 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsity-Preserving Differentially Private Training of Large Embedding Models
Nov 14, 2023



As the use of large embedding models in recommendation systems and language applications increases, concerns over user data privacy have also risen. DP-SGD, a training algorithm that combines differential privacy with stochastic gradient descent, has been the workhorse in protecting user privacy without compromising model accuracy by much. However, applying DP-SGD naively to embedding models can destroy gradient sparsity, leading to reduced training efficiency. To address this issue, we present two new algorithms, DP-FEST and DP-AdaFEST, that preserve gradient sparsity during private training of large embedding models. Our algorithms achieve substantial reductions ($10^6 \times$) in gradient size, while maintaining comparable levels of accuracy, on benchmark real-world datasets.
User-Level Differential Privacy With Few Examples Per User
Sep 21, 2023

Previous work on user-level differential privacy (DP) [Ghazi et al. NeurIPS 2021, Bun et al. STOC 2023] obtained generic algorithms that work for various learning tasks. However, their focus was on the example-rich regime, where the users have so many examples that each user could themselves solve the problem. In this work we consider the example-scarce regime, where each user has only a few examples, and obtain the following results: 1. For approximate-DP, we give a generic transformation of any item-level DP algorithm to a user-level DP algorithm. Roughly speaking, the latter gives a (multiplicative) savings of $O_{\varepsilon,\delta}(\sqrt{m})$ in terms of the number of users required for achieving the same utility, where $m$ is the number of examples per user. This algorithm, while recovering most known bounds for specific problems, also gives new bounds, e.g., for PAC learning. 2. For pure-DP, we present a simple technique for adapting the exponential mechanism [McSherry, Talwar FOCS 2007] to the user-level setting. This gives new bounds for a variety of tasks, such as private PAC learning, hypothesis selection, and distribution learning. For some of these problems, we show that our bounds are near-optimal.
Can Neural Network Memorization Be Localized?
Jul 18, 2023



Recent efforts at explaining the interplay of memorization and generalization in deep overparametrized networks have posited that neural networks $\textit{memorize}$ "hard" examples in the final few layers of the model. Memorization refers to the ability to correctly predict on $\textit{atypical}$ examples of the training set. In this work, we show that rather than being confined to individual layers, memorization is a phenomenon confined to a small set of neurons in various layers of the model. First, via three experimental sources of converging evidence, we find that most layers are redundant for the memorization of examples and the layers that contribute to example memorization are, in general, not the final layers. The three sources are $\textit{gradient accounting}$ (measuring the contribution to the gradient norms from memorized and clean examples), $\textit{layer rewinding}$ (replacing specific model weights of a converged model with previous training checkpoints), and $\textit{retraining}$ (training rewound layers only on clean examples). Second, we ask a more generic question: can memorization be localized $\textit{anywhere}$ in a model? We discover that memorization is often confined to a small number of neurons or channels (around 5) of the model. Based on these insights we propose a new form of dropout -- $\textit{example-tied dropout}$ that enables us to direct the memorization of examples to an apriori determined set of neurons. By dropping out these neurons, we are able to reduce the accuracy on memorized examples from $100\%\to3\%$, while also reducing the generalization gap.
Ticketed Learning-Unlearning Schemes
Jun 27, 2023



We consider the learning--unlearning paradigm defined as follows. First given a dataset, the goal is to learn a good predictor, such as one minimizing a certain loss. Subsequently, given any subset of examples that wish to be unlearnt, the goal is to learn, without the knowledge of the original training dataset, a good predictor that is identical to the predictor that would have been produced when learning from scratch on the surviving examples. We propose a new ticketed model for learning--unlearning wherein the learning algorithm can send back additional information in the form of a small-sized (encrypted) ``ticket'' to each participating training example, in addition to retaining a small amount of ``central'' information for later. Subsequently, the examples that wish to be unlearnt present their tickets to the unlearning algorithm, which additionally uses the central information to return a new predictor. We provide space-efficient ticketed learning--unlearning schemes for a broad family of concept classes, including thresholds, parities, intersection-closed classes, among others. En route, we introduce the count-to-zero problem, where during unlearning, the goal is to simply know if there are any examples that survived. We give a ticketed learning--unlearning scheme for this problem that relies on the construction of Sperner families with certain properties, which might be of independent interest.
On User-Level Private Convex Optimization
May 08, 2023
We introduce a new mechanism for stochastic convex optimization (SCO) with user-level differential privacy guarantees. The convergence rates of this mechanism are similar to those in the prior work of Levy et al. (2021); Narayanan et al. (2022), but with two important improvements. Our mechanism does not require any smoothness assumptions on the loss. Furthermore, our bounds are also the first where the minimum number of users needed for user-level privacy has no dependence on the dimension and only a logarithmic dependence on the desired excess error. The main idea underlying the new mechanism is to show that the optimizers of strongly convex losses have low local deletion sensitivity, along with an output perturbation method for functions with low local deletion sensitivity, which could be of independent interest.
Regression with Label Differential Privacy
Dec 12, 2022



