 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChristian Kroer
Solving optimization problems with Blackwell approachability
Feb 24, 2022
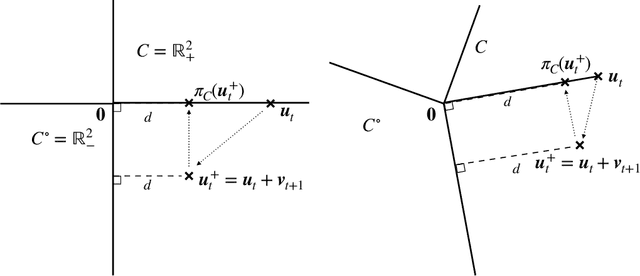
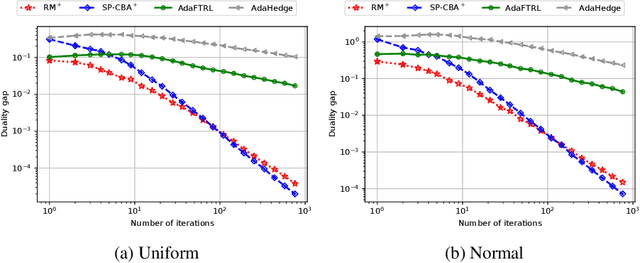
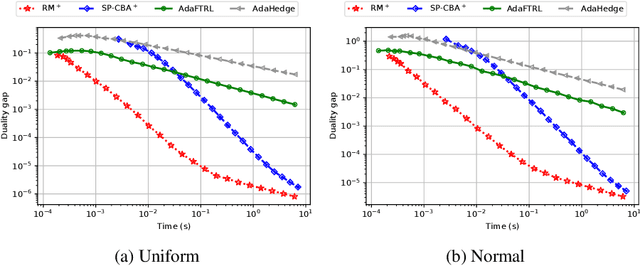
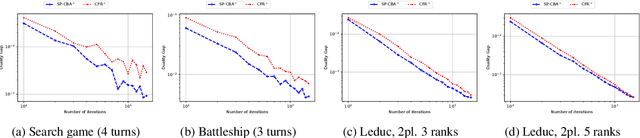
We introduce the Conic Blackwell Algorithm$^+$ (CBA$^+$) regret minimizer, a new parameter- and scale-free regret minimizer for general convex sets. CBA$^+$ is based on Blackwell approachability and attains $O(\sqrt{T})$ regret. We show how to efficiently instantiate CBA$^+$ for many decision sets of interest, including the simplex, $\ell_{p}$ norm balls, and ellipsoidal confidence regions in the simplex. Based on CBA$^+$, we introduce SP-CBA$^+$, a new parameter-free algorithm for solving convex-concave saddle-point problems, which achieves a $O(1/\sqrt{T})$ ergodic rate of convergence. In our simulations, we demonstrate the wide applicability of SP-CBA$^+$ on several standard saddle-point problems, including matrix games, extensive-form games, distributionally robust logistic regression, and Markov decision processes. In each setting, SP-CBA$^+$ achieves state-of-the-art numerical performance, and outperforms classical methods, without the need for any choice of step sizes or other algorithmic parameters.
