 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Improving Information Transfer in Multi-Task Learning
May 02, 2020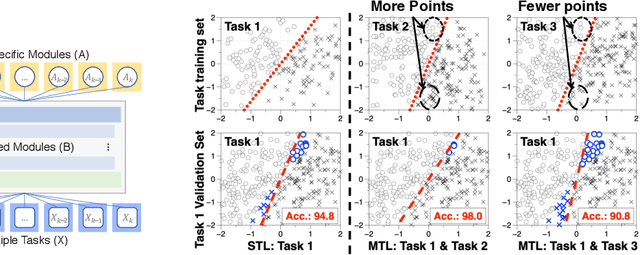

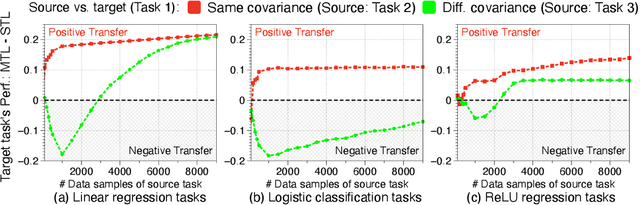
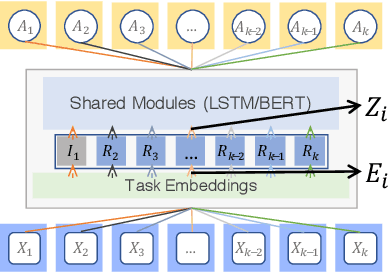
We investigate multi-task learning approaches that use a shared feature representation for all tasks. To better understand the transfer of task information, we study an architecture with a shared module for all tasks and a separate output module for each task. We study the theory of this setting on linear and ReLU-activated models. Our key observation is that whether or not tasks' data are well-aligned can significantly affect the performance of multi-task learning. We show that misalignment between task data can cause negative transfer (or hurt performance) and provide sufficient conditions for positive transfer. Inspired by the theoretical insights, we show that aligning tasks' embedding layers leads to performance gains for multi-task training and transfer learning on the GLUE benchmark and sentiment analysis tasks; for example, we obtain a 2.35% GLUE score average improvement on 5 GLUE tasks over BERT-LARGE using our alignment method. We also design an SVD-based task reweighting scheme and show that it improves the robustness of multi-task training on a multi-label image dataset.
On the Generalization Effects of Linear Transformations in Data Augmentation
May 02, 2020
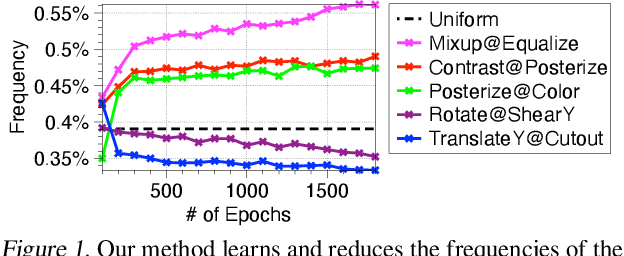
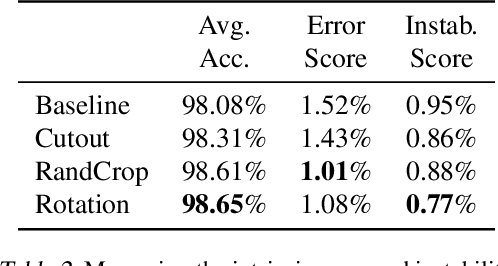
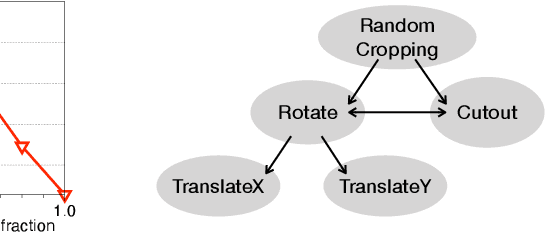
Data augmentation is a powerful technique to improve performance in applications such as image and text classification tasks. Yet, there is little rigorous understanding of why and how various augmentations work. In this work, we consider a family of linear transformations and study their effects on the ridge estimator in an over-parametrized linear regression setting. First, we show that transformations which preserve the labels of the data can improve estimation by enlarging the span of the training data. Second, we show that transformations which mix data can improve estimation by playing a regularization effect. Finally, we validate our theoretical insights on MNIST. Based on the insights, we propose an augmentation scheme that searches over the space of transformations by how uncertain the model is about the transformed data. We validate our proposed scheme on image and text datasets. For example, our method outperforms RandAugment by 1.24% on CIFAR-100 using Wide-ResNet-28-10. Furthermore, we achieve comparable accuracy to the SoTA Adversarial AutoAugment on CIFAR datasets.
