 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Robot Deep Reinforcement Learning with Macro-Actions
Sep 19, 2019
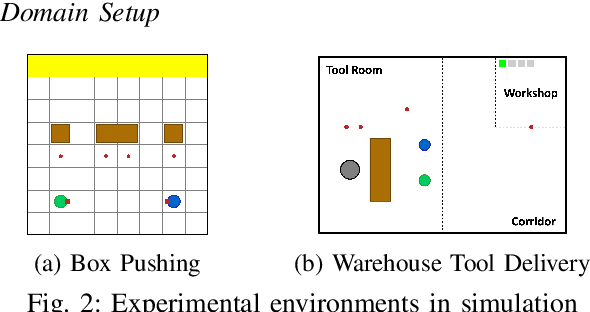
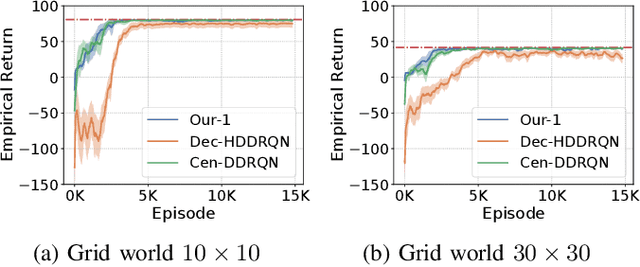
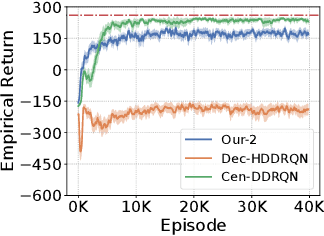
In many real-world multi-robot tasks, high-quality solutions often require a team of robots to perform asynchronous actions under decentralized control. Multi-agent reinforcement learning methods have difficulty learning decentralized policies because the environment appearing to be non-stationary due to other agents also learning at the same time. In this paper, we address this challenge by proposing a macro-action-based decentralized multi-agent double deep recurrent Q-net (MacDec-MADDRQN) which creates a new double Q-updating rule to train each decentralized Q-net using a centralized Q-net for action selection. A generalized version of MacDec-MADDRQN with two separate training environments, called Parallel-MacDec-MADDRQN, is also presented to cope with the uncertainty in adopting either centralized or decentralized exploration. The advantages and the practical nature of our methods are demonstrated by achieving near-centralized results in simulation experiments and permitting real robots to accomplish a warehouse tool delivery task in an efficient way.
Decentralized Likelihood Implicit Quantile Network
Jan 13, 2019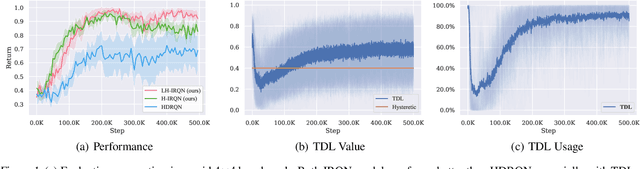
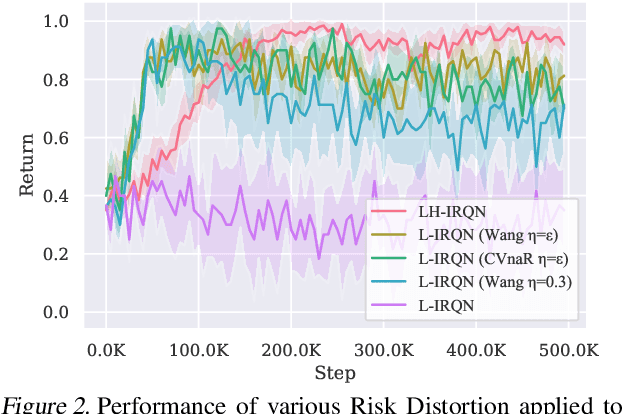
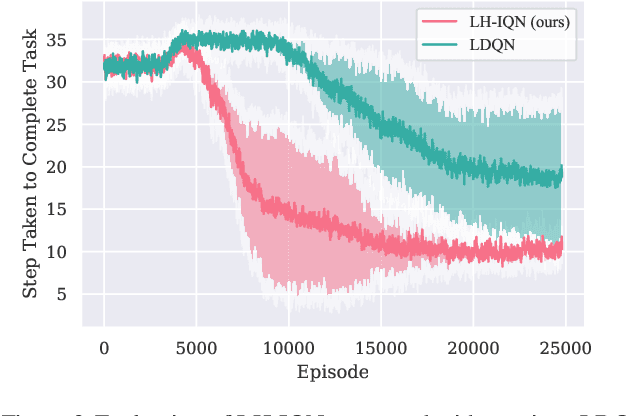
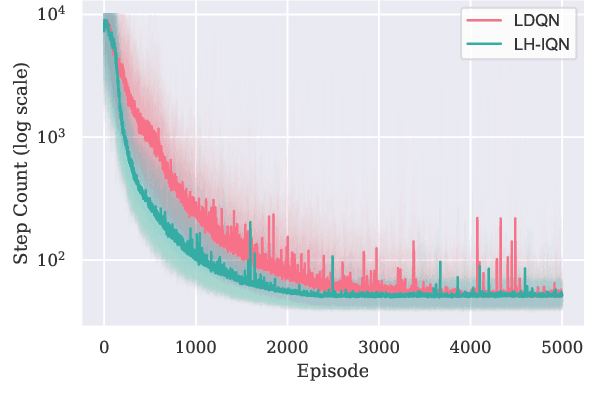
Recent successes of value-based multi-agent deep reinforcement learning employ optimism by limiting underestimation updates of value function estimator, through carefully controlled learning rate (Omidshafiei et al., 2017) or reduced update probability (Palmer et al., 2018). To achieve full cooperation when learning independently, an agent must estimate the state values contingent on having optimal teammates; therefore, value overestimation is frequency injected to counteract negative effects caused by unobservable teammate sub-optimal policies and explorations. Aiming to solve this issue through automatic scheduling, this paper introduces a decentralized quantile estimator, which we found empirically to be more stable, sample efficient and more likely to converge to the joint optimal policy.