Single-Leg Revenue Management with Advice
Feb 18, 2022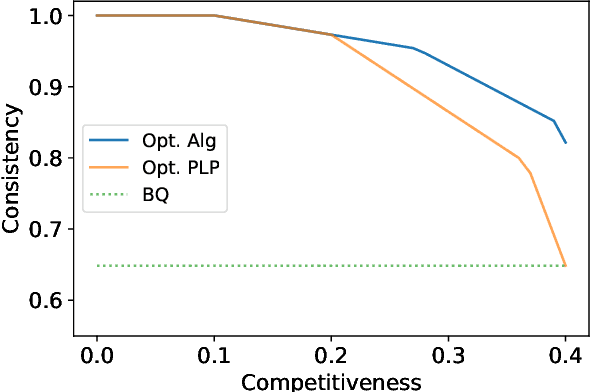
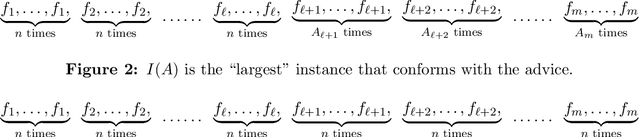
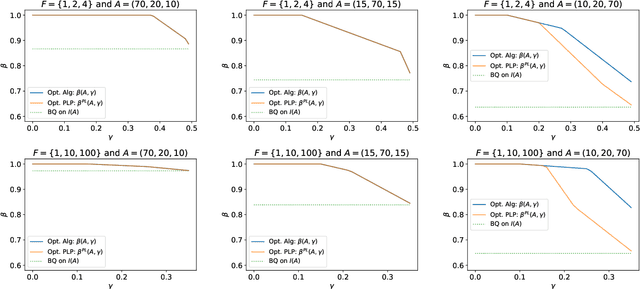
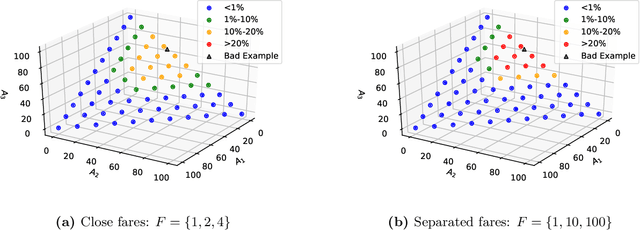
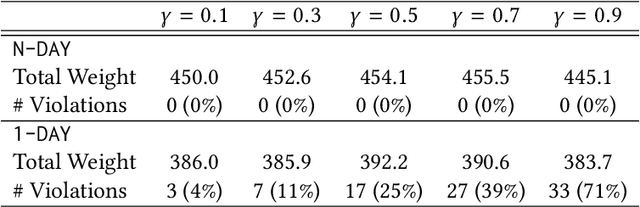
Single-leg revenue management is a foundational problem of revenue management that has been particularly impactful in the airline and hotel industry: Given $n$ units of a resource, e.g. flight seats, and a stream of sequentially-arriving customers segmented by fares, what is the optimal online policy for allocating the resource. Previous work focused on designing algorithms when forecasts are available, which are not robust to inaccuracies in the forecast, or online algorithms with worst-case performance guarantees, which can be too conservative in practice. In this work, we look at the single-leg revenue management problem through the lens of the algorithms-with-advice framework, which attempts to optimally incorporate advice/predictions about the future into online algorithms. In particular, we characterize the Pareto frontier that captures the tradeoff between consistency (performance when advice is accurate) and competitiveness (performance when advice is inaccurate) for every advice. Moreover, we provide an online algorithm that always achieves performance on this Pareto frontier. We also study the class of protection level policies, which is the most widely-deployed technique for single-leg revenue management: we provide an algorithm to incorporate advice into protection levels that optimally trades off consistency and competitiveness. Moreover, we empirically evaluate the performance of these algorithms on synthetic data. We find that our algorithm for protection level policies performs remarkably well on most instances, even if it is not guaranteed to be on the Pareto frontier in theory.
Kernelized Multiplicative Weights for 0/1-Polyhedral Games: Bridging the Gap Between Learning in Extensive-Form and Normal-Form Games
Feb 01, 2022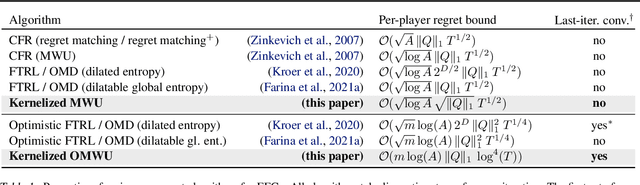
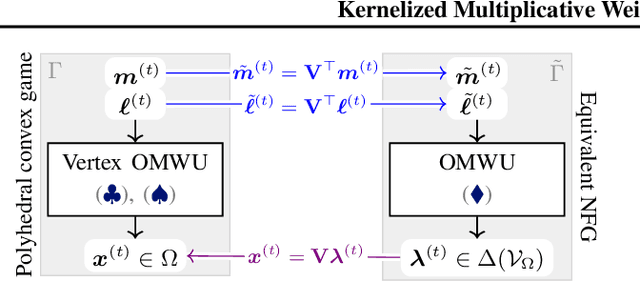
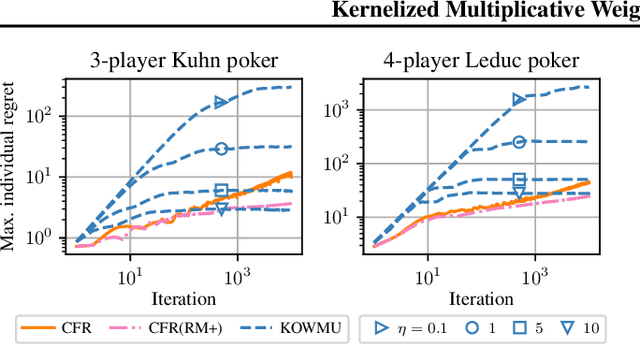
