 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Landmark Detection via Topology-Adapting Deep Graph Learning
Apr 23, 2020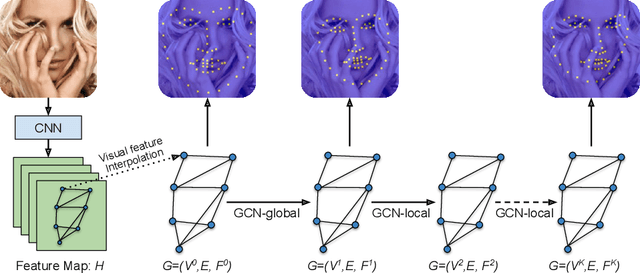
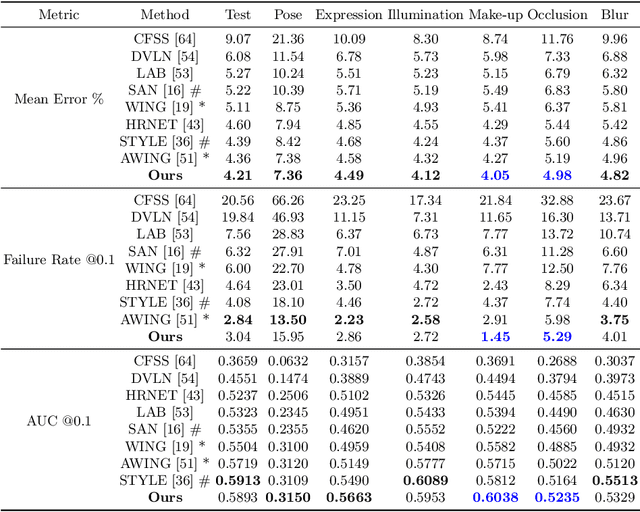

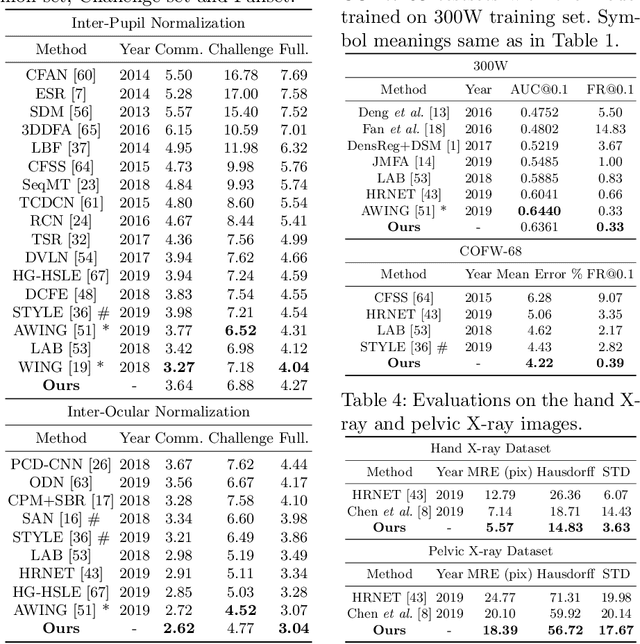
Image landmark detection aims to automatically identify the locations of predefined fiducial points. Despite recent success in this filed, higher-ordered structural modeling to capture implicit or explicit relationships among anatomical landmarks has not been adequately exploited. In this work, we present a new topology-adapting deep graph learning approach for accurate anatomical facial and medical (e.g., hand, pelvis) landmark detection. The proposed method constructs graph signals leveraging both local image features and global shape features. The adaptive graph topology naturally explores and lands on task-specific structures which is learned end-to-end with two Graph Convolutional Networks (GCNs). Extensive experiments are conducted on three public facial image datasets (WFLW, 300W and COFW-68) as well as three real-world X-ray medical datasets (Cephalometric (public), Hand and Pelvis). Quantitative results comparing with the previous state-of-the-art approaches across all studied datasets indicating the superior performance in both robustness and accuracy. Qualitative visualizations of the learned graph topologies demonstrate a physically plausible connectivity laying behind the landmarks.