Bayesian Reinforcement Learning in Factored POMDPs
Nov 14, 2018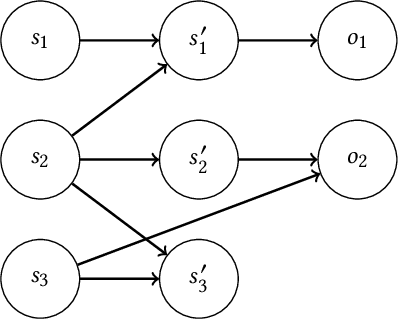

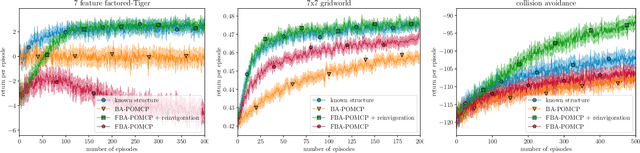

Bayesian approaches provide a principled solution to the exploration-exploitation trade-off in Reinforcement Learning. Typical approaches, however, either assume a fully observable environment or scale poorly. This work introduces the Factored Bayes-Adaptive POMDP model, a framework that is able to exploit the underlying structure while learning the dynamics in partially observable systems. We also present a belief tracking method to approximate the joint posterior over state and model variables, and an adaptation of the Monte-Carlo Tree Search solution method, which together are capable of solving the underlying problem near-optimally. Our method is able to learn efficiently given a known factorization or also learn the factorization and the model parameters at the same time. We demonstrate that this approach is able to outperform current methods and tackle problems that were previously infeasible.
Efficient Eligibility Traces for Deep Reinforcement Learning
Oct 23, 2018



Eligibility traces are an effective technique to accelerate reinforcement learning by smoothly assigning credit to recently visited states. However, their online implementation is incompatible with modern deep reinforcement learning algorithms, which rely heavily on i.i.d. training data and offline learning. We utilize an efficient, recursive method for computing {\lambda}-returns offline that can provide the benefits of eligibility traces to any value-estimation or actor-critic method. We demonstrate how our method can be combined with DQN, DRQN, and A3C to greatly enhance the learning speed of these algorithms when playing Atari 2600 games, even under partial observability. Our results indicate several-fold improvements to sample efficiency on Seaquest and Q*bert. We expect similar results for other algorithms and domains not considered here, including those with continuous actions.