Low-Dimensional Hyperbolic Knowledge Graph Embeddings
May 01, 2020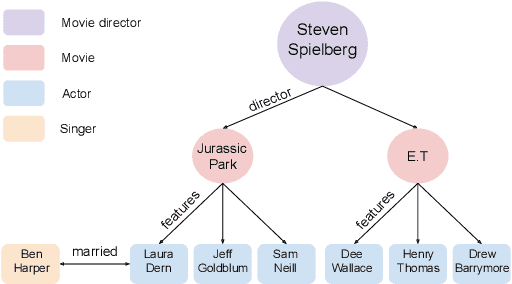
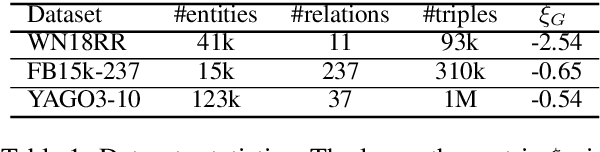
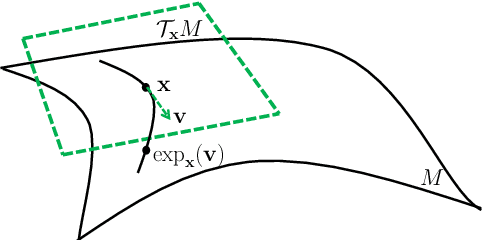
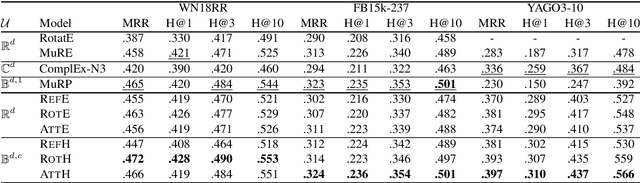
Knowledge graph (KG) embeddings learn low-dimensional representations of entities and relations to predict missing facts. KGs often exhibit hierarchical and logical patterns which must be preserved in the embedding space. For hierarchical data, hyperbolic embedding methods have shown promise for high-fidelity and parsimonious representations. However, existing hyperbolic embedding methods do not account for the rich logical patterns in KGs. In this work, we introduce a class of hyperbolic KG embedding models that simultaneously capture hierarchical and logical patterns. Our approach combines hyperbolic reflections and rotations with attention to model complex relational patterns. Experimental results on standard KG benchmarks show that our method improves over previous Euclidean- and hyperbolic-based efforts by up to 6.1% in mean reciprocal rank (MRR) in low dimensions. Furthermore, we observe that different geometric transformations capture different types of relations while attention-based transformations generalize to multiple relations. In high dimensions, our approach yields new state-of-the-art MRRs of 49.6% on WN18RR and 57.7% on YAGO3-10.
Ivy: Instrumental Variable Synthesis for Causal Inference
Apr 11, 2020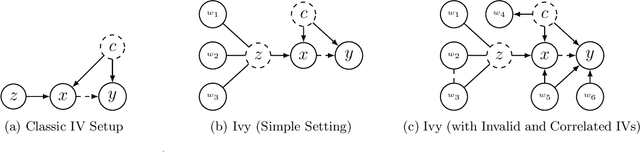
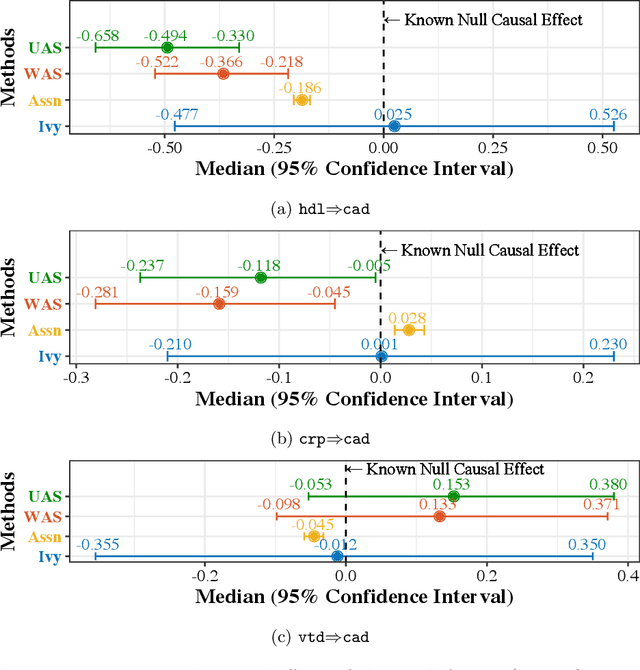
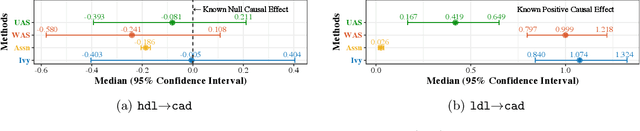
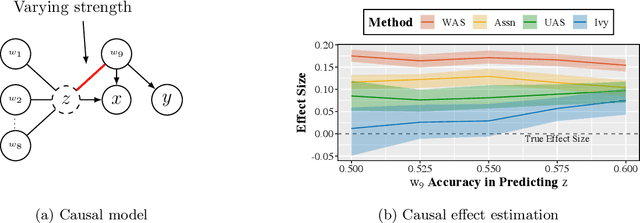
A popular way to estimate the causal effect of a variable x on y from observational data is to use an instrumental variable (IV): a third variable z that affects y only through x. The more strongly z is associated with x, the more reliable the estimate is, but such strong IVs are difficult to find. Instead, practitioners combine more commonly available IV candidates---which are not necessarily strong, or even valid, IVs---into a single "summary" that is plugged into causal effect estimators in place of an IV. In genetic epidemiology, such approaches are known as allele scores. Allele scores require strong assumptions---independence and validity of all IV candidates---for