 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Explanation Policies in RL
Jul 25, 2023



As Reinforcement Learning (RL) agents are increasingly employed in diverse decision-making problems using reward preferences, it becomes important to ensure that policies learned by these frameworks in mapping observations to a probability distribution of the possible actions are explainable. However, there is little to no work in the systematic understanding of these complex policies in a contrastive manner, i.e., what minimal changes to the policy would improve/worsen its performance to a desired level. In this work, we present COUNTERPOL, the first framework to analyze RL policies using counterfactual explanations in the form of minimal changes to the policy that lead to the desired outcome. We do so by incorporating counterfactuals in supervised learning in RL with the target outcome regulated using desired return. We establish a theoretical connection between Counterpol and widely used trust region-based policy optimization methods in RL. Extensive empirical analysis shows the efficacy of COUNTERPOL in generating explanations for (un)learning skills while keeping close to the original policy. Our results on five different RL environments with diverse state and action spaces demonstrate the utility of counterfactual explanations, paving the way for new frontiers in designing and developing counterfactual policies.
Explaining RL Decisions with Trajectories
May 06, 2023



Explanation is a key component for the adoption of reinforcement learning (RL) in many real-world decision-making problems. In the literature, the explanation is often provided by saliency attribution to the features of the RL agent's state. In this work, we propose a complementary approach to these explanations, particularly for offline RL, where we attribute the policy decisions of a trained RL agent to the trajectories encountered by it during training. To do so, we encode trajectories in offline training data individually as well as collectively (encoding a set of trajectories). We then attribute policy decisions to a set of trajectories in this encoded space by estimating the sensitivity of the decision with respect to that set. Further, we demonstrate the effectiveness of the proposed approach in terms of quality of attributions as well as practical scalability in diverse environments that involve both discrete and continuous state and action spaces such as grid-worlds, video games (Atari) and continuous control (MuJoCo). We also conduct a human study on a simple navigation task to observe how their understanding of the task compares with data attributed for a trained RL policy. Keywords -- Explainable AI, Verifiability of AI Decisions, Explainable RL.
Explain like I am BM25: Interpreting a Dense Model's Ranked-List with a Sparse Approximation
Apr 25, 2023



Neural retrieval models (NRMs) have been shown to outperform their statistical counterparts owing to their ability to capture semantic meaning via dense document representations. These models, however, suffer from poor interpretability as they do not rely on explicit term matching. As a form of local per-query explanations, we introduce the notion of equivalent queries that are generated by maximizing the similarity between the NRM's results and the result set of a sparse retrieval system with the equivalent query. We then compare this approach with existing methods such as RM3-based query expansion and contrast differences in retrieval effectiveness and in the terms generated by each approach.
DeAR: Debiasing Vision-Language Models with Additive Residuals
Mar 18, 2023Large pre-trained vision-language models (VLMs) reduce the time for developing predictive models for various vision-grounded language downstream tasks by providing rich, adaptable image and text representations. However, these models suffer from societal biases owing to the skewed distribution of various identity groups in the training data. These biases manifest as the skewed similarity between the representations for specific text concepts and images of people of different identity groups and, therefore, limit the usefulness of such models in real-world high-stakes applications. In this work, we present DeAR (Debiasing with Additive Residuals), a novel debiasing method that learns additive residual image representations to offset the original representations, ensuring fair output representations. In doing so, it reduces the ability of the representations to distinguish between the different identity groups. Further, we observe that the current fairness tests are performed on limited face image datasets that fail to indicate why a specific text concept should/should not apply to them. To bridge this gap and better evaluate DeAR, we introduce the Protected Attribute Tag Association (PATA) dataset - a new context-based bias benchmarking dataset for evaluating the fairness of large pre-trained VLMs. Additionally, PATA provides visual context for a diverse human population in different scenarios with both positive and negative connotations. Experimental results for fairness and zero-shot performance preservation using multiple datasets demonstrate the efficacy of our framework.
GNNDelete: A General Strategy for Unlearning in Graph Neural Networks
Feb 26, 2023



Graph unlearning, which involves deleting graph elements such as nodes, node labels, and relationships from a trained graph neural network (GNN) model, is crucial for real-world applications where data elements may become irrelevant, inaccurate, or privacy-sensitive. However, existing methods for graph unlearning either deteriorate model weights shared across all nodes or fail to effectively delete edges due to their strong dependence on local graph neighborhoods. To address these limitations, we introduce GNNDelete, a novel model-agnostic layer-wise operator that optimizes two critical properties, namely, Deleted Edge Consistency and Neighborhood Influence, for graph unlearning. Deleted Edge Consistency ensures that the influence of deleted elements is removed from both model weights and neighboring representations, while Neighborhood Influence guarantees that the remaining model knowledge is preserved after deletion. GNNDelete updates representations to delete nodes and edges from the model while retaining the rest of the learned knowledge. We conduct experiments on seven real-world graphs, showing that GNNDelete outperforms existing approaches by up to 38.8% (AUC) on edge, node, and node feature deletion tasks, and 32.2% on distinguishing deleted edges from non-deleted ones. Additionally, GNNDelete is efficient, taking 12.3x less time and 9.3x less space than retraining GNN from scratch on WordNet18.
Towards Estimating Transferability using Hard Subsets
Jan 17, 2023