While extensive-form games (EFGs) can be converted into normal-form games (NFGs), doing so comes at the cost of an exponential blowup of the strategy space. So, progress on NFGs and EFGs has historically followed separate tracks, with the EFG community often having to catch up with advances (e.g., last-iterate convergence and predictive regret bounds) from the larger NFG community. In this paper we show that the Optimistic Multiplicative Weights Update (OMWU) algorithm -- the premier learning algorithm for NFGs -- can be simulated on the normal-form equivalent of an EFG in linear time per iteration in the game tree size using a kernel trick. The resulting algorithm, Kernelized OMWU (KOMWU), applies more broadly to all convex games whose strategy space is a polytope with 0/1 integral vertices, as long as the kernel can be evaluated efficiently. In the particular case of EFGs, KOMWU closes several standing gaps between NFG and EFG learning, by enabling direct, black-box transfer to EFGs of desirable properties of learning dynamics that were so far known to be achievable only in NFGs. Specifically, KOMWU gives the first algorithm that guarantees at the same time last-iterate convergence, lower dependence on the size of the game tree than all prior algorithms, and $\tilde{\mathcal{O}}(1)$ regret when followed by all players.
Matching Algorithms for Blood Donation
Aug 13, 2021

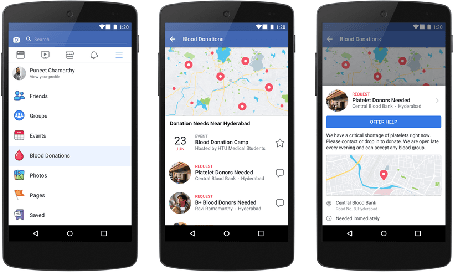
Global demand for donated blood far exceeds supply, and unmet need is greatest in low- and middle-income countries; experts suggest that large-scale coordination is necessary to alleviate demand. Using the Facebook Blood Donation tool, we conduct the first large-scale algorithmic matching of blood donors with donation opportunities. While measuring actual donation rates remains a challenge, we measure donor action (e.g., making a donation appointment) as a proxy for actual donation. We develop automated policies for matching donors with donation opportunities, based on an online matching model. We provide theoretical guarantees for these policies, both regarding the number of expected donations and the equitable treatment of blood recipients. In simulations, a simple matching strategy increases the number of donations by 5-10%; a pilot experiment with real donors shows a 5% relative increase in donor action rate (from 3.7% to 3.9%). When scaled to the global Blood Donation tool user base, this corresponds to an increase of around one hundred thousand users taking action toward donation. Further, observing donor action on a social network can shed light onto donor behavior and response to incentives. Our initial findings align with several observations made in the medical and social science literature regarding donor behavior.