the resulting estimate to be reliable. To relax these assumptions, we propose Ivy, a new method to combine IV candidates that can handle correlated and invalid IV candidates in a robust manner. Theoretically, we characterize this robustness, its limits, and its impact on the resulting causal estimates. Empirically, Ivy can correctly identify the directionality of known relationships and is robust against false discovery (median effect size <= 0.025) on three real-world datasets with no causal effects, while allele scores return more biased estimates (median effect size >= 0.118).
Assessing Robustness to Noise: Low-Cost Head CT Triage
Mar 29, 2020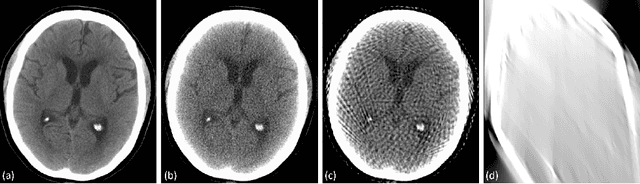

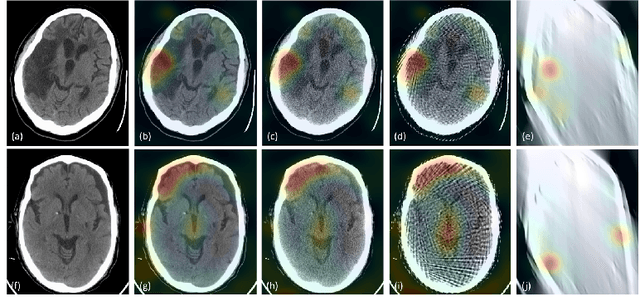
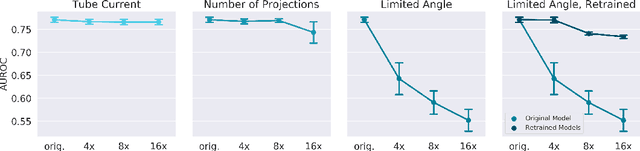
Automated medical image classification with convolutional neural networks (CNNs) has great potential to impact healthcare, particularly in resource-constrained healthcare systems where fewer trained radiologists are available. However, little is known about how well a trained CNN can perform on images with the increased noise levels, different acquisition protocols, or additional artifacts that may arise when using low-cost scanners, which can be underrepresented in datasets collected from well-funded hospitals. In this work, we investigate how a model trained to triage head computed tomography (CT) scans performs on images acquired with reduced x-ray tube current, fewer projections per gantry rotation, and limited angle scans. These changes can reduce the cost of the scanner and demands on electrical power but come at the expense of increased image noise and artifacts. We first develop a model to triage head CTs and report an area under the receiver operating characteristic curve (AUROC) of 0.77. We then show that the trained model is robust to reduced tube current and fewer projections, with the AUROC dropping only 0.65% for images acquired with a 16x reduction in tube current and 0.22% for images acquired with 8x fewer projections. Finally, for significantly degraded images acquired by a limited angle scan, we show that a model trained specifically to classify such images can overcome the technological limitations to reconstruction and maintain an AUROC within 0.09% of the original model.
