 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRekall: Specifying Video Events using Compositions of Spatiotemporal Labels
Oct 07, 2019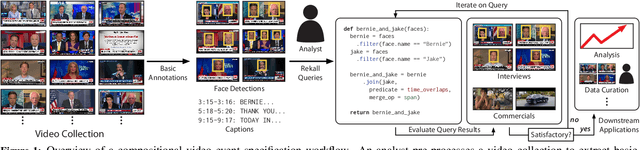
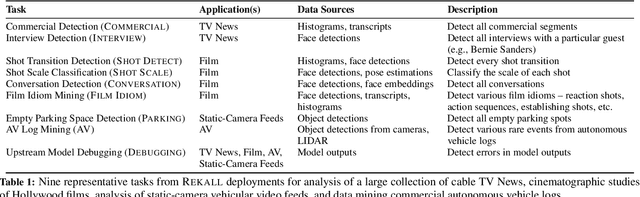
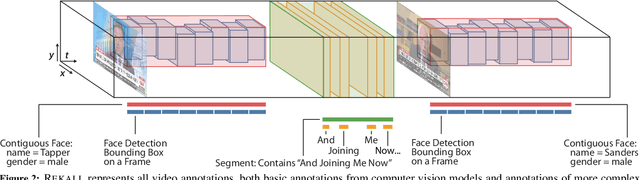

Many real-world video analysis applications require the ability to identify domain-specific events in video, such as interviews and commercials in TV news broadcasts, or action sequences in film. Unfortunately, pre-trained models to detect all the events of interest in video may not exist, and training new models from scratch can be costly and labor-intensive. In this paper, we explore the utility of specifying new events in video in a more traditional manner: by writing queries that compose outputs of existing, pre-trained models. To write these queries, we have developed Rekall, a library that exposes a data model and programming model for compositional video event specification. Rekall represents video annotations from different sources (object detectors, transcripts, etc.) as spatiotemporal labels associated with continuous volumes of spacetime in a video, and provides operators for composing labels into queries that model new video events. We demonstrate the use of Rekall in analyzing video from cable TV news broadcasts, films, static-camera vehicular video streams, and commercial autonomous vehicle logs. In these efforts, domain experts were able to quickly (in a few hours to a day) author queries that enabled the accurate detection of new events (on par with, and in some cases much more accurate than, learned approaches) and to rapidly retrieve video clips for human-in-the-loop tasks such as video content curation and training data curation. Finally, in a user study, novice users of Rekall were able to author queries to retrieve new events in video given just one hour of query development time.
Hidden Stratification Causes Clinically Meaningful Failures in Machine Learning for Medical Imaging
Sep 27, 2019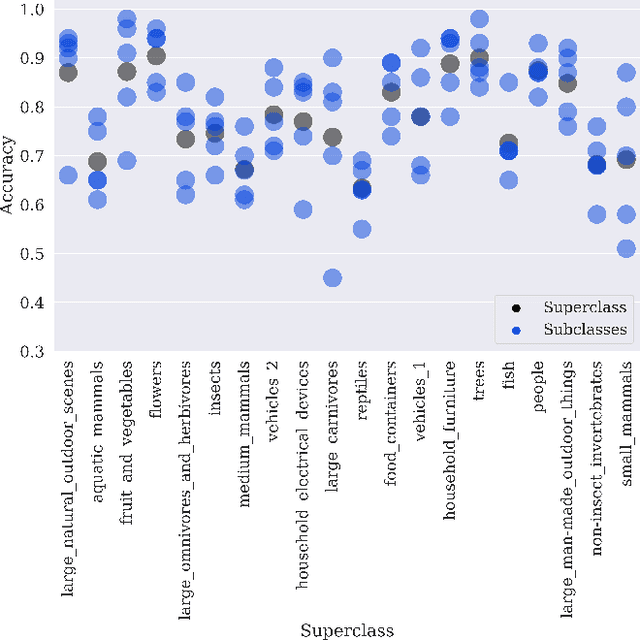

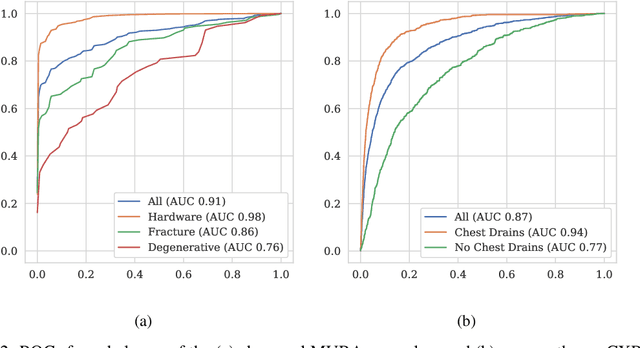
Machine learning models for medical image analysis often suffer from poor performance on important subsets of a population that are not identified during training or testing. For example, overall performance of a cancer detection model may be high, but the model still consistently misses a rare but aggressive cancer subtype. We refer to this problem as hidden stratification, and observe that it results from incompletely describing the meaningful variation in a dataset. While hidden stratification can substantially reduce the clinical efficacy of machine learning models, its effects remain difficult to measure. In this work, we assess the utility of several possible techniques for measuring and describing hidden stratification effects, and characterize these effects both on multiple medical imaging datasets and via synthetic experiments on the well-characterised CIFAR-100 benchmark dataset. We find evidence that hidden stratification can occur in unidentified imaging subsets with low prevalence, low label quality, subtle distinguishing features, or spurious correlates, and that it can result in relative performance differences of over 20% on clinically important subsets. Finally, we explore the clinical implications of our findings, and suggest that evaluation of hidden stratification should be a critical component of any machine learning deployment in medical imaging.
