 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Realism and Interpretability in Wireless Channel Synthesis: A Physics-Guided Generative Approach
Jun 22, 2026In recent years, machine learning (ML) methods have become increasingly popular for wireless communication systems. These require large amounts of data reflecting the behavior of realistic channels with high fidelity. However, sampling over-the-air (OTA) channel data is an extremely resource-intensive process which cannot accurately represent the variety of real world channels. This results in the need for realistic training data for ML systems. To this end, generative models have been proposed to synthesize channel data. However,(i) the outputs produced by such methods may not correspond to physically viable channels, (ii) the outputs may not provide insights into the associated environment, and (iii) training the generative model may need labeled data, requiring resource intensive data annotation. Through this work, we address these issues by integrating a parametric, physics-based geometric channel (PPGC) modeling framework derived from planar wave propagation equations, with generative methods to produce realistic channel matrices with interpretable representations in the parameter domain. To overcome the limitations of the resulting non-convex optimization landscape, we propose a linearized reformulation of the PPGC model to ensure smooth gradient flow during training, while also providing insights into the underlying physical environment. We incorporate a tensor decomposition framework into the linearized reformulation to allow for flexibility in the number of wireless channel parameters. We also show the compatibility of this reformulation with parameter extraction tasks. We evaluate our model against prior baselines by comparing generated, scenario-specific samples to true channels in terms of their similarity and through their utility in downstream compression tasks.
From Fewer Samples to Fewer Bits: Reframing Dataset Distillation as Joint Optimization of Precision and Compactness
Mar 02, 2026Dataset Distillation (DD) compresses large datasets into compact synthetic ones that maintain training performance. However, current methods mainly target sample reduction, with limited consideration of data precision and its impact on efficiency. We propose Quantization-aware Dataset Distillation (QuADD), a unified framework that jointly optimizes dataset compactness and precision under fixed bit budgets. QuADD integrates a differentiable quantization module within the distillation loop, enabling end-to-end co-optimization of synthetic samples and quantization parameters. Guided by the rate-distortion perspective, we empirically analyze how bit allocation between sample count and precision influences learning performance. Our framework supports both uniform and adaptive non-uniform quantization, where the latter learns quantization levels from data to represent information-dense regions better. Experiments on image classification and 3GPP beam management tasks show that QuADD surpasses existing DD and post-quantized baselines in accuracy per bit, establishing a new standard for information-efficient dataset distillation.
Physics-Informed Generative Approaches for Wireless Channel Modeling
Mar 11, 2025



In recent years, machine learning (ML) methods have become increasingly popular in wireless communication systems for several applications. A critical bottleneck for designing ML systems for wireless communications is the availability of realistic wireless channel datasets, which are extremely resource intensive to produce. To this end, the generation of realistic wireless channels plays a key role in the subsequent design of effective ML algorithms for wireless communication systems. Generative models have been proposed to synthesize channel matrices, but outputs produced by such methods may not correspond to geometrically viable channels and do not provide any insight into the scenario of interest. In this work, we aim to address both these issues by integrating a parametric, physics-based geometric channel (PBGC) modeling framework with generative methods. To address limitations with gradient flow through the PBGC model, a linearized reformulation is presented, which ensures smooth gradient flow during generative model training, while also capturing insights about the underlying physical environment. We evaluate our model against prior baselines by comparing the generated samples in terms of the 2-Wasserstein distance and through the utility of generated data when used for downstream compression tasks.
General Total Variation Regularized Sparse Bayesian Learning for Robust Block-Sparse Signal Recovery
Feb 16, 2021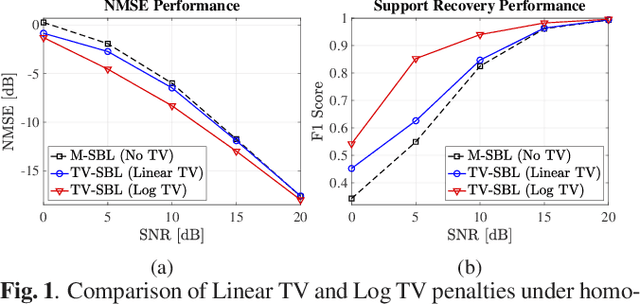
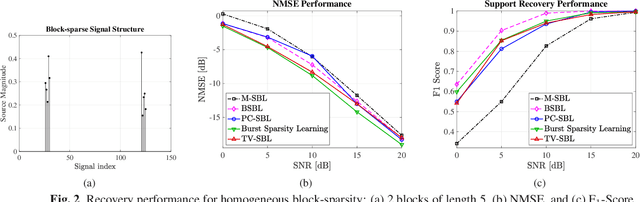
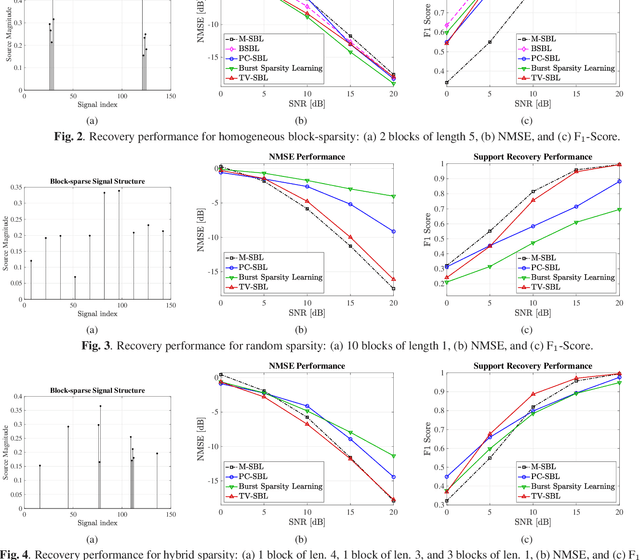
Block-sparse signal recovery without knowledge of block sizes and boundaries, such as those encountered in multi-antenna mmWave channel models, is a hard problem for compressed sensing (CS) algorithms. We propose a novel Sparse Bayesian Learning (SBL) method for block-sparse recovery based on popular CS based regularizers with the function input variable related to total variation (TV). Contrary to conventional approaches that impose the regularization on the signal components, we regularize the SBL hyperparameters. This iterative TV-regularized SBL algorithm employs a majorization-minimization approach and reduces each iteration to a convex optimization problem, enabling a flexible choice of numerical solvers. The numerical results illustrate that the TV-regularized SBL algorithm is robust to the nature of the block structure and able to recover signals with both block-patterned and isolated components, proving useful for various signal recovery systems.