 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Approaches to Automatic Summarization in Less-Resourced Languages
Dec 30, 2025Automatic text summarization has achieved high performance in high-resourced languages like English, but comparatively less attention has been given to summarization in less-resourced languages. This work compares a variety of different approaches to summarization from zero-shot prompting of LLMs large and small to fine-tuning smaller models like mT5 with and without three data augmentation approaches and multilingual transfer. We also explore an LLM translation pipeline approach, translating from the source language to English, summarizing and translating back. Evaluating with five different metrics, we find that there is variation across LLMs in their performance across similar parameter sizes, that our multilingual fine-tuned mT5 baseline outperforms most other approaches including zero-shot LLM performance for most metrics, and that LLM as judge may be less reliable on less-resourced languages.
OpenNER 1.0: Standardized Open-Access Named Entity Recognition Datasets in 50+ Languages
Dec 12, 2024We present OpenNER 1.0, a standardized collection of openly available named entity recognition (NER) datasets. OpenNER contains 34 datasets spanning 51 languages, annotated in varying named entity ontologies. We correct annotation format issues, standardize the original datasets into a uniform representation, map entity type names to be more consistent across corpora, and provide the collection in a structure that enables research in multilingual and multi-ontology NER. We provide baseline models using three pretrained multilingual language models to compare the performance of recent models and facilitate future research in NER.
Investigating LLM Applications in E-Commerce
Aug 23, 2024



The emergence of Large Language Models (LLMs) has revolutionized natural language processing in various applications especially in e-commerce. One crucial step before the application of such LLMs in these fields is to understand and compare the performance in different use cases in such tasks. This paper explored the efficacy of LLMs in the e-commerce domain, focusing on instruction-tuning an open source LLM model with public e-commerce datasets of varying sizes and comparing the performance with the conventional models prevalent in industrial applications. We conducted a comprehensive comparison between LLMs and traditional pre-trained language models across specific tasks intrinsic to the e-commerce domain, namely classification, generation, summarization, and named entity recognition (NER). Furthermore, we examined the effectiveness of the current niche industrial application of very large LLM, using in-context learning, in e-commerce specific tasks. Our findings indicate that few-shot inference with very large LLMs often does not outperform fine-tuning smaller pre-trained models, underscoring the importance of task-specific model optimization.Additionally, we investigated different training methodologies such as single-task training, mixed-task training, and LoRA merging both within domain/tasks and between different tasks. Through rigorous experimentation and analysis, this paper offers valuable insights into the potential effectiveness of LLMs to advance natural language processing capabilities within the e-commerce industry.
QueryNER: Segmentation of E-commerce Queries
May 15, 2024



We present QueryNER, a manually-annotated dataset and accompanying model for e-commerce query segmentation. Prior work in sequence labeling for e-commerce has largely addressed aspect-value extraction which focuses on extracting portions of a product title or query for narrowly defined aspects. Our work instead focuses on the goal of dividing a query into meaningful chunks with broadly applicable types. We report baseline tagging results and conduct experiments comparing token and entity dropping for null and low recall query recovery. Challenging test sets are created using automatic transformations and show how simple data augmentation techniques can make the models more robust to noise. We make the QueryNER dataset publicly available.
LR-Sum: Summarization for Less-Resourced Languages
Dec 19, 2022This preprint describes work in progress on LR-Sum, a new permissively-licensed dataset created with the goal of enabling further research in automatic summarization for less-resourced languages. LR-Sum contains human-written summaries for 40 languages, many of which are less-resourced. We describe our process for extracting and filtering the dataset from the Multilingual Open Text corpus (Palen-Michel et al., 2022). The source data is public domain newswire collected from from Voice of America websites, and LR-Sum is released under a Creative Commons license (CC BY 4.0), making it one of the most openly-licensed multilingual summarization datasets. We describe how we plan to use the data for modeling experiments and discuss limitations of the dataset.