Learning to Teach in Cooperative Multiagent Reinforcement Learning
Aug 31, 2018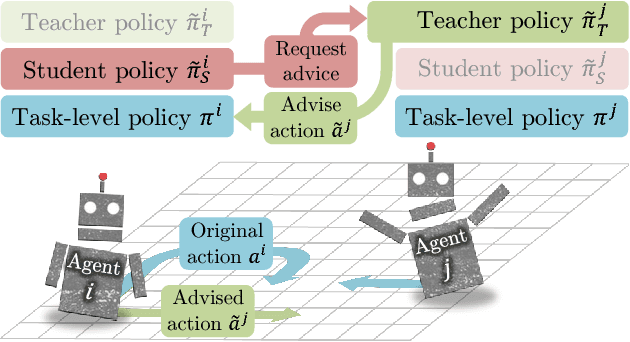

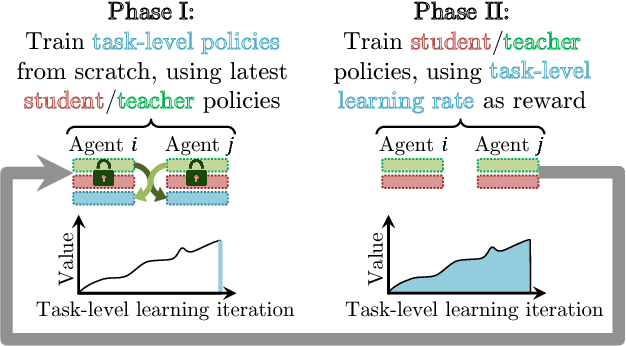
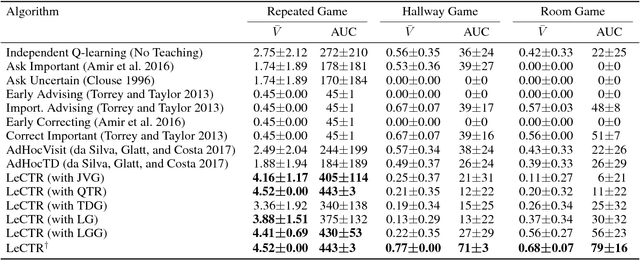
Collective human knowledge has clearly benefited from the fact that innovations by individuals are taught to others through communication. Similar to human social groups, agents in distributed learning systems would likely benefit from communication to share knowledge and teach skills. The problem of teaching to improve agent learning has been investigated by prior works, but these approaches make assumptions that prevent application of teaching to general multiagent problems, or require domain expertise for problems they can apply to. This learning to teach problem has inherent complexities related to measuring long-term impacts of teaching that compound the standard multiagent coordination challenges. In contrast to existing works, this paper presents the first general framework and algorithm for intelligent agents to learn to teach in a multiagent environment. Our algorithm, Learning to Coordinate and Teach Reinforcement (LeCTR), addresses peer-to-peer teaching in cooperative multiagent reinforcement learning. Each agent in our approach learns both when and what to advise, then uses the received advice to improve local learning. Importantly, these roles are not fixed; these agents learn to assume the role of student and/or teacher at the appropriate moments, requesting and providing advice in order to improve teamwide performance and learning. Empirical comparisons against state-of-the-art teaching methods show that our teaching agents not only learn significantly faster, but also learn to coordinate in tasks where existing methods fail.
Learning in POMDPs with Monte Carlo Tree Search
Jun 14, 2018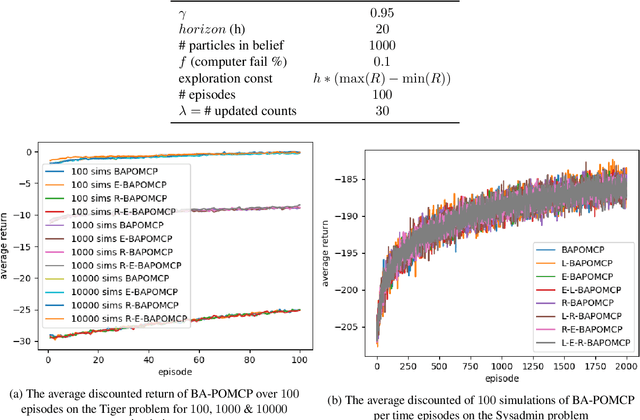
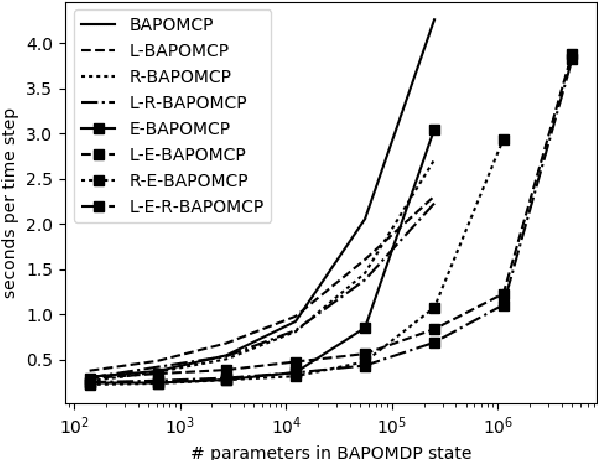
The POMDP is a powerful framework for reasoning under outcome and information uncertainty, but constructing an accurate POMDP model is difficult. Bayes-Adaptive Partially Observable Markov Decision Processes (BA-POMDPs) extend POMDPs to allow the model to be learned during execution. BA-POMDPs are a Bayesian RL approach that, in principle, allows for an optimal trade-off between exploitation and exploration. Unfortunately, BA-POMDPs are currently impractical to solve for any non-trivial domain. In this paper, we extend the Monte-Carlo Tree Search method POMCP to BA-POMDPs and show that the resulting method, which we call BA-POMCP, is able to tackle problems that previous solution methods have been unable to solve. Additionally, we introduce several techniques that exploit the BA-POMDP structure to improve the efficiency of BA-POMCP along with proof of their convergence.
