 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Sampling for Linear Regression Beyond the $\ell_2$ Norm
Nov 09, 2021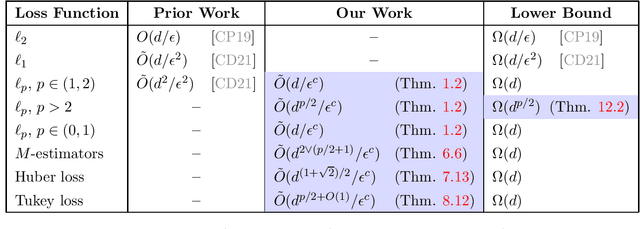
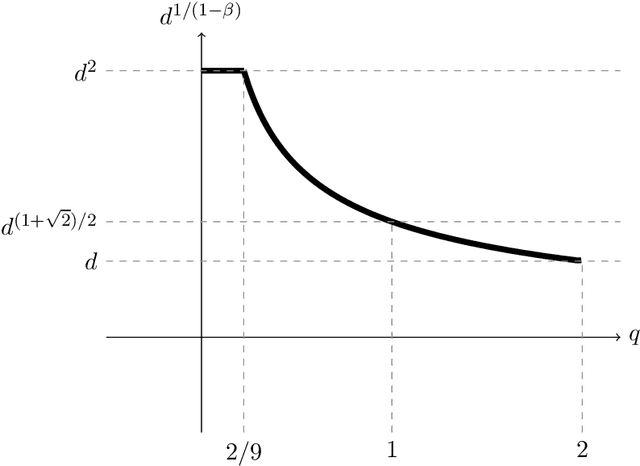
We study active sampling algorithms for linear regression, which aim to query only a small number of entries of a target vector $b\in\mathbb{R}^n$ and output a near minimizer to $\min_{x\in\mathbb{R}^d}\|Ax-b\|$, where $A\in\mathbb{R}^{n \times d}$ is a design matrix and $\|\cdot\|$ is some loss function. For $\ell_p$ norm regression for any $0<p<\infty$, we give an algorithm based on Lewis weight sampling that outputs a $(1+\epsilon)$ approximate solution using just $\tilde{O}(d^{\max(1,{p/2})}/\mathrm{poly}(\epsilon))$ queries to $b$. We show that this dependence on $d$ is optimal, up to logarithmic factors. Our result resolves a recent open question of Chen and Derezi\'{n}ski, who gave near optimal bounds for the $\ell_1$ norm, and suboptimal bounds for $\ell_p$ regression with $p\in(1,2)$. We also provide the first total sensitivity upper bound of $O(d^{\max\{1,p/2\}}\log^2 n)$ for loss functions with at most degree $p$ polynomial growth. This improves a recent result of Tukan, Maalouf, and Feldman. By combining this with our techniques for the $\ell_p$ regression result, we obtain an active regression algorithm making $\tilde O(d^{1+\max\{1,p/2\}}/\mathrm{poly}(\epsilon))$ queries, answering another open question of Chen and Derezi\'{n}ski. For the important special case of the Huber loss, we further improve our bound to an active sample complexity of $\tilde O(d^{(1+\sqrt2)/2}/\epsilon^c)$ and a non-active sample complexity of $\tilde O(d^{4-2\sqrt 2}/\epsilon^c)$, improving a previous $d^4$ bound for Huber regression due to Clarkson and Woodruff. Our sensitivity bounds have further implications, improving a variety of previous results using sensitivity sampling, including Orlicz norm subspace embeddings and robust subspace approximation. Finally, our active sampling results give the first sublinear time algorithms for Kronecker product regression under every $\ell_p$ norm.