CT Data Curation for Liver Patients: Phase Recognition in Dynamic Contrast-Enhanced CT
Sep 27, 2019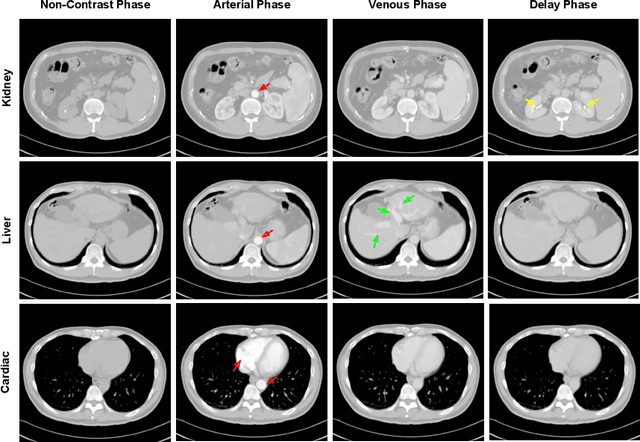
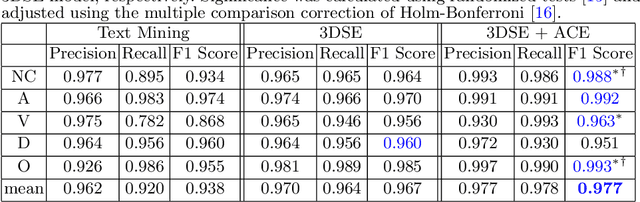
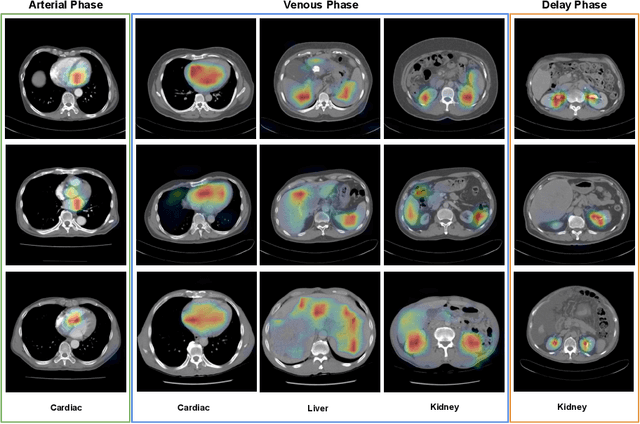

As the demand for more descriptive machine learning models grows within medical imaging, bottlenecks due to data paucity will exacerbate. Thus, collecting enough large-scale data will require automated tools to harvest data/label pairs from messy and real-world datasets, such as hospital PACS. This is the focus of our work, where we present a principled data curation tool to extract multi-phase CT liver studies and identify each scan's phase from a real-world and heterogenous hospital PACS dataset. Emulating a typical deployment scenario, we first obtain a set of noisy labels from our institutional partners that are text mined using simple rules from DICOM tags. We train a deep learning system, using a customized and streamlined 3D SE architecture, to identify non-contrast, arterial, venous, and delay phase dynamic CT liver scans, filtering out anything else, including other types of liver contrast studies. To exploit as much training data as possible, we also introduce an aggregated cross entropy loss that can learn from scans only identified as "contrast". Extensive experiments on a dataset of 43K scans of 7680 patient imaging studies demonstrate that our 3DSE architecture, armed with our aggregated loss, can achieve a mean F1 of 0.977 and can correctly harvest up to 92.7% of studies, which significantly outperforms the text-mined and standard-loss approach, and also outperforms other, and more complex, model architectures.
Weakly Supervised Universal Fracture Detection in Pelvic X-rays
Sep 04, 2019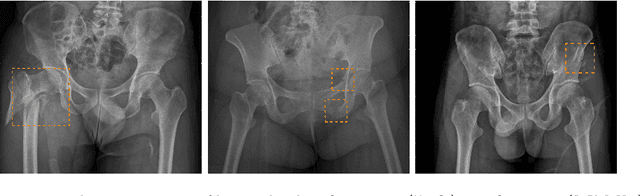
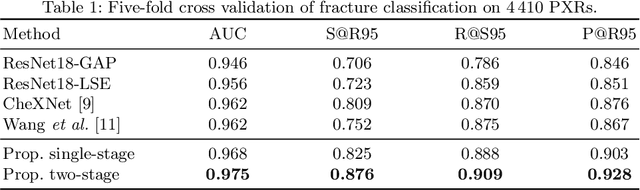
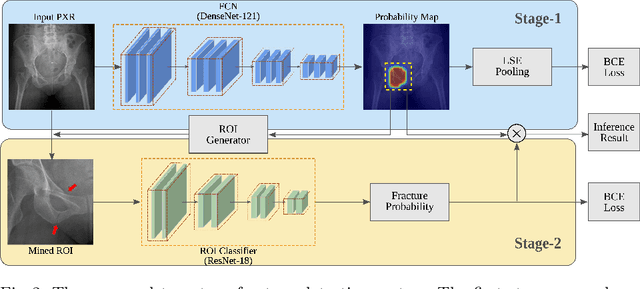
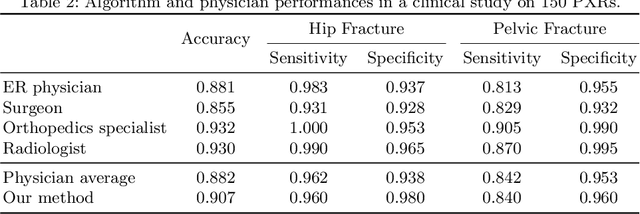
Hip and pelvic fractures are serious injuries with life-threatening complications. However, diagnostic errors of fractures in pelvic X-rays (PXRs) are very common, driving the demand for computer-aided diagnosis (CAD) solutions. A major challenge lies in the fact that fractures are localized patterns that require localized analyses. Unfortunately, the PXRs residing in hospital picture archiving and communication system do not typically specify region of interests. In this paper, we propose a two-stage hip and pelvic fracture detection method that executes localized fracture classification using weakly supervised ROI mining. The first stage uses a large capacity fully-convolutional network, i.e., deep with high levels of abstraction, in a multiple instance learning setting to automatically mine probable true positive and definite hard negative ROIs from the whole PXR in the training data. The second stage trains a smaller capacity model, i.e., shallower and more generalizable, with the mined ROIs to perform localized analyses to classify fractures. During inference, our method detects hip and pelvic fractures in one pass by chaining the probability outputs of the two stages together. We evaluate our method on 4 410 PXRs, reporting an area under the ROC curve value of 0.975, the highest among state-of-the-art fracture detection methods. Moreover, we show that our two-stage approach can perform comparably to human physicians (even outperforming emergency physicians and surgeons), in a preliminary reader study of 23 readers.