Near-Optimal Adversarial Policy Switching for Decentralized Asynchronous Multi-Agent Systems
Oct 17, 2017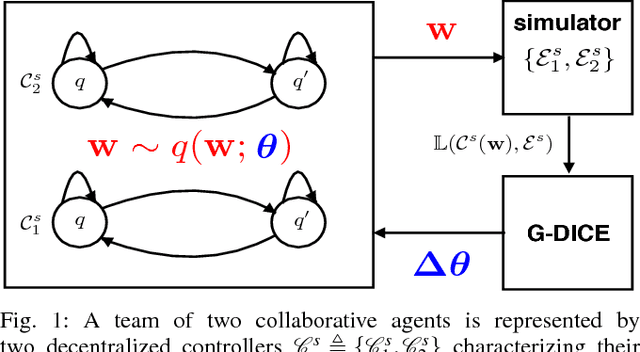
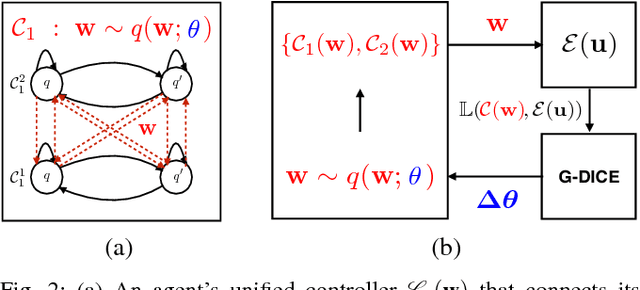
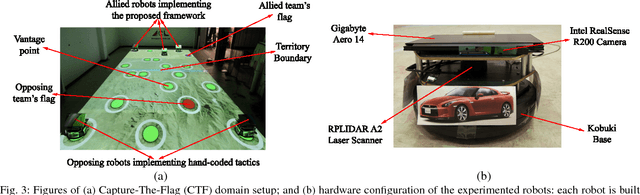
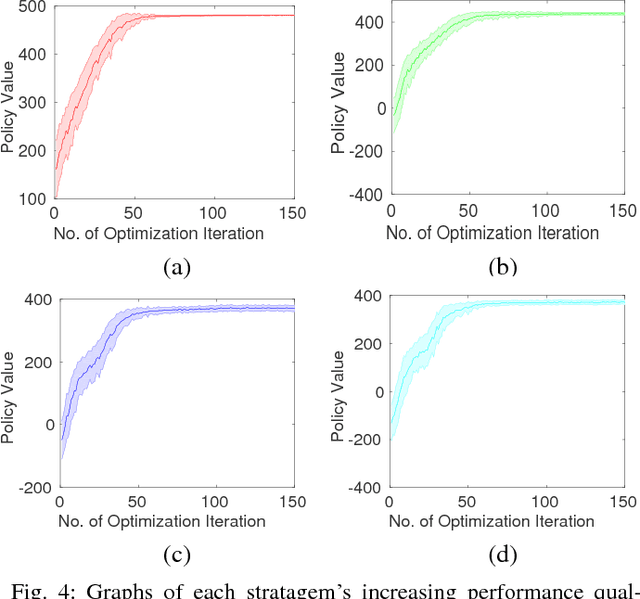
A key challenge in multi-robot and multi-agent systems is generating solutions that are robust to other self-interested or even adversarial parties who actively try to prevent the agents from achieving their goals. The practicality of existing works addressing this challenge is limited to only small-scale synchronous decision-making scenarios or a single agent planning its best response against a single adversary with fixed, procedurally characterized strategies. In contrast this paper considers a more realistic class of problems where a team of asynchronous agents with limited observation and communication capabilities need to compete against multiple strategic adversaries with changing strategies. This problem necessitates agents that can coordinate to detect changes in adversary strategies and plan the best response accordingly. Our approach first optimizes a set of stratagems that represent these best responses. These optimized stratagems are then integrated into a unified policy that can detect and respond when the adversaries change their strategies. The near-optimality of the proposed framework is established theoretically as well as demonstrated empirically in simulation and hardware.