Slice-based Learning: A Programming Model for Residual Learning in Critical Data Slices
Sep 13, 2019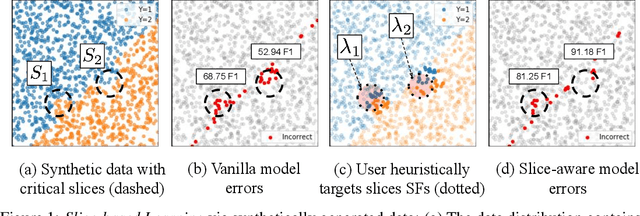
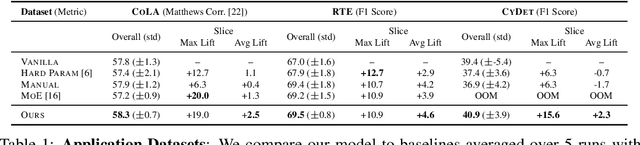
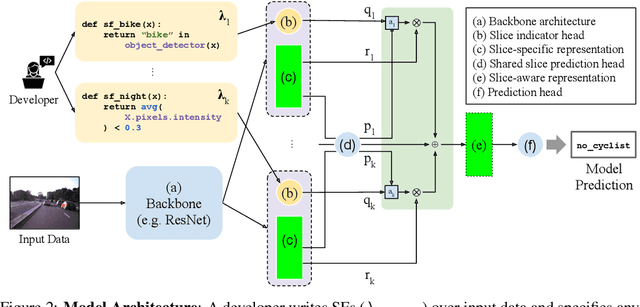
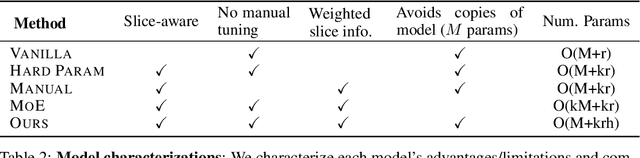
In real-world machine learning applications, data subsets correspond to especially critical outcomes: vulnerable cyclist detections are safety-critical in an autonomous driving task, and "question" sentences might be important to a dialogue agent's language understanding for product purposes. While machine learning models can achieve high quality performance on coarse-grained metrics like F1-score and overall accuracy, they may underperform on critical subsets---we define these as slices, the key abstraction in our approach. To address slice-level performance, practitioners often train separate "expert" models on slice subsets or use multi-task hard parameter sharing. We propose Slice-based Learning, a new programming model in which the slicing function (SF), a programming interface, specifies critical data subsets for which the model should commit additional capacity. Any model can leverage SFs to learn slice expert representations, which are combined with an attention mechanism to make slice-aware predictions. We show that our approach maintains a parameter-efficient representation while improving over baselines by up to 19.0 F1 on slices and 4.6 F1 overall on datasets spanning language understanding (e.g. SuperGLUE), computer vision, and production-scale industrial systems.