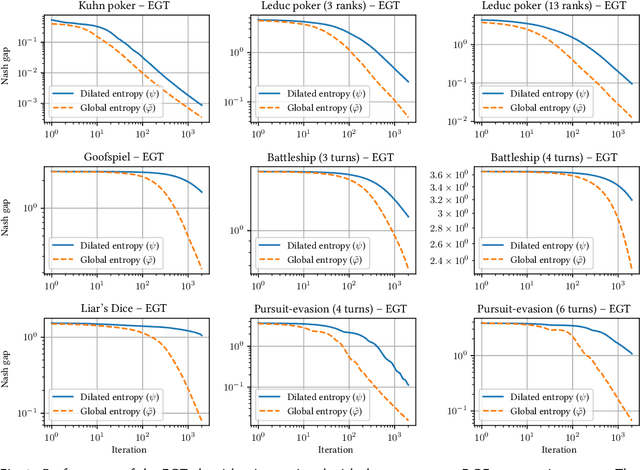
Last-iterate Convergence in Extensive-Form Games
Jun 27, 2021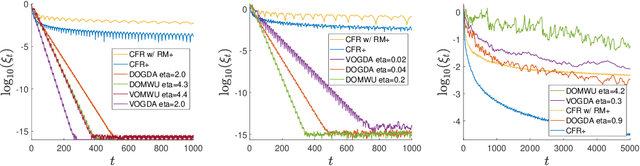
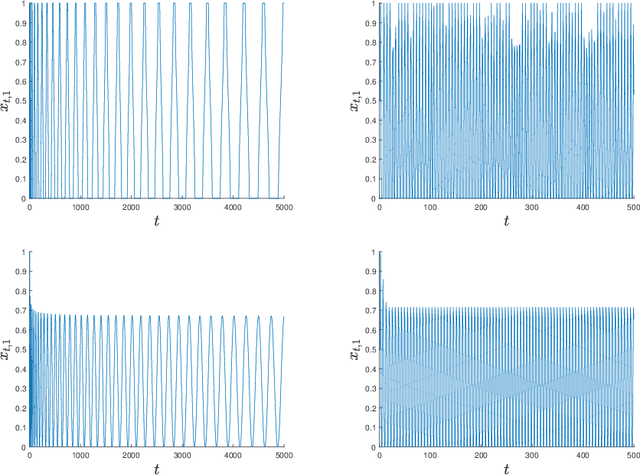
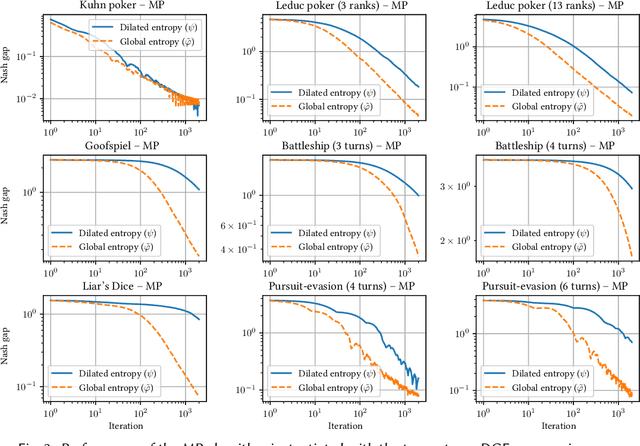
Regret-based algorithms are highly efficient at finding approximate Nash equilibria in sequential games such as poker games. However, most regret-based algorithms, including counterfactual regret minimization (CFR) and its variants, rely on iterate averaging to achieve convergence. Inspired by recent advances on last-iterate convergence of optimistic algorithms in zero-sum normal-form games, we study this phenomenon in sequential games, and provide a comprehensive study of last-iterate convergence for zero-sum extensive-form games with perfect recall (EFGs), using various optimistic regret-minimization algorithms over treeplexes. This includes algorithms using the vanilla entropy or squared Euclidean norm regularizers, as well as their dilated versions which admit more efficient implementation. In contrast to CFR, we show that all of these algorithms enjoy last-iterate convergence, with some of them even converging exponentially fast. We also provide experiments to further support our theoretical results.