Learning for Multi-robot Cooperation in Partially Observable Stochastic Environments with Macro-actions
Aug 18, 2017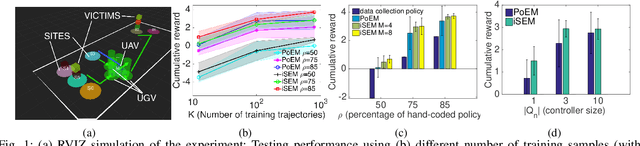



This paper presents a data-driven approach for multi-robot coordination in partially-observable domains based on Decentralized Partially Observable Markov Decision Processes (Dec-POMDPs) and macro-actions (MAs). Dec-POMDPs provide a general framework for cooperative sequential decision making under uncertainty and MAs allow temporally extended and asynchronous action execution. To date, most methods assume the underlying Dec-POMDP model is known a priori or a full simulator is available during planning time. Previous methods which aim to address these issues suffer from local optimality and sensitivity to initial conditions. Additionally, few hardware demonstrations involving a large team of heterogeneous robots and with long planning horizons exist. This work addresses these gaps by proposing an iterative sampling based Expectation-Maximization algorithm (iSEM) to learn polices using only trajectory data containing observations, MAs, and rewards. Our experiments show the algorithm is able to achieve better solution quality than the state-of-the-art learning-based methods. We implement two variants of multi-robot Search and Rescue (SAR) domains (with and without obstacles) on hardware to demonstrate the learned policies can effectively control a team of distributed robots to cooperate in a partially observable stochastic environment.
Deep Decentralized Multi-task Multi-Agent Reinforcement Learning under Partial Observability
Jul 13, 2017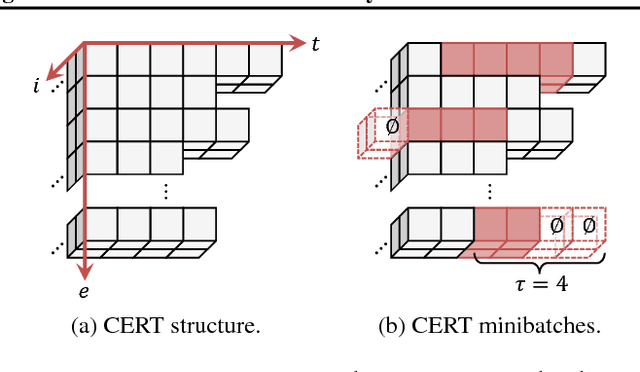
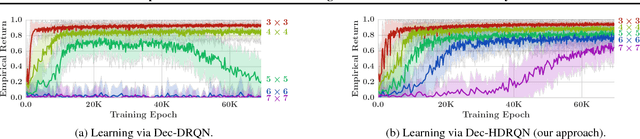
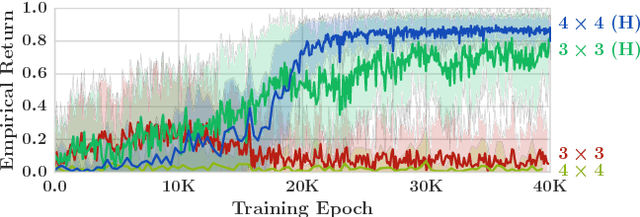
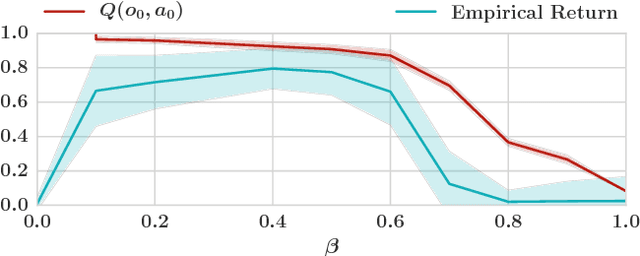
Many real-world tasks involve multiple agents with partial observability and limited communication. Learning is challenging in these settings due to local viewpoints of agents, which perceive the world as non-stationary due to concurrently-exploring teammates. Approaches that learn specialized policies for individual tasks face problems when applied to the real world: not only do agents have to learn and store distinct policies for each task, but in practice identities of tasks are often non-observable, making these approaches inapplicable. This paper formalizes and addresses the problem of multi-task multi-agent reinforcement learning under partial observability. We introduce a decentralized single-task learning approach that is robust to concurrent interactions of teammates, and present an approach for distilling single-task policies into a unified policy that performs well across multiple related tasks, without explicit provision of task identity.