As transfer learning techniques are increasingly used to transfer knowledge from the source model to the target task, it becomes important to quantify which source models are suitable for a given target task without performing computationally expensive fine tuning. In this work, we propose HASTE (HArd Subset TransfErability), a new strategy to estimate the transferability of a source model to a particular target task using only a harder subset of target data. By leveraging the internal and output representations of model, we introduce two techniques, one class agnostic and another class specific, to identify harder subsets and show that HASTE can be used with any existing transferability metric to improve their reliability. We further analyze the relation between HASTE and the optimal average log likelihood as well as negative conditional entropy and empirically validate our theoretical bounds. Our experimental results across multiple source model architectures, target datasets, and transfer learning tasks show that HASTE modified metrics are consistently better or on par with the state of the art transferability metrics.
Towards Training GNNs using Explanation Directed Message Passing
Dec 01, 2022With the increasing use of Graph Neural Networks (GNNs) in critical real-world applications, several post hoc explanation methods have been proposed to understand their predictions. However, there has been no work in generating explanations on the fly during model training and utilizing them to improve the expressive power of the underlying GNN models. In this work, we introduce a novel explanation-directed neural message passing framework for GNNs, EXPASS (EXplainable message PASSing), which aggregates only embeddings from nodes and edges identified as important by a GNN explanation method. EXPASS can be used with any existing GNN architecture and subgraph-optimizing explainer to learn accurate graph embeddings. We theoretically show that EXPASS alleviates the oversmoothing problem in GNNs by slowing the layer wise loss of Dirichlet energy and that the embedding difference between the vanilla message passing and EXPASS framework can be upper bounded by the difference of their respective model weights. Our empirical results show that graph embeddings learned using EXPASS improve the predictive performance and alleviate the oversmoothing problems of GNNs, opening up new frontiers in graph machine learning to develop explanation-based training frameworks.
Evaluating Explainability for Graph Neural Networks
Aug 19, 2022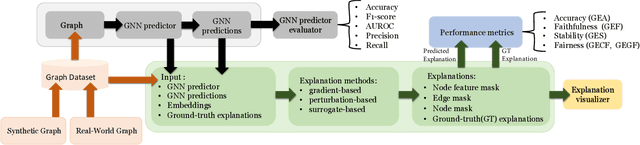
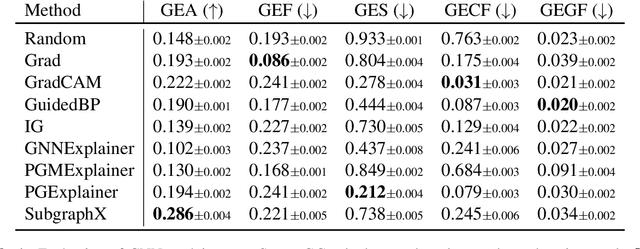
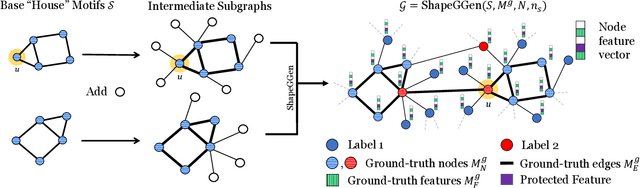