Understanding the Downstream Instability of Word Embeddings
Feb 29, 2020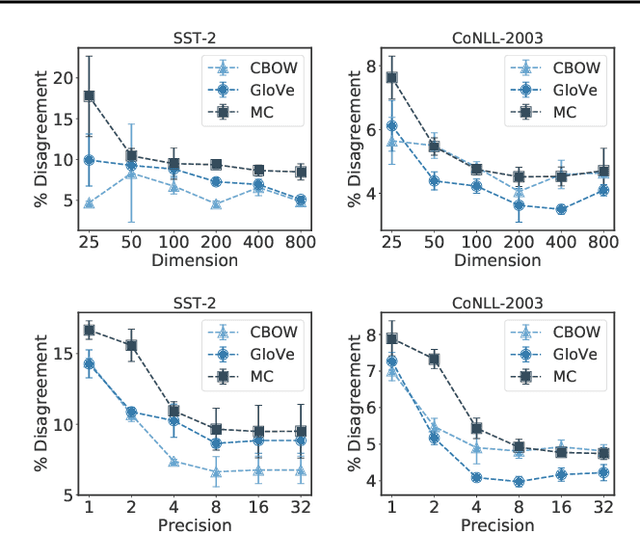

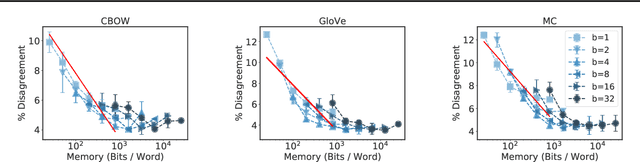
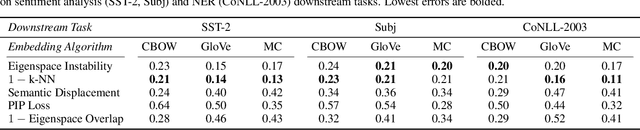
Many industrial machine learning (ML) systems require frequent retraining to keep up-to-date with constantly changing data. This retraining exacerbates a large challenge facing ML systems today: model training is unstable, i.e., small changes in training data can cause significant changes in the model's predictions. In this paper, we work on developing a deeper understanding of this instability, with a focus on how a core building block of modern natural language processing (NLP) pipelines---pre-trained word embeddings---affects the instability of downstream NLP models. We first empirically reveal a tradeoff between stability and memory: increasing the embedding memory 2x can reduce the disagreement in predictions due to small changes in training data by 5% to 37% (relative). To theoretically explain this tradeoff, we introduce a new measure of embedding instability---the eigenspace instability measure---which we prove bounds the disagreement in downstream predictions introduced by the change in word embeddings. Practically, we show that the eigenspace instability measure can be a cost-effective way to choose embedding parameters to minimize instability without training downstream models, outperforming other embedding distance measures and performing competitively with a nearest neighbor-based measure. Finally, we demonstrate that the observed stability-memory tradeoffs extend to other types of embeddings as well, including knowledge graph and contextual word embeddings.
