 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatryODShka: Real-time 6DoF Video View Synthesis using Multi-Sphere Images
Aug 14, 2020We introduce a method to convert stereo 360{\deg} (omnidirectional stereo) imagery into a layered, multi-sphere image representation for six degree-of-freedom (6DoF) rendering. Stereo 360{\deg} imagery can be captured from multi-camera systems for virtual reality (VR), but lacks motion parallax and correct-in-all-directions disparity cues. Together, these can quickly lead to VR sickness when viewing content. One solution is to try and generate a format suitable for 6DoF rendering, such as by estimating depth. However, this raises questions as to how to handle disoccluded regions in dynamic scenes. Our approach is to simultaneously learn depth and disocclusions via a multi-sphere image representation, which can be rendered with correct 6DoF disparity and motion parallax in VR. This significantly improves comfort for the viewer, and can be inferred and rendered in real time on modern GPU hardware. Together, these move towards making VR video a more comfortable immersive medium.
Combining Task Predictors via Enhancing Joint Predictability
Jul 15, 2020

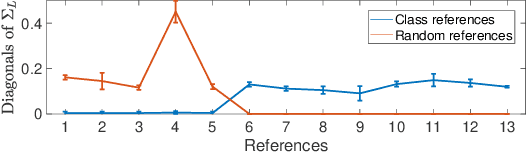

Predictor combination aims to improve a (target) predictor of a learning task based on the (reference) predictors of potentially relevant tasks, without having access to the internals of individual predictors. We present a new predictor combination algorithm that improves the target by i) measuring the relevance of references based on their capabilities in predicting the target, and ii) strengthening such estimated relevance. Unlike existing predictor combination approaches that only exploit pairwise relationships between the target and each reference, and thereby ignore potentially useful dependence among references, our algorithm jointly assesses the relevance of all references by adopting a Bayesian framework. This also offers a rigorous way to automatically select only relevant references. Based on experiments on seven real-world datasets from visual attribute ranking and multi-class classification scenarios, we demonstrate that our algorithm offers a significant performance gain and broadens the application range of existing predictor combination approaches.
BlockGAN: Learning 3D Object-aware Scene Representations from Unlabelled Images
Feb 26, 2020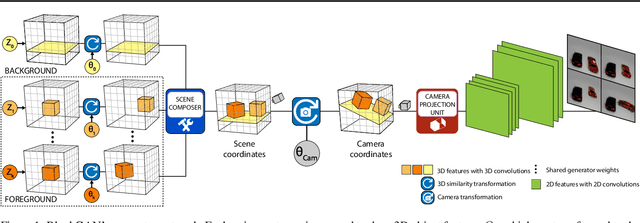

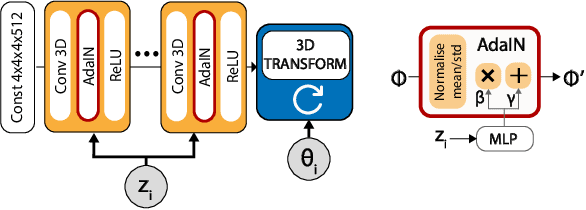

We present BlockGAN, an image generative model that learns object-aware 3D scene representations directly from unlabelled 2D images. Current work on scene representation learning either ignores scene background or treats the whole scene as one object. Meanwhile, work that considers scene compositionality treats scene objects only as image patches or 2D layers with alpha maps. Inspired by the computer graphics pipeline, we design BlockGAN to learn to first generate 3D features of background and foreground objects, then combine them into 3D features for the wholes cene, and finally render them into realistic images. This allows BlockGAN to reason over occlusion and interaction between objects' appearance, such as shadow and lighting, and provides control over each object's 3D pose and identity, while maintaining image realism. BlockGAN is trained end-to-end, using only unlabelled single images, without the need for 3D geometry, pose labels, object masks, or multiple views of the same scene. Our experiments show that using explicit 3D features to represent objects allows BlockGAN to learn disentangled representations both in terms of objects (foreground and background) and their properties (pose and identity).
