 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Fingerprints for LLM Generation Comparison
May 07, 2026Large language model (LLM) outputs arise from complex interactions among prompts, system instructions, model parameters, and architecture. We refer to specific configurations of these factors as generation conditions, each of which can bias outputs in various ways. Understanding how different generation conditions shape model behaviors is essential for tasks such as prompt design and model evaluation, yet it remains challenging due to the stochastic and open-ended nature of text generation. We present an approach to visually compare LLM outputs across generation conditions by modeling responses as collections of linguistic choices, including content, expression, and structure. We extract these choices using natural language processing pipelines and represent their distributions across repeated samples. We then visualize these distributions as visual fingerprints, enabling direct, distribution-level comparison of condition-specific tendencies. Through four usage scenarios, we demonstrate how visual fingerprints reveal consistent patterns in LLM behavior that are difficult to observe through individual responses or aggregate metrics.
GFlowState: Visualizing the Training of Generative Flow Networks Beyond the Reward
Apr 23, 2026We present GFlowState, a visual analytics system designed to illuminate the training process of Generative Flow Networks (GFlowNets or GFNs). GFlowNets are a probabilistic framework for generating samples proportionally to a reward function. While GFlowNets have proved to be powerful tools in applications such as molecule and material discovery, their training dynamics remain difficult to interpret. Standard machine learning tools allow metric tracking but do not reveal how models explore the sample space, construct sample trajectories, or shift sampling probabilities during training. Our solution, GFlowState, allows users to analyze sampling trajectories, compare the sample space relative to reference datasets, and analyze the training dynamics. To this end, we introduce multiple views, including a chart of candidate rankings, a state projection, a node-link diagram of the trajectory network, and a transition heatmap. These visualizations enable GFlowNet developers and users to investigate sampling behavior and policy evolution, and to identify underexplored regions and sources of training failure. Case studies demonstrate how the system supports debugging and assessing the quality of GFlowNets across application domains. By making the structural dynamics of GFlowNets observable, our work enhances their interpretability and can accelerate GFlowNet development in practice.
Catalyst GFlowNet for electrocatalyst design: A hydrogen evolution reaction case study
Oct 02, 2025Efficient and inexpensive energy storage is essential for accelerating the adoption of renewable energy and ensuring a stable supply, despite fluctuations in sources such as wind and solar. Electrocatalysts play a key role in hydrogen energy storage (HES), allowing the energy to be stored as hydrogen. However, the development of affordable and high-performance catalysts for this process remains a significant challenge. We introduce Catalyst GFlowNet, a generative model that leverages machine learning-based predictors of formation and adsorption energy to design crystal surfaces that act as efficient catalysts. We demonstrate the performance of the model through a proof-of-concept application to the hydrogen evolution reaction, a key reaction in HES, for which we successfully identified platinum as the most efficient known catalyst. In future work, we aim to extend this approach to the oxygen evolution reaction, where current optimal catalysts are expensive metal oxides, and open the search space to discover new materials. This generative modeling framework offers a promising pathway for accelerating the search for novel and efficient catalysts.
The Tree of Diffusion Life: Evolutionary Embeddings to Understand the Generation Process of Diffusion Models
Jun 25, 2024Diffusion models generate high-quality samples by corrupting data with Gaussian noise and iteratively reconstructing it with deep learning, slowly transforming noisy images into refined outputs. Understanding this data evolution is important for interpretability but is complex due to its high-dimensional evolutionary nature. While traditional dimensionality reduction methods like t-distributed stochastic neighborhood embedding (t-SNE) aid in understanding high-dimensional spaces, they neglect evolutionary structure preservation. Hence, we propose Tree of Diffusion Life (TDL), a method to understand data evolution in the generative process of diffusion models. TDL samples a diffusion model's generative space via instances with varying prompts and employs image encoders to extract semantic meaning from these samples, projecting them to an intermediate space. It employs a novel evolutionary embedding algorithm that explicitly encodes the iterations while preserving the high-dimensional relations, facilitating the visualization of data evolution. This embedding leverages three metrics: a standard t-SNE loss to group semantically similar elements, a displacement loss to group elements from the same iteration step, and an instance alignment loss to align elements of the same instance across iterations. We present rectilinear and radial layouts to represent iterations, enabling comprehensive exploration. We assess various feature extractors and highlight TDL's potential with prominent diffusion models like GLIDE and Stable Diffusion with different prompt sets. TDL simplifies understanding data evolution within diffusion models, offering valuable insights into their functioning.
ParaDime: A Framework for Parametric Dimensionality Reduction
Oct 10, 2022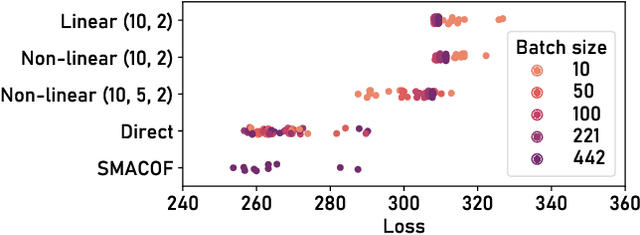
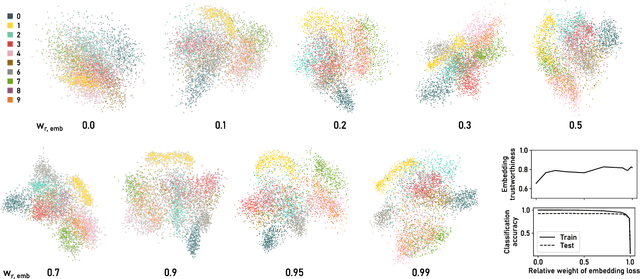
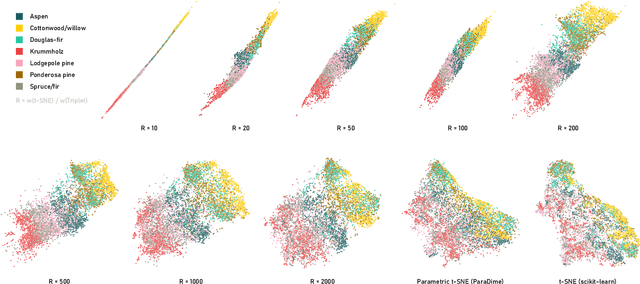
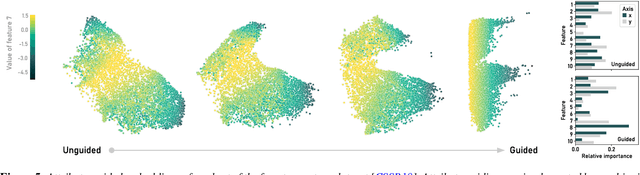
ParaDime is a framework for parametric dimensionality reduction (DR). In parametric DR, neural networks are trained to embed high-dimensional data items in a low-dimensional space while minimizing an objective function. ParaDime builds on the idea that the objective functions of several modern DR techniques result from transformed inter-item relationships. It provides a common interface to specify the way these relations and transformations are computed and how they are used within the losses that govern the training process. Through this interface, ParaDime unifies parametric versions of DR techniques such as metric MDS, t-SNE, and UMAP. Furthermore, it allows users to fully customize each aspect of the DR process. We show how this ease of customization makes ParaDime suitable for experimenting with interesting techniques, such as hybrid classification/embedding models or supervised DR, which opens up new possibilities for visualizing high-dimensional data.