We study the task of training regression models with the guarantee of label differential privacy (DP). Based on a global prior distribution on label values, which could be obtained privately, we derive a label DP randomization mechanism that is optimal under a given regression loss function. We prove that the optimal mechanism takes the form of a ``randomized response on bins'', and propose an efficient algorithm for finding the optimal bin values. We carry out a thorough experimental evaluation on several datasets demonstrating the efficacy of our algorithm.
Private Ad Modeling with DP-SGD
Nov 21, 2022



A well-known algorithm in privacy-preserving ML is differentially private stochastic gradient descent (DP-SGD). While this algorithm has been evaluated on text and image data, it has not been previously applied to ads data, which are notorious for their high class imbalance and sparse gradient updates. In this work we apply DP-SGD to several ad modeling tasks including predicting click-through rates, conversion rates, and number of conversion events, and evaluate their privacy-utility trade-off on real-world datasets. Our work is the first to empirically demonstrate that DP-SGD can provide both privacy and utility for ad modeling tasks.
Preventing Verbatim Memorization in Language Models Gives a False Sense of Privacy
Oct 31, 2022



Studying data memorization in neural language models helps us understand the risks (e.g., to privacy or copyright) associated with models regurgitating training data, and aids in the evaluation of potential countermeasures. Many prior works -- and some recently deployed defenses -- focus on "verbatim memorization", defined as a model generation that exactly matches a substring from the training set. We argue that verbatim memorization definitions are too restrictive and fail to capture more subtle forms of memorization. Specifically, we design and implement an efficient defense based on Bloom filters that perfectly prevents all verbatim memorization. And yet, we demonstrate that this "perfect" filter does not prevent the leakage of training data. Indeed, it is easily circumvented by plausible and minimally modified "style-transfer" prompts -- and in some cases even the non-modified original prompts -- to extract memorized information. For example, instructing the model to output ALL-CAPITAL texts bypasses memorization checks based on verbatim matching. We conclude by discussing potential alternative definitions and why defining memorization is a difficult yet crucial open question for neural language models.