Neural Style-Preserving Visual Dubbing
Sep 06, 2019
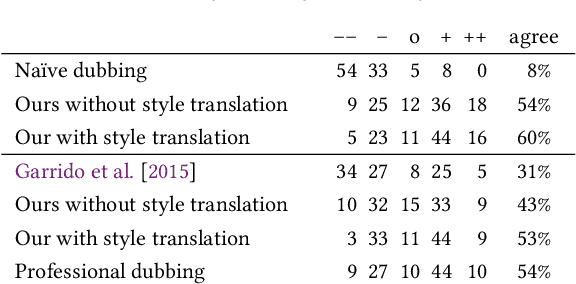
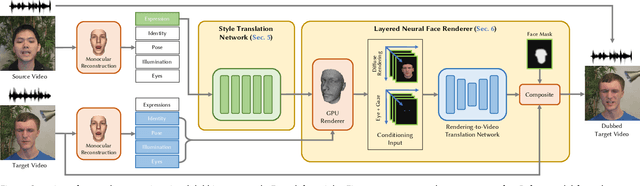
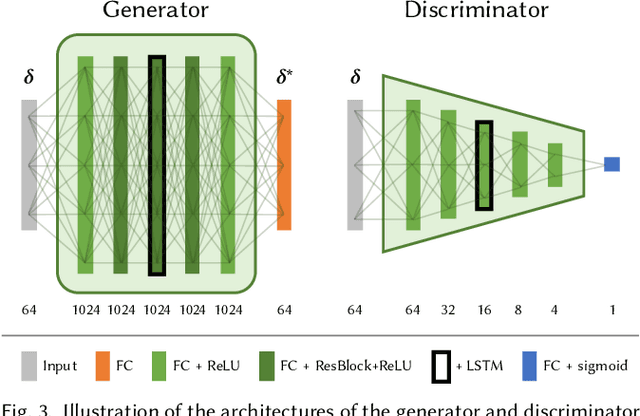
Dubbing is a technique for translating video content from one language to another. However, state-of-the-art visual dubbing techniques directly copy facial expressions from source to target actors without considering identity-specific idiosyncrasies such as a unique type of smile. We present a style-preserving visual dubbing approach from single video inputs, which maintains the signature style of target actors when modifying facial expressions, including mouth motions, to match foreign languages. At the heart of our approach is the concept of motion style, in particular for facial expressions, i.e., the person-specific expression change that is yet another essential factor beyond visual accuracy in face editing applications. Our method is based on a recurrent generative adversarial network that captures the spatiotemporal co-activation of facial expressions, and enables generating and modifying the facial expressions of the target actor while preserving their style. We train our model with unsynchronized source and target videos in an unsupervised manner using cycle-consistency and mouth expression losses, and synthesize photorealistic video frames using a layered neural face renderer. Our approach generates temporally coherent results, and handles dynamic backgrounds. Our results show that our dubbing approach maintains the idiosyncratic style of the target actor better than previous approaches, even for widely differing source and target actors.
Live Illumination Decomposition of Videos
Aug 06, 2019
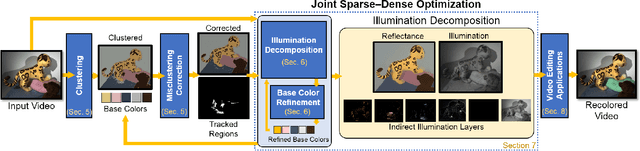
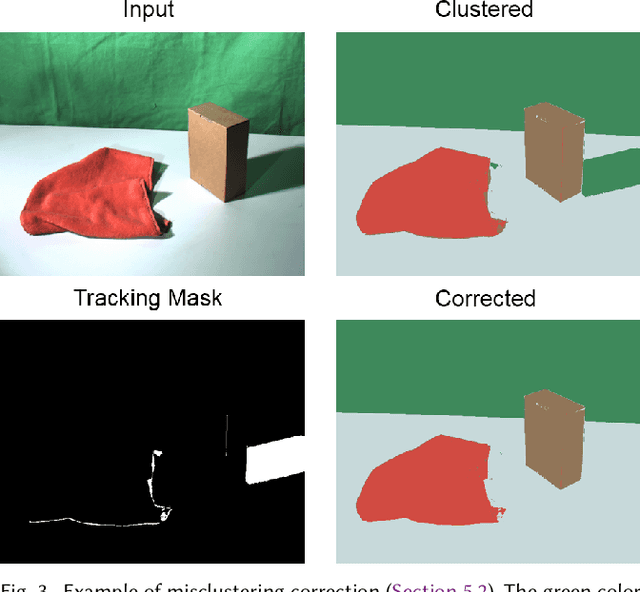
We propose the first approach for the decomposition of a monocular color video into direct and indirect illumination components in real-time. We retrieve, in separate layers, the contribution made to the scene appearance by the scene reflectance, the light sources and the reflections from various coherent scene regions to one another. Existing techniques that invert global light transport require image capture under multiplexed controlled lighting, or only enable the decomposition of a single image at slow off-line frame rates. In contrast, our approach works for regular videos and produces temporally coherent decomposition layers at real-time frame rates. At the core of our approach are several sparsity priors that enable the estimation of the per-pixel direct and indirect illumination layers based on a small set of jointly estimated base reflectance colors. The resulting variational decomposition problem uses a new formulation based on sparse and dense sets of non-linear equations that we solve efficiently using a novel alternating data-parallel optimization strategy. We evaluate our approach qualitatively and quantitatively, and show improvements over the state of the art in this field, in both quality and runtime. In addition, we demonstrate various real-time appearance editing applications for videos with consistent illumination.