Correlation Sketches for Approximate Join-Correlation Queries
Apr 07, 2021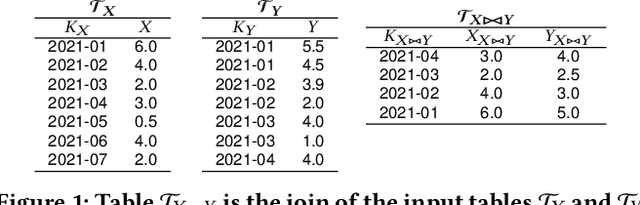


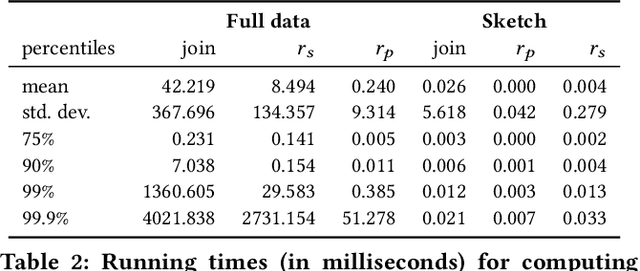
The increasing availability of structured datasets, from Web tables and open-data portals to enterprise data, opens up opportunities~to enrich analytics and improve machine learning models through relational data augmentation. In this paper, we introduce a new class of data augmentation queries: join-correlation queries. Given a column $Q$ and a join column $K_Q$ from a query table $\mathcal{T}_Q$, retrieve tables $\mathcal{T}_X$ in a dataset collection such that $\mathcal{T}_X$ is joinable with $\mathcal{T}_Q$ on $K_Q$ and there is a column $C \in \mathcal{T}_X$ such that $Q$ is correlated with $C$. A na\"ive approach to evaluate these queries, which first finds joinable tables and then explicitly joins and computes correlations between $Q$ and all columns of the discovered tables, is prohibitively expensive. To efficiently support correlated column discovery, we 1) propose a sketching method that enables the construction of an index for a large number of tables and that provides accurate estimates for join-correlation queries, and 2) explore different scoring strategies that effectively rank the query results based on how well the columns are correlated with the query. We carry out a detailed experimental evaluation, using both synthetic and real data, which shows that our sketches attain high accuracy and the scoring strategies lead to high-quality rankings.
Hutch++: Optimal Stochastic Trace Estimation
Nov 12, 2020
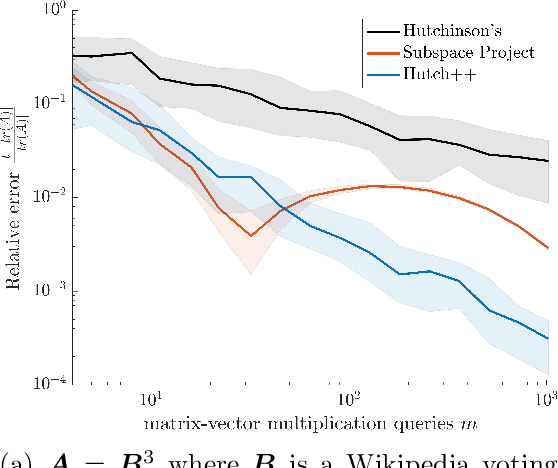
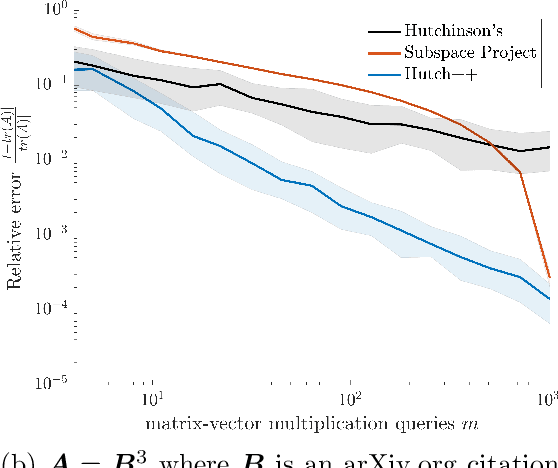
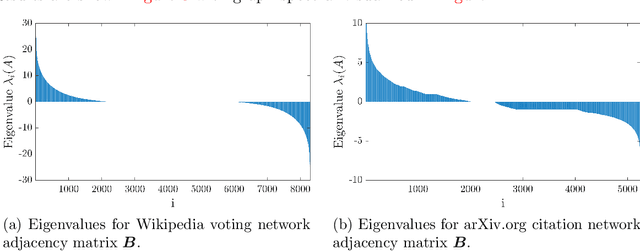
We study the problem of estimating the trace of a matrix $A$ that can only be accessed through matrix-vector multiplication. We introduce a new randomized algorithm, Hutch++, which computes a $(1 \pm \epsilon)$ approximation to $tr(A)$ for any positive semidefinite (PSD) $A$ using just $O(1/\epsilon)$ matrix-vector products. This improves on the ubiquitous Hutchinson's estimator, which requires $O(1/\epsilon^2)$ matrix-vector products. Our approach is based on a simple technique for reducing the variance of Hutchinson's estimator using a low-rank approximation step, and is easy to implement and analyze. Moreover, we prove that, up to a logarithmic factor, the complexity of Hutch++ is optimal amongst all matrix-vector query algorithms, even when queries can be chosen adaptively. We show that it significantly outperforms Hutchinson's method in experiments. While our theory requires $A$ to be positive semidefinite, empirical gains extend to applications involving non-PSD matrices, such as triangle estimation in networks.