Overton: A Data System for Monitoring and Improving Machine-Learned Products
Sep 07, 2019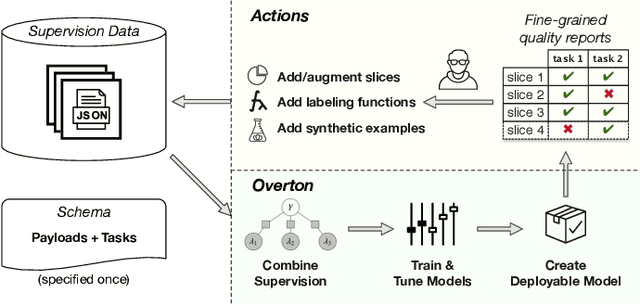
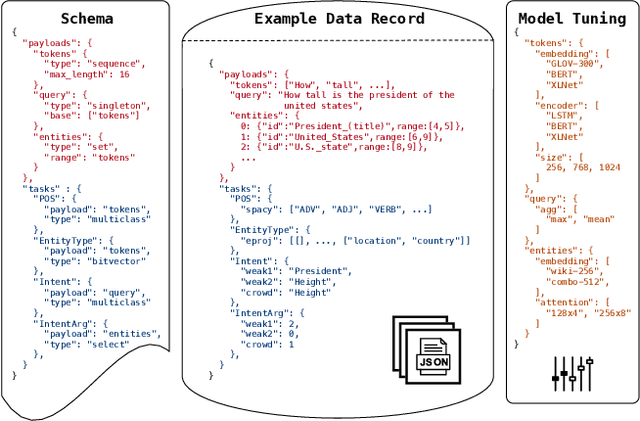

We describe a system called Overton, whose main design goal is to support engineers in building, monitoring, and improving production machine learning systems. Key challenges engineers face are monitoring fine-grained quality, diagnosing errors in sophisticated applications, and handling contradictory or incomplete supervision data. Overton automates the life cycle of model construction, deployment, and monitoring by providing a set of novel high-level, declarative abstractions. Overton's vision is to shift developers to these higher-level tasks instead of lower-level machine learning tasks. In fact, using Overton, engineers can build deep-learning-based applications without writing any code in frameworks like TensorFlow. For over a year, Overton has been used in production to support multiple applications in both near-real-time applications and back-of-house processing. In that time, Overton-based applications have answered billions of queries in multiple languages and processed trillions of records reducing errors 1.7-2.9 times versus production systems.
On the Downstream Performance of Compressed Word Embeddings
Sep 03, 2019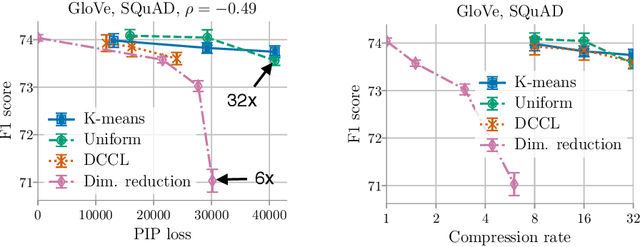
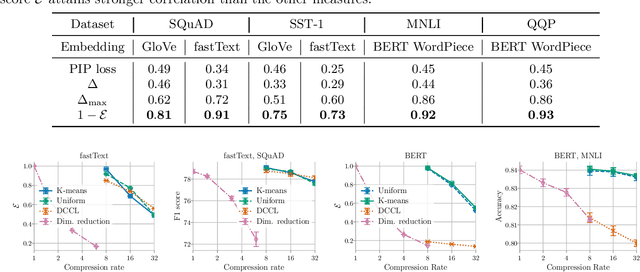
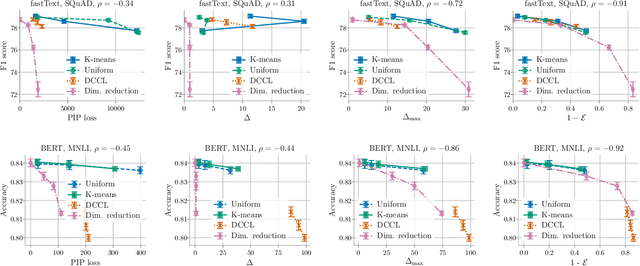
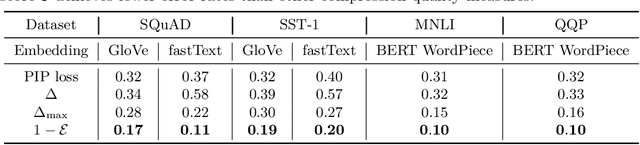
Compressing word embeddings is important for deploying NLP models in memory-constrained settings. However, understanding what makes compressed embeddings perform well on downstream tasks is challenging---existing measures of compression quality often fail to distinguish between embeddings that perform well and those that do not. We thus propose the eigenspace overlap score as a new measure. We relate the eigenspace overlap score to downstream performance by developing generalization bounds for the compressed embeddings in terms of this score, in the context of linear and logistic regression. We then show that we can lower bound the eigenspace overlap score for a simple uniform quantization compression method, helping to explain the strong empirical performance of this method. Finally, we show that by using the eigenspace overlap score as a selection criterion between embeddings drawn from a representative set we compressed, we can efficiently identify the better performing embedding with up to $2\times$ lower selection error rates than the next best measure of compression quality, and avoid the cost of training a model for each task of interest.
SysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
Low-Memory Neural Network Training: A Technical Report
Apr 24, 2019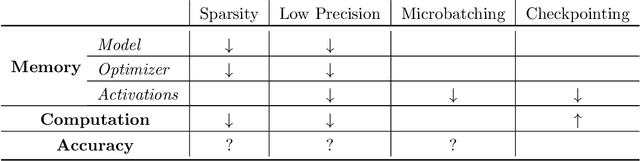
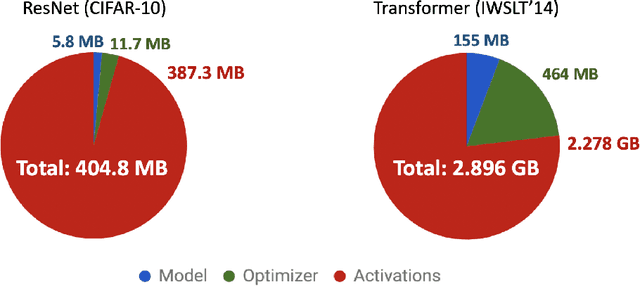
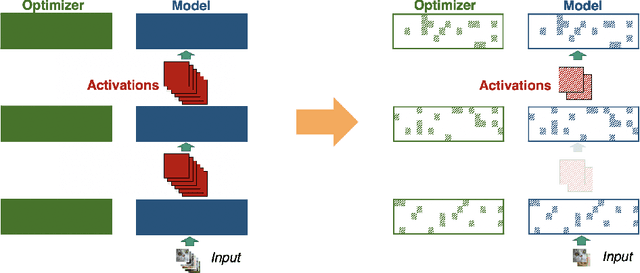

Memory is increasingly often the bottleneck when training neural network models. Despite this, techniques to lower the overall memory requirements of training have been less widely studied compared to the extensive literature on reducing the memory requirements of inference. In this paper we study a fundamental question: How much memory is actually needed to train a neural network? To answer this question, we profile the overall memory usage of training on two representative deep learning benchmarks -- the WideResNet model for image classification and the DynamicConv Transformer model for machine translation -- and comprehensively evaluate four standard techniques for reducing the training memory requirements: (1) imposing sparsity on the model, (2) using low precision, (3) microbatching, and (4) gradient checkpointing. We explore how each of these techniques in isolation affects both the peak memory usage of training and the quality of the end model, and explore the memory, accuracy, and computation tradeoffs incurred when combining these techniques. Using appropriate combinations of these techniques, we show that it is possible to the reduce the memory required to train a WideResNet-28-2 on CIFAR-10 by up to 60.7x with a 0.4% loss in accuracy, and reduce the memory required to train a DynamicConv model on IWSLT'14 German to English translation by up to 8.7x with a BLEU score drop of 0.15.
