 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Wide-Baseline Scene Flow From Two Handheld Video Cameras
Sep 16, 2016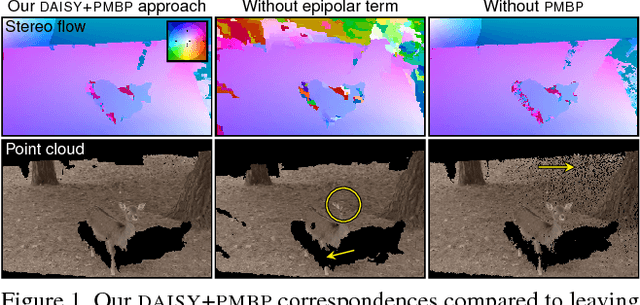

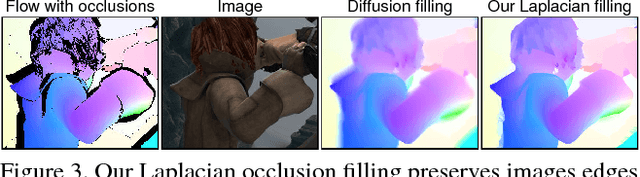
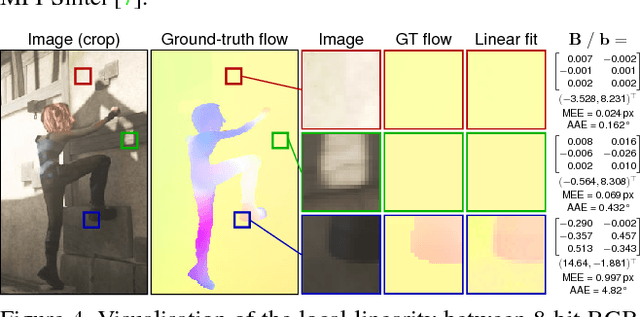
We propose a new technique for computing dense scene flow from two handheld videos with wide camera baselines and different photometric properties due to different sensors or camera settings like exposure and white balance. Our technique innovates in two ways over existing methods: (1) it supports independently moving cameras, and (2) it computes dense scene flow for wide-baseline scenarios.We achieve this by combining state-of-the-art wide-baseline correspondence finding with a variational scene flow formulation. First, we compute dense, wide-baseline correspondences using DAISY descriptors for matching between cameras and over time. We then detect and replace occluded pixels in the correspondence fields using a novel edge-preserving Laplacian correspondence completion technique. We finally refine the computed correspondence fields in a variational scene flow formulation. We show dense scene flow results computed from challenging datasets with independently moving, handheld cameras of varying camera settings.
Automatic Face Reenactment
Feb 08, 2016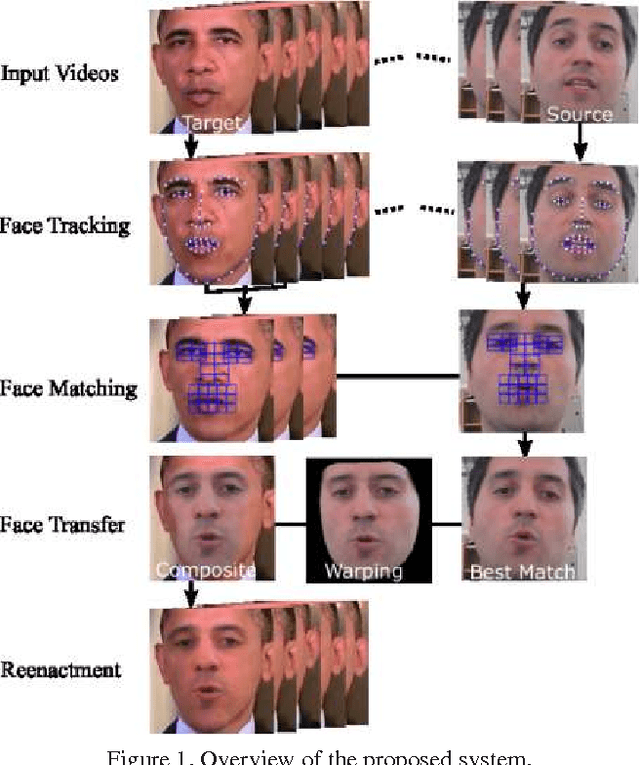
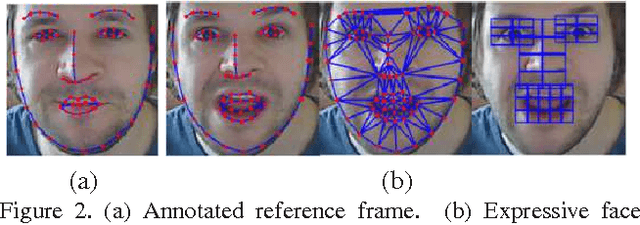
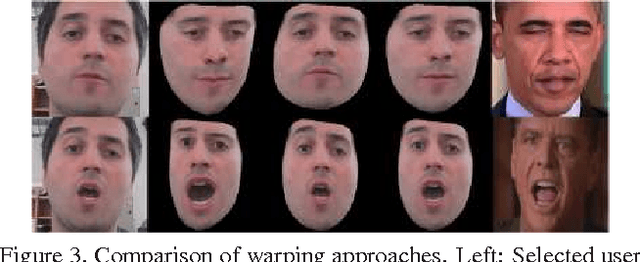

We propose an image-based, facial reenactment system that replaces the face of an actor in an existing target video with the face of a user from a source video, while preserving the original target performance. Our system is fully automatic and does not require a database of source expressions. Instead, it is able to produce convincing reenactment results from a short source video captured with an off-the-shelf camera, such as a webcam, where the user performs arbitrary facial gestures. Our reenactment pipeline is conceived as part image retrieval and part face transfer: The image retrieval is based on temporal clustering of target frames and a novel image matching metric that combines appearance and motion to select candidate frames from the source video, while the face transfer uses a 2D warping strategy that preserves the user's identity. Our system excels in simplicity as it does not rely on a 3D face model, it is robust under head motion and does not require the source and target performance to be similar. We show convincing reenactment results for videos that we recorded ourselves and for low-quality footage taken from the Internet.