gap by providing the first systematic approach to mathematically analyzing style-based DG training optimization. We cast existing centralized DG algorithms within our framework, and employ their formalisms to model $\texttt{StyleDDG}$. Based on this, we obtain analytical conditions under which a sub-linear convergence rate of $\texttt{StyleDDG}$ can be obtained. Through experiments on two popular DG datasets, we demonstrate that $\texttt{StyleDDG}$ can obtain significant improvements in accuracy across target domains with minimal added communication overhead compared to decentralized gradient methods that do not employ style sharing.
Multi-Agent Reinforcement Learning for Graph Discovery in D2D-Enabled Federated Learning
Mar 29, 2025Augmenting federated learning (FL) with device-to-device (D2D) communications can help improve convergence speed and reduce model bias through local information exchange. However, data privacy concerns, trust constraints between devices, and unreliable wireless channels each pose challenges in finding an effective yet resource efficient D2D graph structure. In this paper, we develop a decentralized reinforcement learning (RL) method for D2D graph discovery that promotes communication of impactful datapoints over reliable links for multiple learning paradigms, while following both data and device-specific trust constraints. An independent RL agent at each device trains a policy to predict the impact of incoming links in a decentralized manner without exposure of local data or significant communication overhead. For supervised settings, the D2D graph aims to improve device-specific label diversity without compromising system-level performance. For semi-supervised settings, we enable this by incorporating distributed label propagation. For unsupervised settings, we develop a variation-based diversity metric which estimates data diversity in terms of occupied latent space. Numerical experiments on five widely used datasets confirm that the data diversity improvements induced by our method increase convergence speed by up to 3 times while reducing energy consumption by up to 5 times. They also show that our method is resilient to stragglers and changes in the aggregation interval. Finally, we show that our method offers scalability benefits for larger system sizes without increases in relative overhead, and adaptability to various downstream FL architectures and to dynamic wireless environments.
Physics-Informed Generative Approaches for Wireless Channel Modeling
Mar 11, 2025



In recent years, machine learning (ML) methods have become increasingly popular in wireless communication systems for several applications. A critical bottleneck for designing ML systems for wireless communications is the availability of realistic wireless channel datasets, which are extremely resource intensive to produce. To this end, the generation of realistic wireless channels plays a key role in the subsequent design of effective ML algorithms for wireless communication systems. Generative models have been proposed to synthesize channel matrices, but outputs produced by such methods may not correspond to geometrically viable channels and do not provide any insight into the scenario of interest. In this work, we aim to address both these issues by integrating a parametric, physics-based geometric channel (PBGC) modeling framework with generative methods. To address limitations with gradient flow through the PBGC model, a linearized reformulation is presented, which ensures smooth gradient flow during generative model training, while also capturing insights about the underlying physical environment. We evaluate our model against prior baselines by comparing the generated samples in terms of the 2-Wasserstein distance and through the utility of generated data when used for downstream compression tasks.