Medical device surveillance with electronic health records
Apr 03, 2019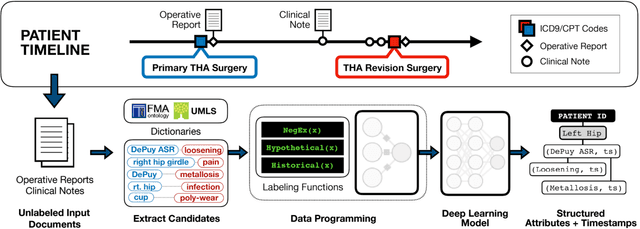
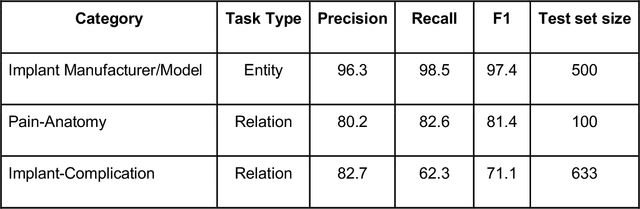

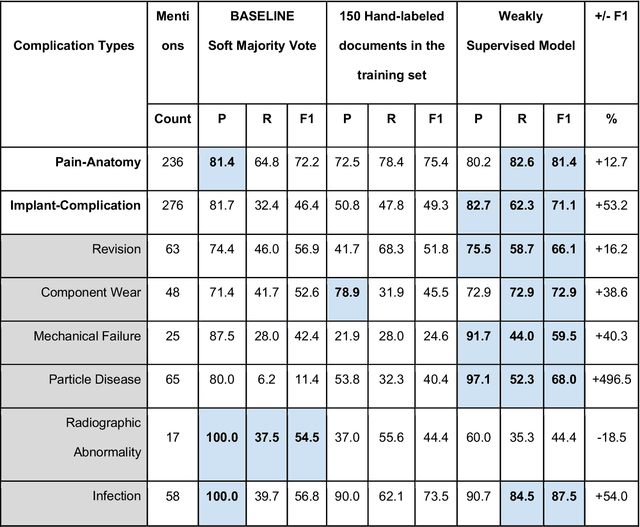
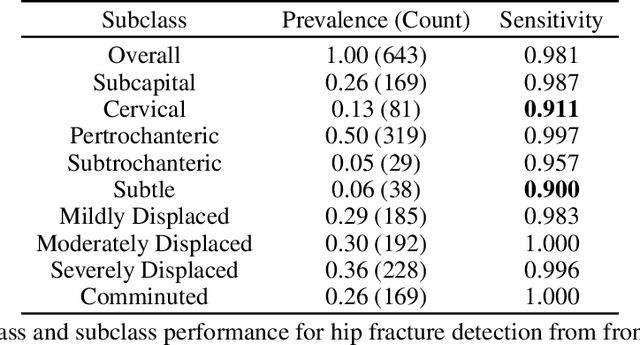
Post-market medical device surveillance is a challenge facing manufacturers, regulatory agencies, and health care providers. Electronic health records are valuable sources of real world evidence to assess device safety and track device-related patient outcomes over time. However, distilling this evidence remains challenging, as information is fractured across clinical notes and structured records. Modern machine learning methods for machine reading promise to unlock increasingly complex information from text, but face barriers due to their reliance on large and expensive hand-labeled training sets. To address these challenges, we developed and validated state-of-the-art deep learning methods that identify patient outcomes from clinical notes without requiring hand-labeled training data. Using hip replacements as a test case, our methods accurately extracted implant details and reports of complications and pain from electronic health records with up to 96.3% precision, 98.5% recall, and 97.4% F1, improved classification performance by 12.7- 53.0% over rule-based methods, and detected over 6 times as many complication events compared to using structured data alone. Using these events to assess complication-free survivorship of different implant systems, we found significant variation between implants, including for risk of revision surgery, which could not be detected using coded data alone. Patients with revision surgeries had more hip pain mentions in the post-hip replacement, pre-revision period compared to patients with no evidence of revision surgery (mean hip pain mentions 4.97 vs. 3.23; t = 5.14; p < 0.001). Some implant models were associated with higher or lower rates of hip pain mentions. Our methods complement existing surveillance mechanisms by requiring orders of magnitude less hand-labeled training data, offering a scalable solution for national medical device surveillance.