Fast and Three-rious: Speeding Up Weak Supervision with Triplet Methods
Feb 27, 2020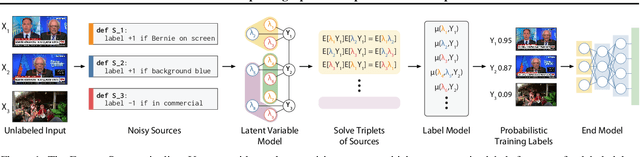
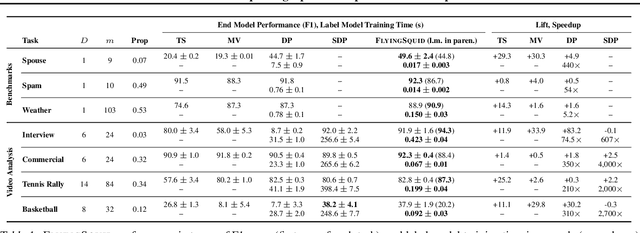

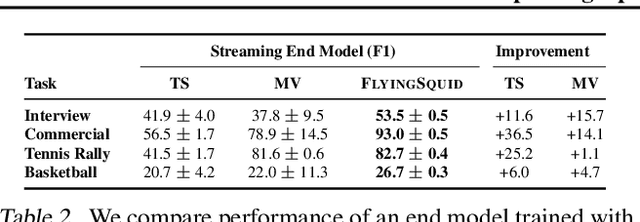
Weak supervision is a popular method for building machine learning models without relying on ground truth annotations. Instead, it generates probabilistic training labels by estimating the accuracies of multiple noisy labeling sources (e.g., heuristics, crowd workers). Existing approaches use latent variable estimation to model the noisy sources, but these methods can be computationally expensive, scaling superlinearly in the data. In this work, we show that, for a class of latent variable models highly applicable to weak supervision, we can find a closed-form solution to model parameters, obviating the need for iterative solutions like stochastic gradient descent (SGD). We use this insight to build FlyingSquid, a weak supervision framework that runs orders of magnitude faster than previous weak supervision approaches and requires fewer assumptions. In particular, we prove bounds on generalization error without assuming that the latent variable model can exactly parameterize the underlying data distribution. Empirically, we validate FlyingSquid on benchmark weak supervision datasets and find that it achieves the same or higher quality compared to previous approaches without the need to tune an SGD procedure, recovers model parameters 170 times faster on average, and enables new video analysis and online learning applications.
Hyperbolic Graph Convolutional Neural Networks
Oct 28, 2019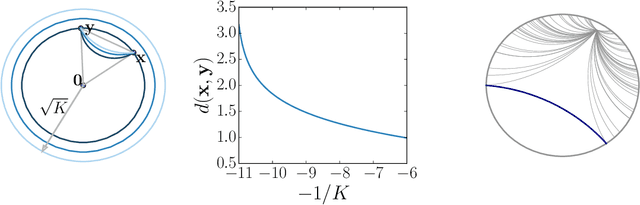
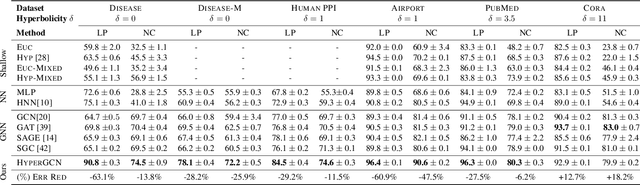
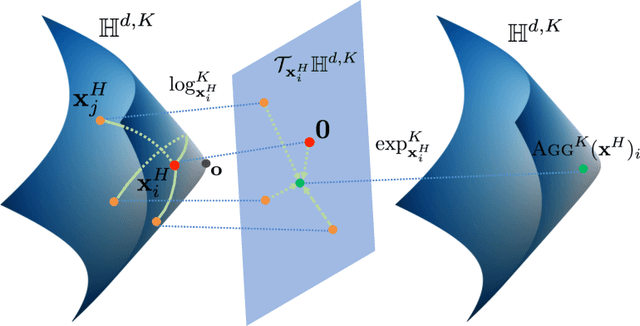
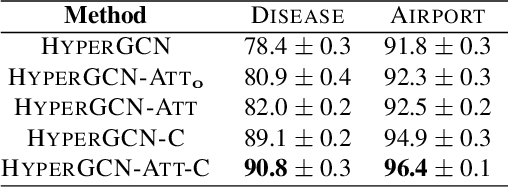
Graph convolutional neural networks (GCNs) embed nodes in a graph into Euclidean space, which has been shown to incur a large distortion when embedding real-world graphs with scale-free or hierarchical structure. Hyperbolic geometry offers an exciting alternative, as it enables embeddings with much smaller distortion. However, extending GCNs to hyperbolic geometry presents several unique challenges because it is not clear how to define neural network operations, such as feature transformation and aggregation, in hyperbolic space. Furthermore, since input features are often Euclidean, it is unclear how to transform the features into hyperbolic embeddings with the right amount of curvature. Here we propose Hyperbolic Graph Convolutional Neural Network (HGCN), the first inductive hyperbolic GCN that leverages both the expressiveness of GCNs and hyperbolic geometry to learn inductive node representations for hierarchical and scale-free graphs. We derive GCN operations in the hyperboloid model of hyperbolic space and map Euclidean input features to embeddings in hyperbolic spaces with different trainable curvature at each layer. Experiments demonstrate that HGCN learns embeddings that preserve hierarchical structure, and leads to improved performance when compared to Euclidean analogs, even with very low dimensional embeddings: compared to state-of-the-art GCNs, HGCN achieves an error reduction of up to 63.1% in ROC AUC for link prediction and of up to 47.5% in F1 score for node classification, also improving state-of-the art on the Pubmed dataset.