Graph Learning for Inverse Landscape Genetics
Jun 30, 2020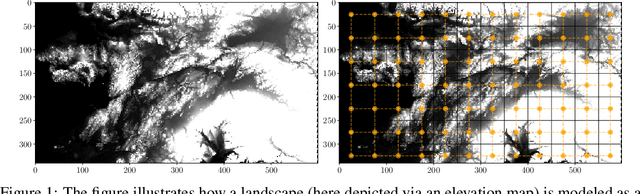
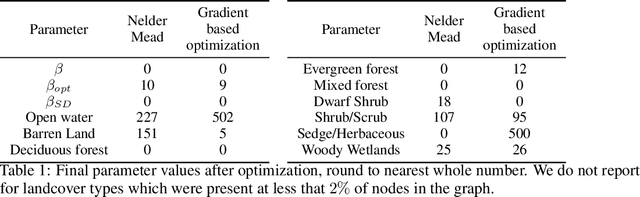
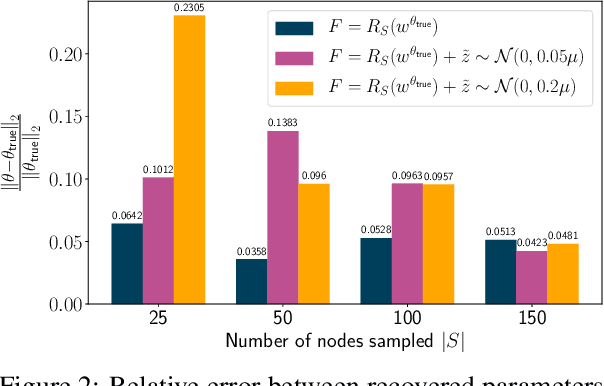
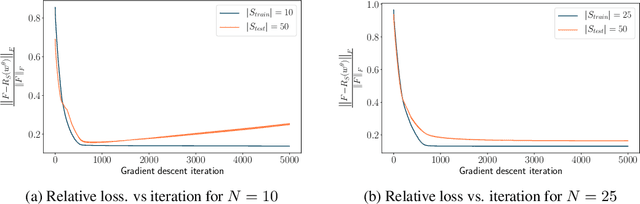
The problem of inferring unknown graph edges from numerical data at a graph's nodes appears in many forms across machine learning. We study a version of this problem that arises in the field of landscape genetics, where genetic similarity between populations of organisms living in a heterogeneous landscape is explained by a weighted graph that encodes the ease of dispersal through that landscape. Our main contribution is an efficient algorithm for inverse landscape genetics, which is the task of inferring this graph from measurements of genetic similarity at different locations (graph nodes). We reduced the problem to that of inferring graph edges from noisy measurements of effective resistances between graph nodes, which have been observed to correlate well with genetic similarity. Building on Hoskins et. al., we develop an efficient first-order optimization method for solving this problem. Despite its non-convex nature, extensive experiments on synthetic and real genetic data establish that our method provides fast and reliable convergence, significantly outperforming existing heuristics used in the field.
The Statistical Cost of Robust Kernel Hyperparameter Tuning
Jun 14, 2020This paper studies the statistical complexity of kernel hyperparameter tuning in the setting of active regression under adversarial noise. We consider the problem of finding the best interpolant from a class of kernels with unknown hyperparameters, assuming only that the noise is square-integrable. We provide finite-sample guarantees for the problem, characterizing how increasing the complexity of the kernel class increases the complexity of learning kernel hyperparameters. For common kernel classes (e.g. squared-exponential kernels with unknown lengthscale), our results show that hyperparameter optimization increases sample complexity by just a logarithmic factor, in comparison to the setting where optimal parameters are known in advance. Our result is based on a subsampling guarantee for linear regression under multiple design matrices, combined with an {\epsilon}-net argument for discretizing kernel parameterizations.