HoloGAN: Unsupervised learning of 3D representations from natural images
Apr 02, 2019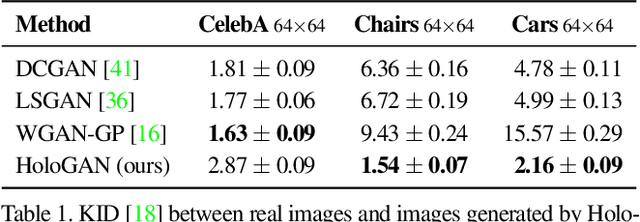
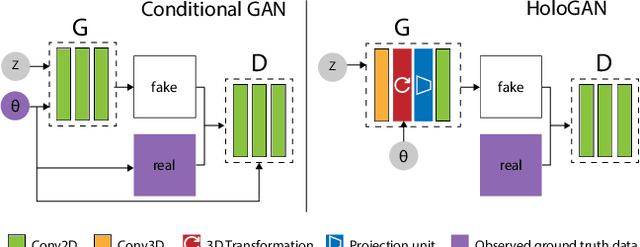
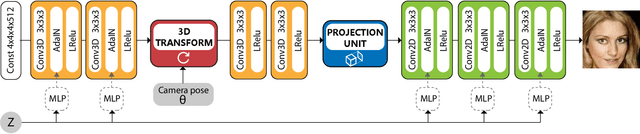

We propose a novel generative adversarial network (GAN) for the task of unsupervised learning of 3D representations from natural images. Most generative models rely on 2D kernels to generate images and make few assumptions about the 3D world. These models therefore tend to create blurry images or artefacts in tasks that require a strong 3D understanding, such as novel-view synthesis. HoloGAN instead learns a 3D representation of the world, and to render this representation in a realistic manner. Unlike other GANs, HoloGAN provides explicit control over the pose of generated objects through rigid-body transformations of the learnt 3D features. Our experiments show that using explicit 3D features enables HoloGAN to disentangle 3D pose and identity, which is further decomposed into shape and appearance, while still being able to generate images with similar or higher visual quality than other generative models. HoloGAN can be trained end-to-end from unlabelled 2D images only. Particularly, we do not require pose labels, 3D shapes, or multiple views of the same objects. This shows that HoloGAN is the first generative model that learns 3D representations from natural images in an entirely unsupervised manner.
