 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMacro-Action-Based Deep Multi-Agent Reinforcement Learning
Apr 18, 2020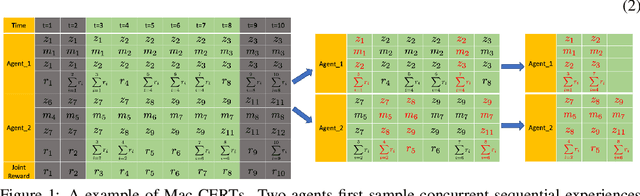
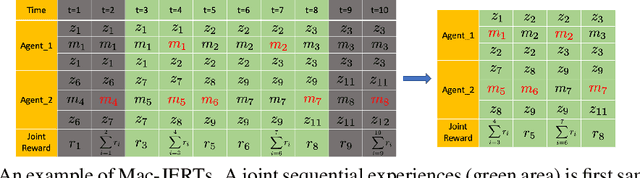
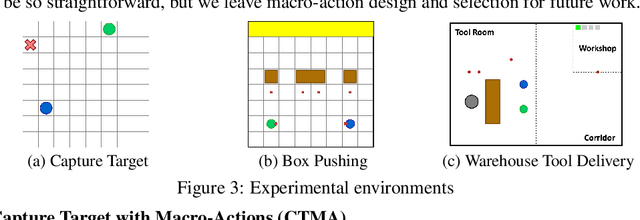
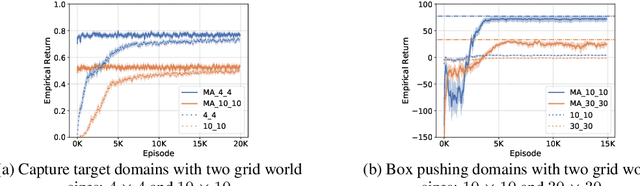
In real-world multi-robot systems, performing high-quality, collaborative behaviors requires robots to asynchronously reason about high-level action selection at varying time durations. Macro-Action Decentralized Partially Observable Markov Decision Processes (MacDec-POMDPs) provide a general framework for asynchronous decision making under uncertainty in fully cooperative multi-agent tasks. However, multi-agent deep reinforcement learning methods have only been developed for (synchronous) primitive-action problems. This paper proposes two Deep Q-Network (DQN) based methods for learning decentralized and centralized macro-action-value functions with novel macro-action trajectory replay buffers introduced for each case. Evaluations on benchmark problems and a larger domain demonstrate the advantage of learning with macro-actions over primitive-actions and the scalability of our approaches.
Multi-Robot Deep Reinforcement Learning with Macro-Actions
Sep 19, 2019
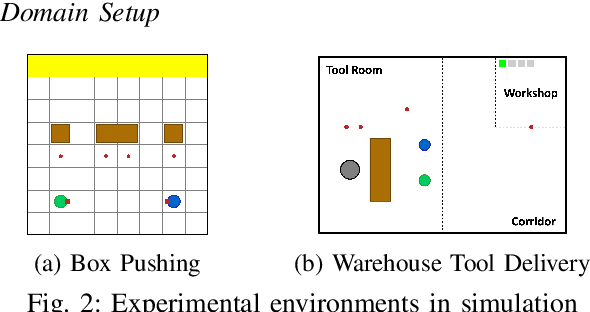
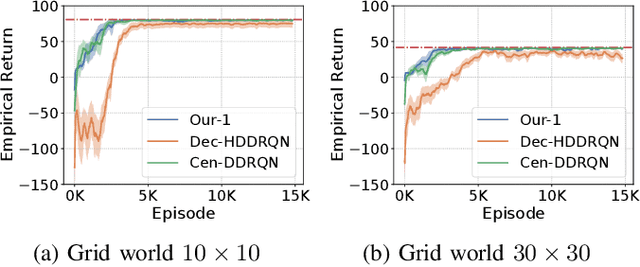
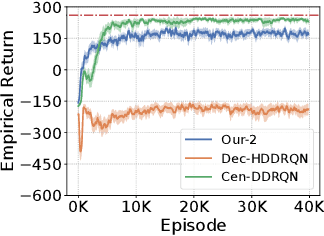
In many real-world multi-robot tasks, high-quality solutions often require a team of robots to perform asynchronous actions under decentralized control. Multi-agent reinforcement learning methods have difficulty learning decentralized policies because the environment appearing to be non-stationary due to other agents also learning at the same time. In this paper, we address this challenge by proposing a macro-action-based decentralized multi-agent double deep recurrent Q-net (MacDec-MADDRQN) which creates a new double Q-updating rule to train each decentralized Q-net using a centralized Q-net for action selection. A generalized version of MacDec-MADDRQN with two separate training environments, called Parallel-MacDec-MADDRQN, is also presented to cope with the uncertainty in adopting either centralized or decentralized exploration. The advantages and the practical nature of our methods are demonstrated by achieving near-centralized results in simulation experiments and permitting real robots to accomplish a warehouse tool delivery task in an efficient way.