Fourier Sparse Leverage Scores and Approximate Kernel Learning
Jun 12, 2020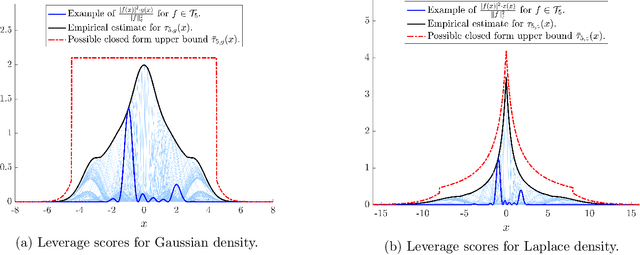
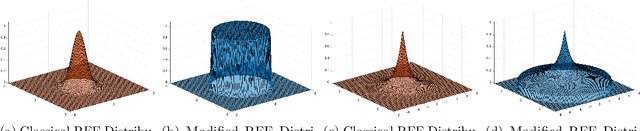
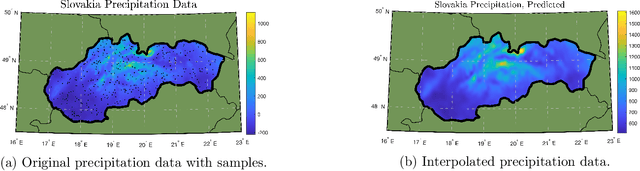
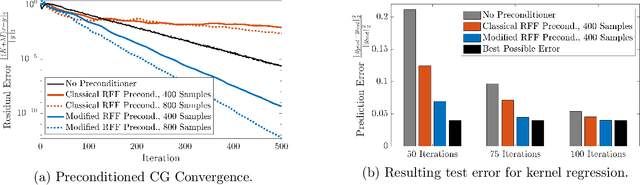
We prove new explicit upper bounds on the leverage scores of Fourier sparse functions under both the Gaussian and Laplace measures. In particular, we study $s$-sparse functions of the form $f(x) = \sum_{j=1}^s a_j e^{i \lambda_j x}$ for coefficients $a_j \in \mathbb{C}$ and frequencies $\lambda_j \in \mathbb{R}$. Bounding Fourier sparse leverage scores under various measures is of pure mathematical interest in approximation theory, and our work extends existing results for the uniform measure [Erd17,CP19a]. Practically, our bounds are motivated by two important applications in machine learning: 1. Kernel Approximation. They yield a new random Fourier features algorithm for approximating Gaussian and Cauchy (rational quadratic) kernel matrices. For low-dimensional data, our method uses a near optimal number of features, and its runtime is polynomial in the $statistical\ dimension$ of the approximated kernel matrix. It is the first "oblivious sketching method" with this property for any kernel besides the polynomial kernel, resolving an open question of [AKM+17,AKK+20b]. 2. Active Learning. They can be used as non-uniform sampling distributions for robust active learning when data follows a Gaussian or Laplace distribution. Using the framework of [AKM+19], we provide essentially optimal results for bandlimited and multiband interpolation, and Gaussian process regression. These results generalize existing work that only applies to uniformly distributed data.
Projection-Cost-Preserving Sketches: Proof Strategies and Constructions
Apr 17, 2020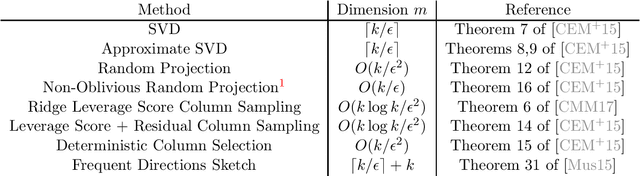
In this note we illustrate how common matrix approximation methods, such as random projection and random sampling, yield projection-cost-preserving sketches, as introduced in [FSS13, CEM+15]. A projection-cost-preserving sketch is a matrix approximation which, for a given parameter $k$, approximately preserves the distance of the target matrix to all $k$-dimensional subspaces. Such sketches have applications to scalable algorithms for linear algebra, data science, and machine learning. Our goal is to simplify the presentation of proof techniques introduced in [CEM+15] and [CMM17] so that they can serve as a guide for future work. We also refer the reader to [CYD19], which gives a similar simplified exposition of the proof covered in Section 2.