Multi-Resolution Weak Supervision for Sequential Data
Oct 21, 2019
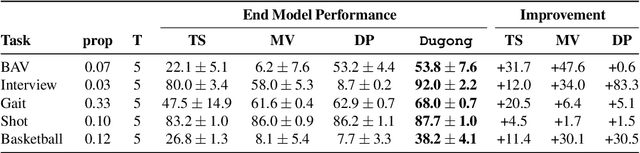
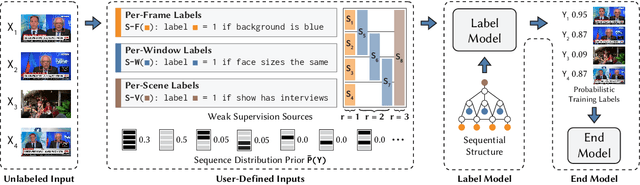

Since manually labeling training data is slow and expensive, recent industrial and scientific research efforts have turned to weaker or noisier forms of supervision sources. However, existing weak supervision approaches fail to model multi-resolution sources for sequential data, like video, that can assign labels to individual elements or collections of elements in a sequence. A key challenge in weak supervision is estimating the unknown accuracies and correlations of these sources without using labeled data. Multi-resolution sources exacerbate this challenge due to complex correlations and sample complexity that scales in the length of the sequence. We propose Dugong, the first framework to model multi-resolution weak supervision sources with complex correlations to assign probabilistic labels to training data. Theoretically, we prove that Dugong, under mild conditions, can uniquely recover the unobserved accuracy and correlation parameters and use parameter sharing to improve sample complexity. Our method assigns clinician-validated labels to population-scale biomedical video repositories, helping outperform traditional supervision by 36.8 F1 points and addressing a key use case where machine learning has been severely limited by the lack of expert labeled data. On average, Dugong improves over traditional supervision by 16.0 F1 points and existing weak supervision approaches by 24.2 F1 points across several video and sensor classification tasks.
PipeMare: Asynchronous Pipeline Parallel DNN Training
Oct 09, 2019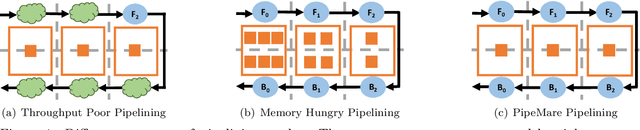

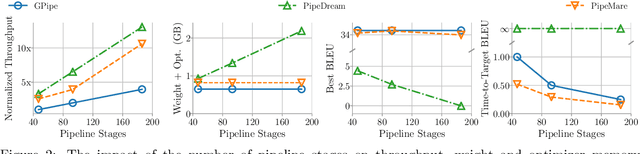
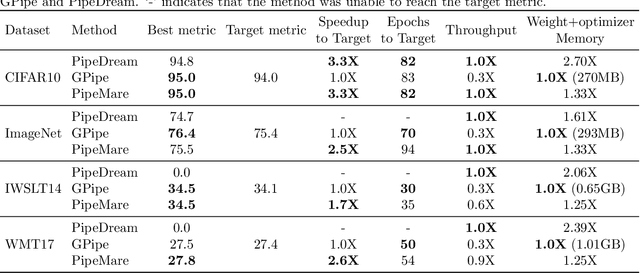
Recently there has been a flurry of interest around using pipeline parallelism while training neural networks. Pipeline parallelism enables larger models to be partitioned spatially across chips and within a chip, leading to both lower network communication and overall higher hardware utilization. Unfortunately, to preserve statistical efficiency, existing pipeline-parallelism techniques sacrifice hardware efficiency by introducing bubbles into the pipeline and/or incurring extra memory costs. In this paper, we investigate to what extent these sacrifices are necessary. Theoretically, we derive a simple but robust training method, called PipeMare, that tolerates asynchronous updates during pipeline-parallel execution. Using this, we show empirically, on a ResNet network and a Transformer network, that PipeMare can achieve final model qualities that match those of synchronous training techniques (at most 0.9% worse test accuracy and 0.3 better test BLEU score) while either using up to 2.0X less weight and optimizer memory or being up to 3.3X faster than other pipeline parallel training techniques. To the best of our knowledge we are the first to explore these techniques and fine-grained pipeline parallelism (e.g. the number of pipeline stages equals to the number of layers) during neural network training.