Cross-Modal Data Programming Enables Rapid Medical Machine Learning
Mar 26, 2019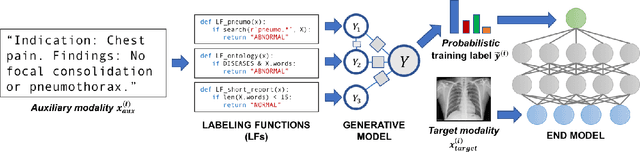
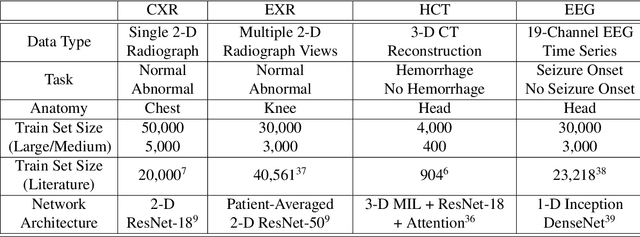
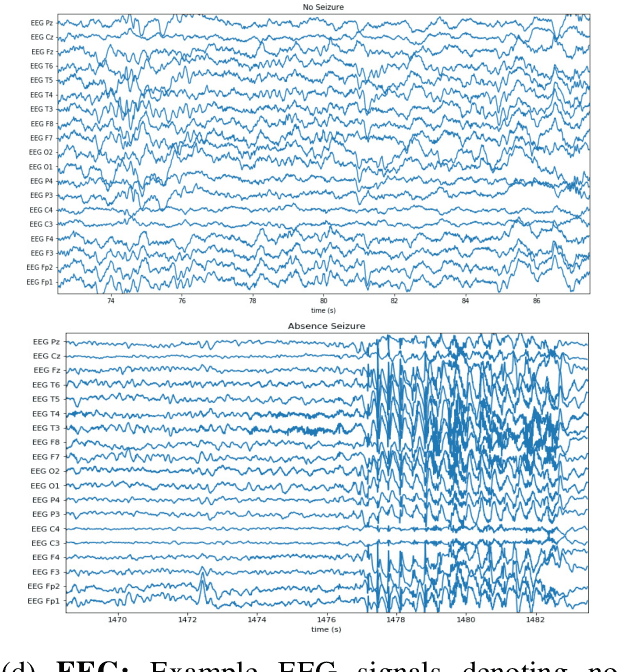

Labeling training datasets has become a key barrier to building medical machine learning models. One strategy is to generate training labels programmatically, for example by applying natural language processing pipelines to text reports associated with imaging studies. We propose cross-modal data programming, which generalizes this intuitive strategy in a theoretically-grounded way that enables simpler, clinician-driven input, reduces required labeling time, and improves with additional unlabeled data. In this approach, clinicians generate training labels for models defined over a target modality (e.g. images or time series) by writing rules over an auxiliary modality (e.g. text reports). The resulting technical challenge consists of estimating the accuracies and correlations of these rules; we extend a recent unsupervised generative modeling technique to handle this cross-modal setting in a provably consistent way. Across four applications in radiography, computed tomography, and electroencephalography, and using only several hours of clinician time, our approach matches or exceeds the efficacy of physician-months of hand-labeling with statistical significance, demonstrating a fundamentally faster and more flexible way of building machine learning models in medicine.
Learning Fast Algorithms for Linear Transforms Using Butterfly Factorizations
Mar 14, 2019
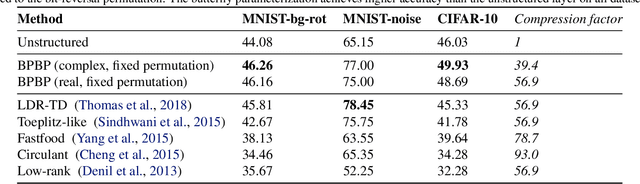
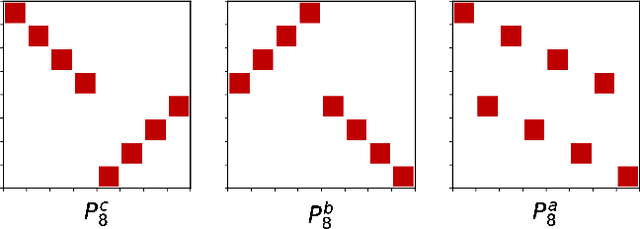

Fast linear transforms are ubiquitous in machine learning, including the discrete Fourier transform, discrete cosine transform, and other structured transformations such as convolutions. All of these transforms can be represented by dense matrix-vector multiplication, yet each has a specialized and highly efficient (subquadratic) algorithm. We ask to what extent hand-crafting these algorithms and implementations is necessary, what structural priors they encode, and how much knowledge is required to automatically learn a fast algorithm for a provided structured transform. Motivated by a characterization of fast matrix-vector multiplication as products of sparse matrices, we introduce a parameterization of divide-and-conquer methods that is capable of representing a large class of transforms. This generic formulation can automatically learn an efficient algorithm for many important transforms; for example, it recovers the $O(N \log N)$ Cooley-Tukey FFT algorithm to machine precision, for dimensions $N$ up to $1024$. Furthermore, our method can be incorporated as a lightweight replacement of generic matrices in machine learning pipelines to learn efficient and compressible transformations. On a standard task of compressing a single hidden-layer network, our method exceeds the classification accuracy of unconstrained matrices on CIFAR-10 by 3.9 points---the first time a structured approach has done so---with 4X faster inference speed and 40X fewer parameters.