Measuring Forgetting of Memorized Training Examples
Jun 30, 2022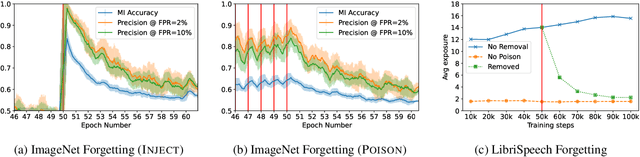
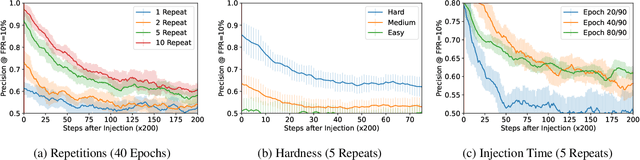
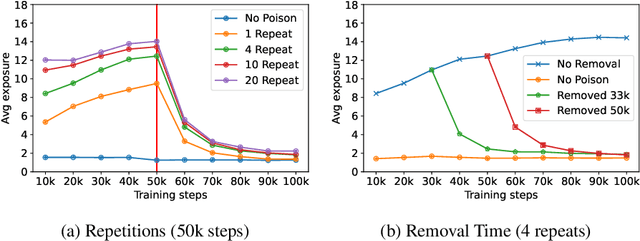
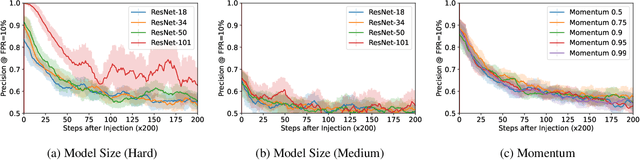
Machine learning models exhibit two seemingly contradictory phenomena: training data memorization and various forms of forgetting. In memorization, models overfit specific training examples and become susceptible to privacy attacks. In forgetting, examples which appeared early in training are forgotten by the end. In this work, we connect these phenomena. We propose a technique to measure to what extent models ``forget'' the specifics of training examples, becoming less susceptible to privacy attacks on examples they have not seen recently. We show that, while non-convexity can prevent forgetting from happening in the worst-case, standard image and speech models empirically do forget examples over time. We identify nondeterminism as a potential explanation, showing that deterministically trained models do not forget. Our results suggest that examples seen early when training with extremely large datasets -- for instance those examples used to pre-train a model -- may observe privacy benefits at the expense of examples seen later.
The Privacy Onion Effect: Memorization is Relative
Jun 22, 2022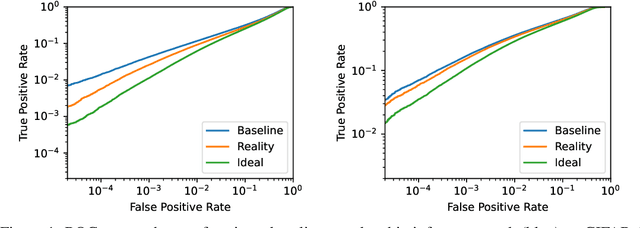
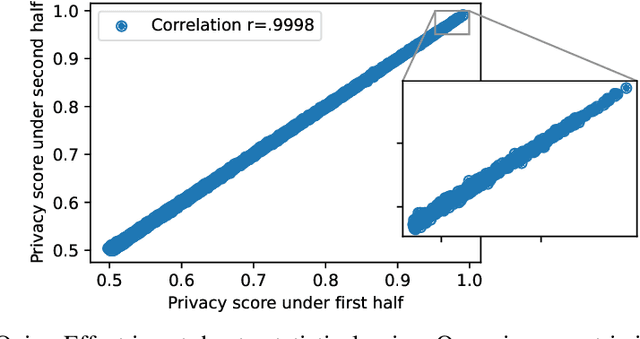
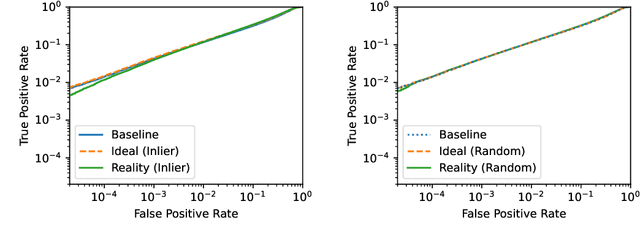
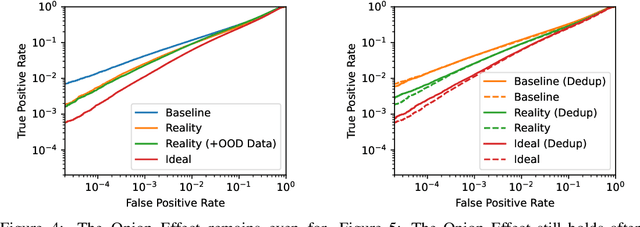
Machine learning models trained on private datasets have been shown to leak their private data. While recent work has found that the average data point is rarely leaked, the outlier samples are frequently subject to memorization and, consequently, privacy leakage. We demonstrate and analyse an Onion Effect of memorization: removing the "layer" of outlier points that are most vulnerable to a privacy attack exposes a new layer of previously-safe points to the same attack. We perform several experiments to study this effect, and understand why it occurs. The existence of this effect has various consequences. For example, it suggests that proposals to defend against memorization without training with rigorous privacy guarantees are unlikely to be effective. Further, it suggests that privacy-enhancing technologies such as machine unlearning could actually harm the privacy of other users.