Unsupervised Attention-guided Image to Image Translation
Jun 19, 2018
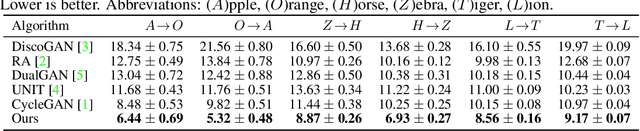
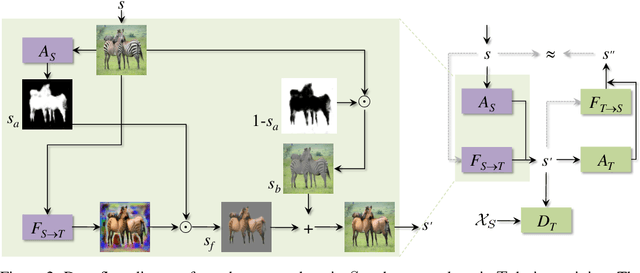

Current unsupervised image-to-image translation techniques struggle to focus their attention on individual objects without altering the background or the way multiple objects interact within a scene. Motivated by the important role of attention in human perception, we tackle this limitation by introducing unsupervised attention mechanisms that are jointly adversarialy trained with the generators and discriminators. We demonstrate qualitatively and quantitatively that our approach is able to attend to relevant regions in the image without requiring supervision, and that by doing so it achieves more realistic mappings compared to recent approaches.
Deep Video Portraits
May 29, 2018
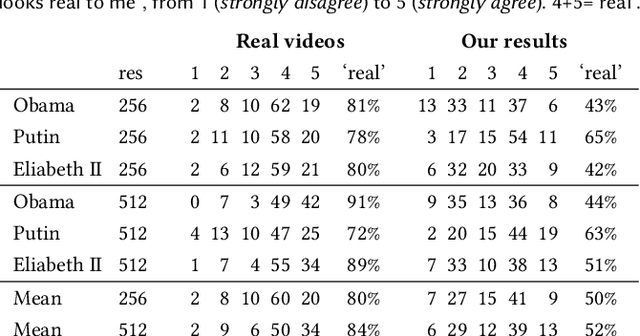
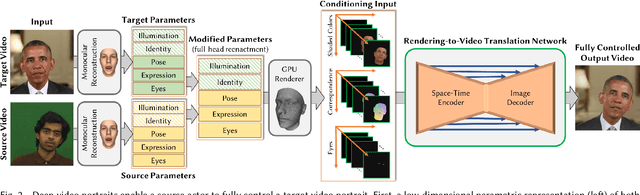
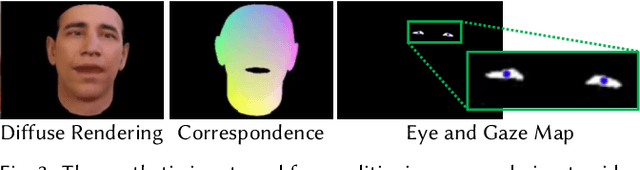
We present a novel approach that enables photo-realistic re-animation of portrait videos using only an input video. In contrast to existing approaches that are restricted to manipulations of facial expressions only, we are the first to transfer the full 3D head position, head rotation, face expression, eye gaze, and eye blinking from a source actor to a portrait video of a target actor. The core of our approach is a generative neural network with a novel space-time architecture. The network takes as input synthetic renderings of a parametric face model, based on which it predicts photo-realistic video frames for a given target actor. The realism in this rendering-to-video transfer is achieved by careful adversarial training, and as a result, we can create modified target videos that mimic the behavior of the synthetically-created input. In order to enable source-to-target video re-animation, we render a synthetic target video with the reconstructed head animation parameters from a source video, and feed it into the trained network -- thus taking full control of the target. With the ability to freely recombine source and target parameters, we are able to demonstrate a large variety of video rewrite applications without explicitly modeling hair, body or background. For instance, we can reenact the full head using interactive user-controlled editing, and realize high-fidelity visual dubbing. To demonstrate the high quality of our output, we conduct an extensive series of experiments and evaluations, where for instance a user study shows that our video edits are hard to detect.