Sample Efficient Toeplitz Covariance Estimation
Jun 06, 2019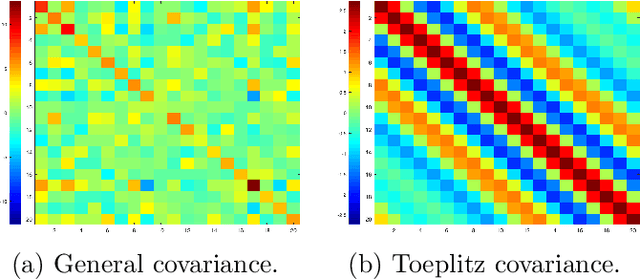
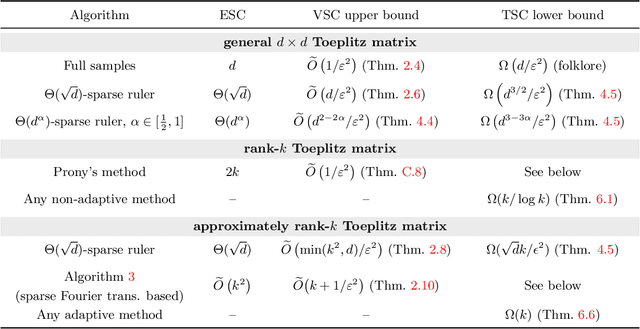
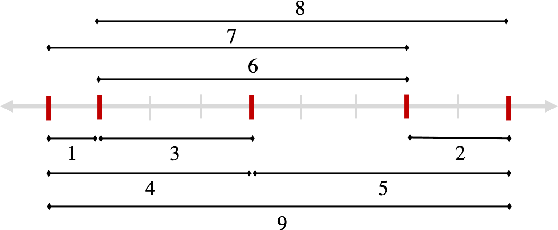
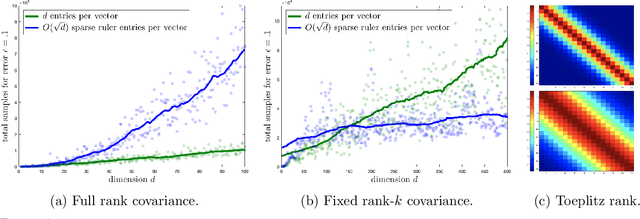
We study the sample complexity of estimating the covariance matrix $T$ of a distribution $\mathcal{D}$ over $d$-dimensional vectors, under the assumption that $T$ is Toeplitz. This assumption arises in many signal processing problems, where the covariance between any two measurements only depends on the time or distance between those measurements. We are interested in estimation strategies that may choose to view only a subset of entries in each vector sample $x \sim \mathcal{D}$, which often equates to reducing hardware and communication requirements in applications ranging from wireless signal processing to advanced imaging. Our goal is to minimize both 1) the number of vector samples drawn from $\mathcal{D}$ and 2) the number of entries accessed in each sample. We provide some of the first non-asymptotic bounds on these sample complexity measures that exploit $T$'s Toeplitz structure, and by doing so, significantly improve on results for generic covariance matrices. Our bounds follow from a novel analysis of classical and widely used estimation algorithms (along with some new variants), including methods based on selecting entries from each vector sample according to a so-called sparse ruler. In many cases, we pair our upper bounds with matching or nearly matching lower bounds. In addition to results that hold for any Toeplitz $T$, we further study the important setting when $T$ is close to low-rank, which is often the case in practice. We show that methods based on sparse rulers perform even better in this setting, with sample complexity scaling sublinearly in $d$. Motivated by this finding, we develop a new covariance estimation strategy that further improves on all existing methods in the low-rank case: when $T$ is rank-$k$ or nearly rank-$k$, it achieves sample complexity depending polynomially on $k$ and only logarithmically on $d$.
Low-Rank Approximation from Communication Complexity
Apr 22, 2019
In low-rank approximation with missing entries, given $A\in \mathbb{R}^{n\times n}$ and binary $W \in \{0,1\}^{n\times n}$, the goal is to find a rank-$k$ matrix $L$ for which: $$cost(L)=\sum_{i=1}^{n} \sum_{j=1}^{n}W_{i,j}\cdot (A_{i,j} - L_{i,j})^2\le OPT+\epsilon \|A\|_F^2,$$ where $OPT=\min_{rank-k\ \hat{L}}cost(\hat L)$. This problem is also known as matrix completion and, depending on the choice of $W$, captures low-rank plus diagonal decomposition, robust PCA, low-rank recovery from monotone missing data, and a number of other important problems. Many of these problems are NP-hard, and while algorithms with provable guarantees are known in some cases, they either 1) run in time $n^{\Omega(k^2/\epsilon)}$, or 2) make strong assumptions, e.g., that $A$ is incoherent or that $W$ is random. In this work, we consider $bicriteria\ algorithms$, which output $L$ with rank $k' > k$. We prove that a common heuristic, which simply sets $A$ to $0$ where $W$ is $0$, and then computes a standard low-rank approximation, achieves the above approximation bound with rank $k'$ depending on the $communication\ complexity$ of $W$. Namely, interpreting $W$ as the communication matrix of a Boolean function $f(x,y)$ with $x,y\in \{0,1\}^{\log n}$, it suffices to set $k'=O(k\cdot 2^{R^{1-sided}_{\epsilon}(f)})$, where $R^{1-sided}_{\epsilon}(f)$ is the randomized communication complexity of $f$ with $1$-sided error probability $\epsilon$. For many problems, this yields bicriteria algorithms with $k'=k\cdot poly((\log n)/\epsilon)$. We prove a similar bound using the randomized communication complexity with $2$-sided error. Further, we show that different models of communication yield algorithms for natural variants of the problem. E.g., multi-player communication complexity connects to tensor decomposition and non-deterministic communication complexity to Boolean low-rank factorization.