Conic Blackwell Algorithm: Parameter-Free Convex-Concave Saddle-Point Solving
Jun 10, 2021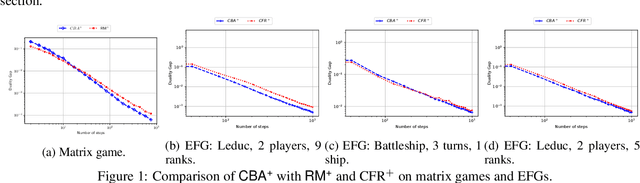
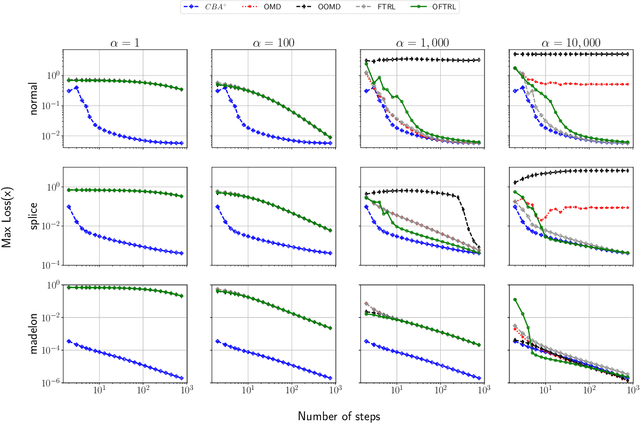
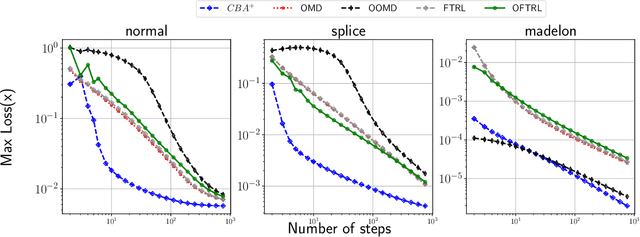
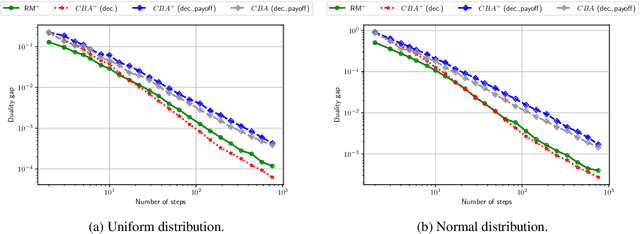
We develop new parameter and scale-free algorithms for solving convex-concave saddle-point problems. Our results are based on a new simple regret minimizer, the Conic Blackwell Algorithm$^+$ (CBA$^+$), which attains $O(1/\sqrt{T})$ average regret. Intuitively, our approach generalizes to other decision sets of interest ideas from the Counterfactual Regret minimization (CFR$^+$) algorithm, which has very strong practical performance for solving sequential games on simplexes. We show how to implement CBA$^+$ for the simplex, $\ell_{p}$ norm balls, and ellipsoidal confidence regions in the simplex, and we present numerical experiments for solving matrix games and distributionally robust optimization problems. Our empirical results show that CBA$^+$ is a simple algorithm that outperforms state-of-the-art methods on synthetic data and real data instances, without the need for any choice of step sizes or other algorithmic parameters.
Better Regularization for Sequential Decision Spaces: Fast Convergence Rates for Nash, Correlated, and Team Equilibria
May 27, 2021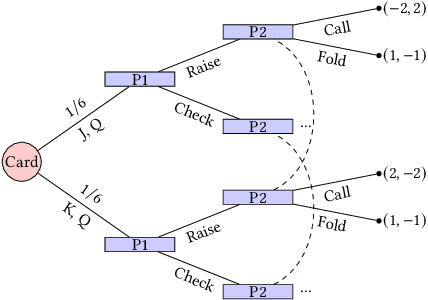
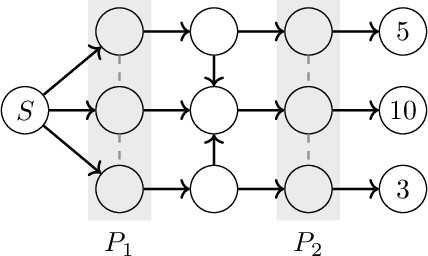
We study the application of iterative first-order methods to the problem of computing equilibria of large-scale two-player extensive-form games. First-order methods must typically be instantiated with a regularizer that serves as a distance-generating function for the decision sets of the players. For the case of two-player zero-sum games, the state-of-the-art theoretical convergence rate for Nash equilibrium is achieved by using the dilated entropy function. In this paper, we introduce a new entropy-based distance-generating function for two-player zero-sum games, and show that this function achieves significantly better strong convexity properties than the dilated entropy, while maintaining the same easily-implemented closed-form proximal mapping. Extensive numerical simulations show that these superior theoretical properties translate into better numerical performance as well. We then generalize our new entropy distance function, as well as general dilated distance functions, to the scaled extension operator. The scaled extension operator is a way to recursively construct convex sets, which generalizes the decision polytope of extensive-form games, as well as the convex polytopes corresponding to correlated and team equilibria. By instantiating first-order methods with our regularizers, we develop the first accelerated first-order methods for computing correlated equilibra and ex-ante coordinated team equilibria. Our methods have a guaranteed $1/T$ rate of convergence, along with linear-time proximal updates.