InverseFaceNet: Deep Monocular Inverse Face Rendering
May 16, 2018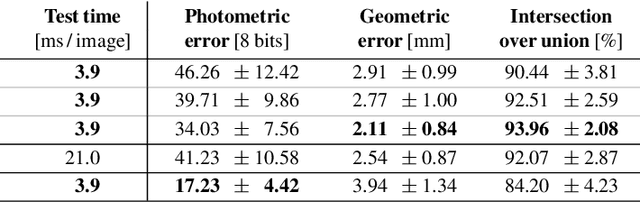
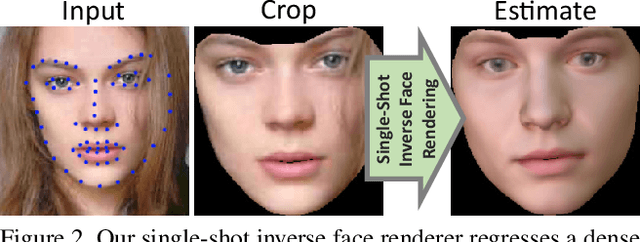
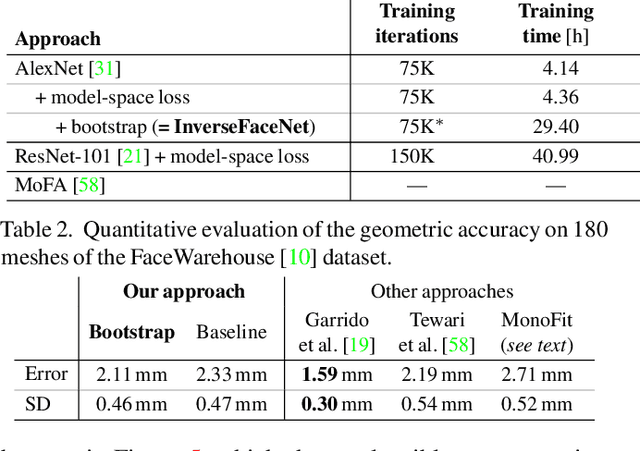

We introduce InverseFaceNet, a deep convolutional inverse rendering framework for faces that jointly estimates facial pose, shape, expression, reflectance and illumination from a single input image. By estimating all parameters from just a single image, advanced editing possibilities on a single face image, such as appearance editing and relighting, become feasible in real time. Most previous learning-based face reconstruction approaches do not jointly recover all dimensions, or are severely limited in terms of visual quality. In contrast, we propose to recover high-quality facial pose, shape, expression, reflectance and illumination using a deep neural network that is trained using a large, synthetically created training corpus. Our approach builds on a novel loss function that measures model-space similarity directly in parameter space and significantly improves reconstruction accuracy. We further propose a self-supervised bootstrapping process in the network training loop, which iteratively updates the synthetic training corpus to better reflect the distribution of real-world imagery. We demonstrate that this strategy outperforms completely synthetically trained networks. Finally, we show high-quality reconstructions and compare our approach to several state-of-the-art approaches.
LIME: Live Intrinsic Material Estimation
May 04, 2018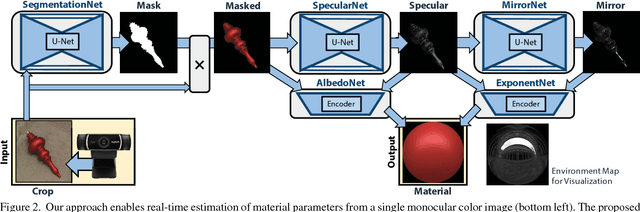
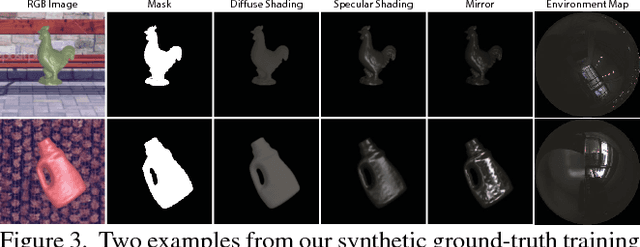


We present the first end to end approach for real time material estimation for general object shapes with uniform material that only requires a single color image as input. In addition to Lambertian surface properties, our approach fully automatically computes the specular albedo, material shininess, and a foreground segmentation. We tackle this challenging and ill posed inverse rendering problem using recent advances in image to image translation techniques based on deep convolutional encoder decoder architectures. The underlying core representations of our approach are specular shading, diffuse shading and mirror images, which allow to learn the effective and accurate separation of diffuse and specular albedo. In addition, we propose a novel highly efficient perceptual rendering loss that mimics real world image formation and obtains intermediate results even during run time. The estimation of material parameters at real time frame rates enables exciting mixed reality applications, such as seamless illumination consistent integration of virtual objects into real world scenes, and virtual material cloning. We demonstrate our approach in a live setup, compare it to the state of the art, and demonstrate its effectiveness through quantitative and qualitative evaluation.