A Universal Sampling Method for Reconstructing Signals with Simple Fourier Transforms
Dec 20, 2018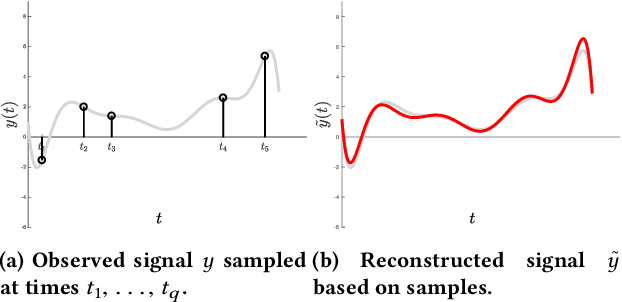

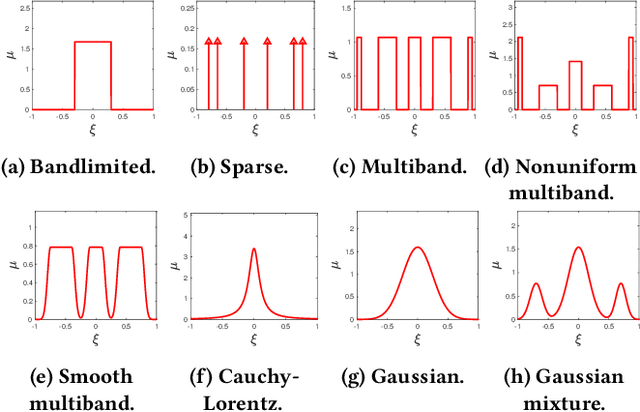
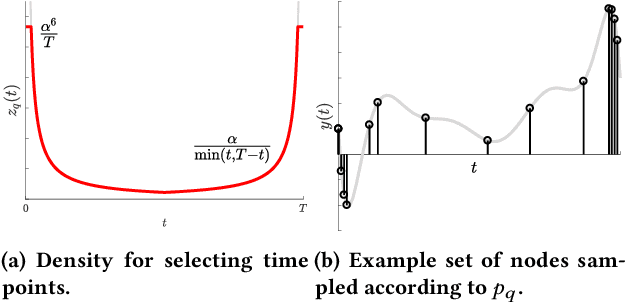
Reconstructing continuous signals from a small number of discrete samples is a fundamental problem across science and engineering. In practice, we are often interested in signals with 'simple' Fourier structure, such as bandlimited, multiband, and Fourier sparse signals. More broadly, any prior knowledge about a signal's Fourier power spectrum can constrain its complexity. Intuitively, signals with more highly constrained Fourier structure require fewer samples to reconstruct. We formalize this intuition by showing that, roughly, a continuous signal from a given class can be approximately reconstructed using a number of samples proportional to the *statistical dimension* of the allowed power spectrum of that class. Further, in nearly all settings, this natural measure tightly characterizes the sample complexity of signal reconstruction. Surprisingly, we also show that, up to logarithmic factors, a universal non-uniform sampling strategy can achieve this optimal complexity for *any class of signals*. We present a simple and efficient algorithm for recovering a signal from the samples taken. For bandlimited and sparse signals, our method matches the state-of-the-art. At the same time, it gives the first computationally and sample efficient solution to a broad range of problems, including multiband signal reconstruction and kriging and Gaussian process regression tasks in one dimension. Our work is based on a novel connection between randomized linear algebra and signal reconstruction with constrained Fourier structure. We extend tools based on statistical leverage score sampling and column-based matrix reconstruction to the approximation of continuous linear operators that arise in signal reconstruction. We believe that these extensions are of independent interest and serve as a foundation for tackling a broad range of continuous time problems using randomized methods.