As post hoc explanations are increasingly used to understand the behavior of graph neural networks (GNNs), it becomes crucial to evaluate the quality and reliability of GNN explanations. However, assessing the quality of GNN explanations is challenging as existing graph datasets have no or unreliable ground-truth explanations for a given task. Here, we introduce a synthetic graph data generator, ShapeGGen, which can generate a variety of benchmark datasets (e.g., varying graph sizes, degree distributions, homophilic vs. heterophilic graphs) accompanied by ground-truth explanations. Further, the flexibility to generate diverse synthetic datasets and corresponding ground-truth explanations allows us to mimic the data generated by various real-world applications. We include ShapeGGen and several real-world graph datasets into an open-source graph explainability library, GraphXAI. In addition to synthetic and real-world graph datasets with ground-truth explanations, GraphXAI provides data loaders, data processing functions, visualizers, GNN model implementations, and evaluation metrics to benchmark the performance of GNN explainability methods.
OpenXAI: Towards a Transparent Evaluation of Model Explanations
Jun 22, 2022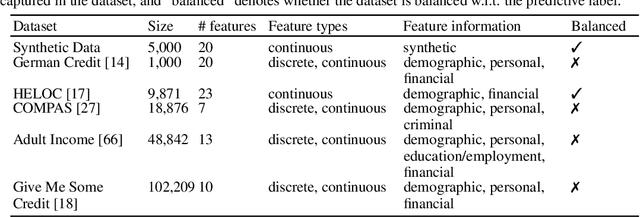
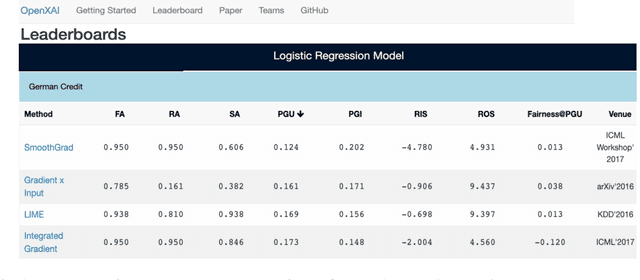
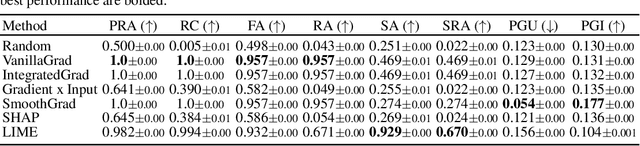
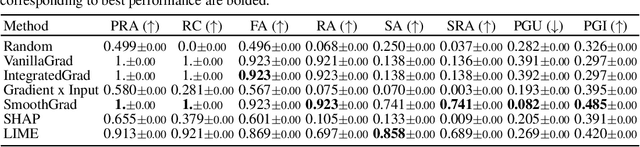
While several types of post hoc explanation methods (e.g., feature attribution methods) have been proposed in recent literature, there is little to no work on systematically benchmarking these methods in an efficient and transparent manner. Here, we introduce OpenXAI, a comprehensive and extensible open source framework for evaluating and benchmarking post hoc explanation methods. OpenXAI comprises of the following key components: (i) a flexible synthetic data generator and a collection of diverse real-world datasets, pre-trained models, and state-of-the-art feature attribution methods, (ii) open-source implementations of twenty-two quantitative metrics for evaluating faithfulness, stability (robustness), and fairness of explanation methods, and (iii) the first ever public XAI leaderboards to benchmark explanations. OpenXAI is easily extensible, as users can readily evaluate custom explanation methods and incorporate them into our leaderboards. Overall, OpenXAI provides an automated end-to-end pipeline that not only simplifies and standardizes the evaluation of post hoc explanation methods, but also promotes transparency and reproducibility in benchmarking these methods. OpenXAI datasets and data loaders, implementations of state-of-the-art explanation methods and evaluation metrics, as well as leaderboards are publicly available at https://open-xai.github.io/.
Rethinking Stability for Attribution-based Explanations
Mar 14, 2022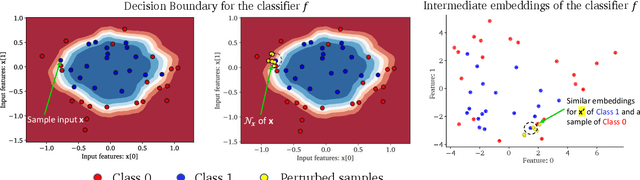


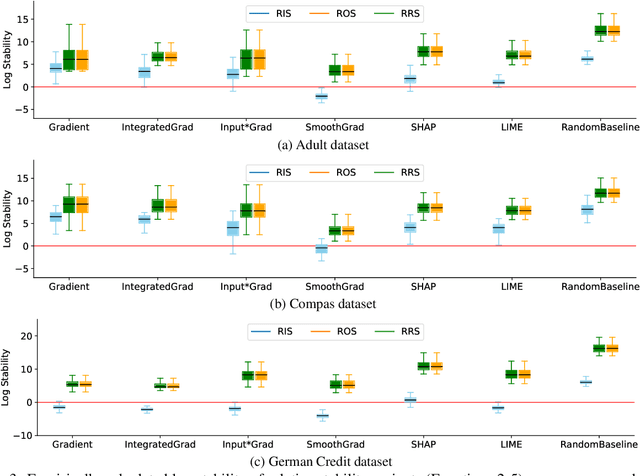
As attribution-based explanation methods are increasingly used to establish model trustworthiness in high-stakes situations, it is critical to ensure that these explanations are stable, e.g., robust to infinitesimal perturbations to an input. However, previous works have shown that state-of-the-art explanation methods generate unstable explanations. Here, we introduce metrics to quantify the stability of an explanation and show that several popular explanation methods are unstable. In particular, we propose new Relative Stability metrics that measure the change in output explanation with respect to change in input, model representation, or output of the underlying predictor. Finally, our experimental evaluation with three real-world datasets demonstrates interesting insights for seven explanation methods and different stability metrics.