Faster Game Solving via Predictive Blackwell Approachability: Connecting Regret Matching and Mirror Descent
Jul 28, 2020
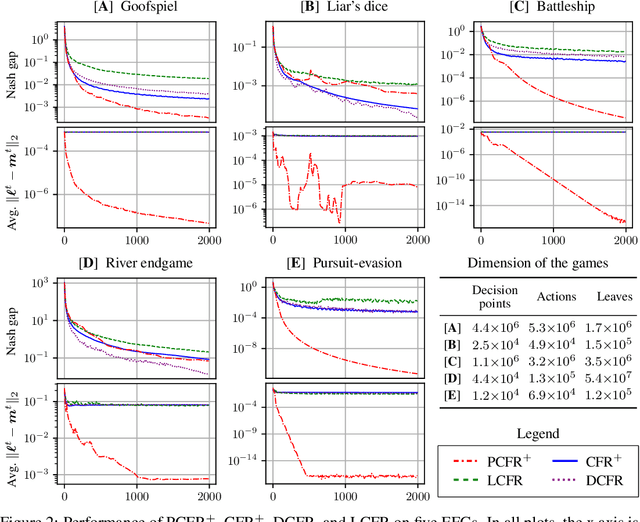
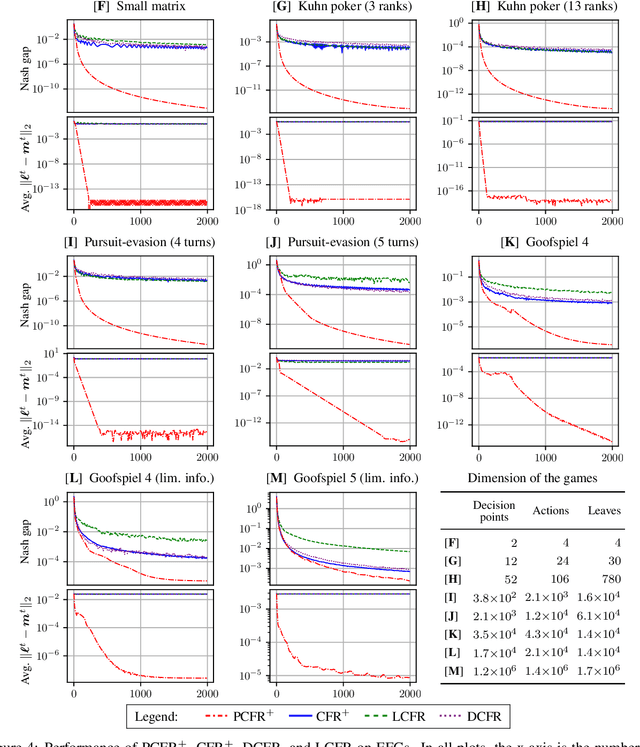
Blackwell approachability is a framework for reasoning about repeated games with vector-valued payoffs. We introduce predictive Blackwell approachability, where an estimate of the next payoff vector is given, and the decision maker tries to achieve better performance based on the accuracy of that estimator. In order to derive algorithms that achieve predictive Blackwell approachability, we start by showing a powerful connection between four well-known algorithms. Follow-the-regularized-leader (FTRL) and online mirror descent (OMD) are the most prevalent regret minimizers in online convex optimization. In spite of this prevalence, the regret matching (RM) and regret matching+ (RM+) algorithms have been preferred in the practice of solving large-scale games (as the local regret minimizers within the counterfactual regret minimization framework). We show that RM and RM+ are the algorithms that result from running FTRL and OMD, respectively, to select the halfspace to force at all times in the underlying Blackwell approachability game. By applying the predictive variants of FTRL or OMD to this connection, we obtain predictive Blackwell approachability algorithms, as well as predictive variants of RM and RM+. In experiments across 18 common zero-sum extensive-form benchmark games, we show that predictive RM+ coupled with counterfactual regret minimization converges vastly faster than the fastest prior algorithms (CFR+, DCFR, LCFR) across all games but two of the poker games and Liar's Dice, sometimes by two or more orders of magnitude.