 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedHopQA: A Disease-Centered Multi-Hop Reasoning Benchmark and Evaluation Framework for LLM-Based Biomedical Question Answering
May 12, 2026Evaluating large language models (LLMs) in the biomedical domain requires benchmarks that can distinguish reasoning from pattern matching and remain discriminative as model capabilities improve. Existing biomedical question answering (QA) benchmarks are limited in this respect. Multiple-choice formats can allow models to succeed through answer elimination rather than inference, while widely circulated exam-style datasets are increasingly vulnerable to performance saturation and training data contamination. Multi-hop reasoning, defined as the ability to integrate information across multiple sources to derive an answer, is central to clinically meaningful tasks such as diagnostic support, literature-based discovery, and hypothesis generation, yet remains underrepresented in current biomedical QA benchmarks. MedHopQA is a disease-centered multi-hop reasoning benchmark consisting of 1,000 expert-curated question-answer pairs introduced as a shared task at BioCreative IX. Each question requires synthesis of information across two distinct Wikipedia articles, and answers are provided in an open-ended free-text format. Gold annotations are augmented with ontology-grounded synonym sets from MONDO, NCBI Gene, and NCBI Taxonomy to support both lexical and concept-level evaluation. MedHopQA was constructed through a structured process combining human annotation, triage, iterative verification, and LLM-as-a-judge validation. To reduce leaderboard gaming and contamination risk, the 1,000 scored questions are embedded within a publicly downloadable set of 10,000 questions, with answers withheld, on a CodaBench leaderboard. MedHopQA provides both a benchmark and a reusable framework for constructing future biomedical QA datasets that prioritize compositional reasoning, saturation resistance, and contamination resistance as core design constraints.
Exploring Anti-Aging Literature via ConvexTopics and Large Language Models
Feb 23, 2026The rapid expansion of biomedical publications creates challenges for organizing knowledge and detecting emerging trends, underscoring the need for scalable and interpretable methods. Common clustering and topic modeling approaches such as K-means or LDA remain sensitive to initialization and prone to local optima, limiting reproducibility and evaluation. We propose a reformulation of a convex optimization based clustering algorithm that produces stable, fine-grained topics by selecting exemplars from the data and guaranteeing a global optimum. Applied to about 12,000 PubMed articles on aging and longevity, our method uncovers topics validated by medical experts. It yields interpretable topics spanning from molecular mechanisms to dietary supplements, physical activity, and gut microbiota. The method performs favorably, and most importantly, its reproducibility and interpretability distinguish it from common clustering approaches, including K-means, LDA, and BERTopic. This work provides a basis for developing scalable, web-accessible tools for knowledge discovery.
PDC -- a probabilistic distributional clustering algorithm: a case study on suicide articles in PubMed
Dec 04, 2019
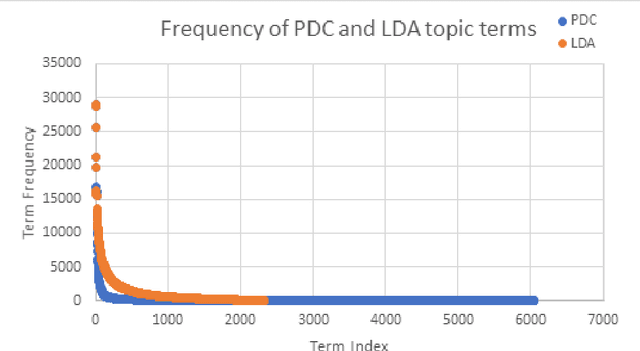
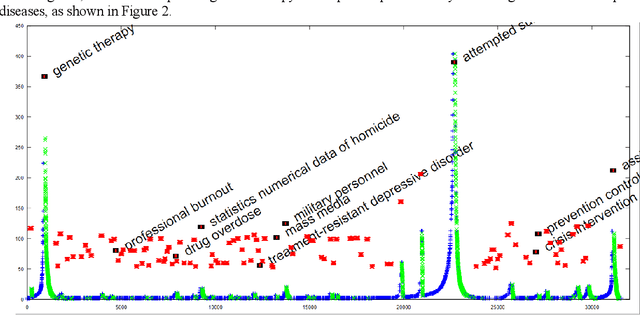

The need to organize a large collection in a manner that facilitates human comprehension is crucial given the ever-increasing volumes of information. In this work, we present PDC (probabilistic distributional clustering), a novel algorithm that, given a document collection, computes disjoint term sets representing topics in the collection. The algorithm relies on probabilities of word co-occurrences to partition the set of terms appearing in the collection of documents into disjoint groups of related terms. In this work, we also present an environment to visualize the computed topics in the term space and retrieve the most related PubMed articles for each group of terms. We illustrate the algorithm by applying it to PubMed documents on the topic of suicide. Suicide is a major public health problem identified as the tenth leading cause of death in the US. In this application, our goal is to provide a global view of the mental health literature pertaining to the subject of suicide, and through this, to help create a rich environment of multifaceted data to guide health care researchers in their endeavor to better understand the breadth, depth and scope of the problem. We demonstrate the usefulness of the proposed algorithm by providing a web portal that allows mental health researchers to peruse the suicide-related literature in PubMed.