* Accepted to ICML 2017
Scalable Accelerated Decentralized Multi-Robot Policy Search in Continuous Observation Spaces
Mar 16, 2017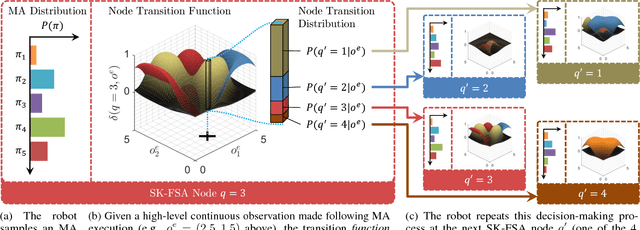
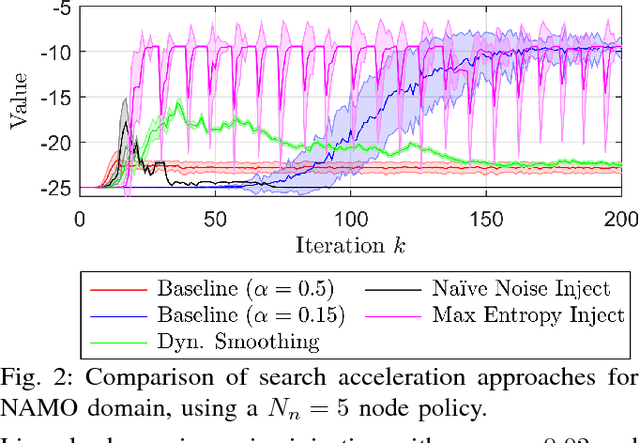
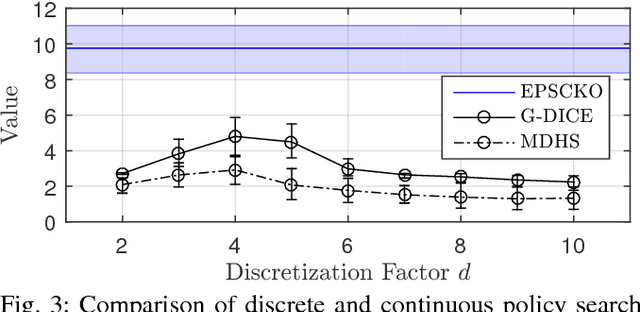
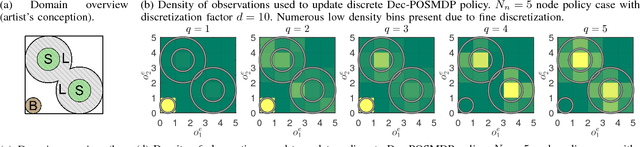
This paper presents the first ever approach for solving \emph{continuous-observation} Decentralized Partially Observable Markov Decision Processes (Dec-POMDPs) and their semi-Markovian counterparts, Dec-POSMDPs. This contribution is especially important in robotics, where a vast number of sensors provide continuous observation data. A continuous-observation policy representation is introduced using Stochastic Kernel-based Finite State Automata (SK-FSAs). An SK-FSA search algorithm titled Entropy-based Policy Search using Continuous Kernel Observations (EPSCKO) is introduced and applied to the first ever continuous-observation Dec-POMDP/Dec-POSMDP domain, where it significantly outperforms state-of-the-art discrete approaches. This methodology is equally applicable to Dec-POMDPs and Dec-POSMDPs, though the empirical analysis presented focuses on Dec-POSMDPs due to their higher scalability. To improve convergence, an entropy injection policy search acceleration approach for both continuous and discrete observation cases is also developed and shown to improve convergence rates without degrading policy quality.