Toward More Meaningful Resources for Lower-resourced Languages
Feb 24, 2022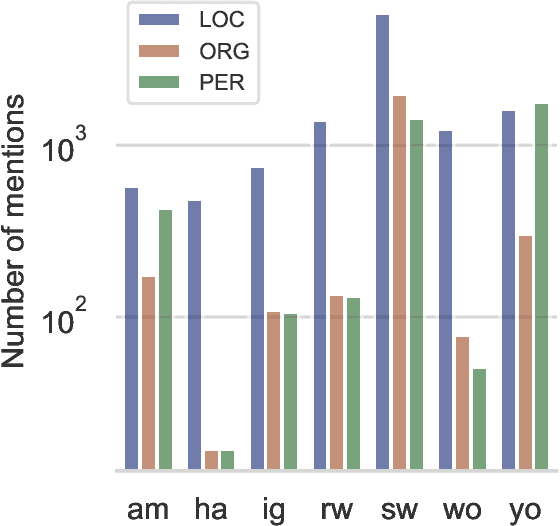
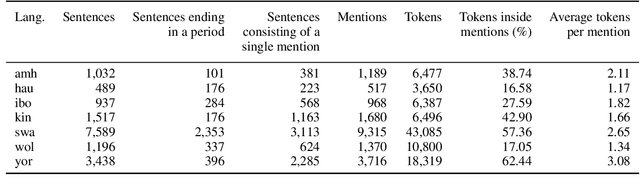
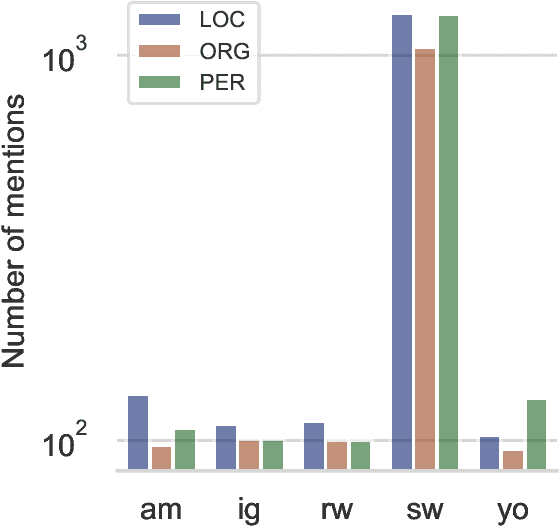
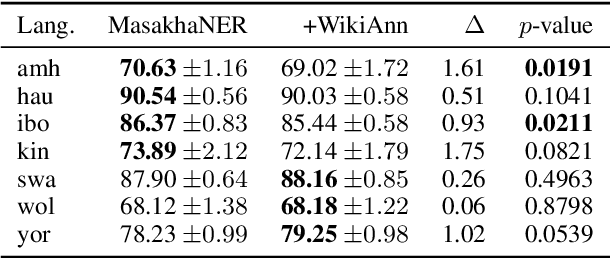
In this position paper, we describe our perspective on how meaningful resources for lower-resourced languages should be developed in connection with the speakers of those languages. We first examine two massively multilingual resources in detail. We explore the contents of the names stored in Wikidata for a few lower-resourced languages and find that many of them are not in fact in the languages they claim to be and require non-trivial effort to correct. We discuss quality issues present in WikiAnn and evaluate whether it is a useful supplement to hand annotated data. We then discuss the importance of creating annotation for lower-resourced languages in a thoughtful and ethical way that includes the languages' speakers as part of the development process. We conclude with recommended guidelines for resource development.
Multilingual Open Text 1.0: Public Domain News in 44 Languages
Jan 14, 2022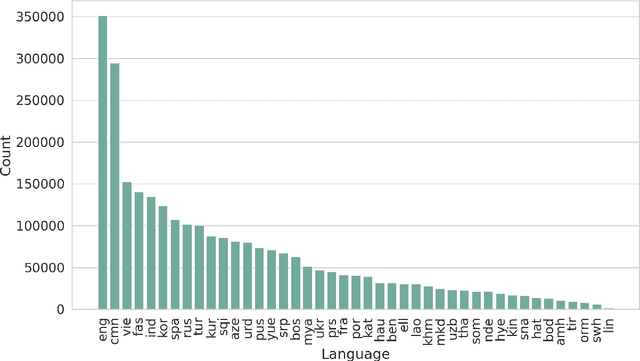
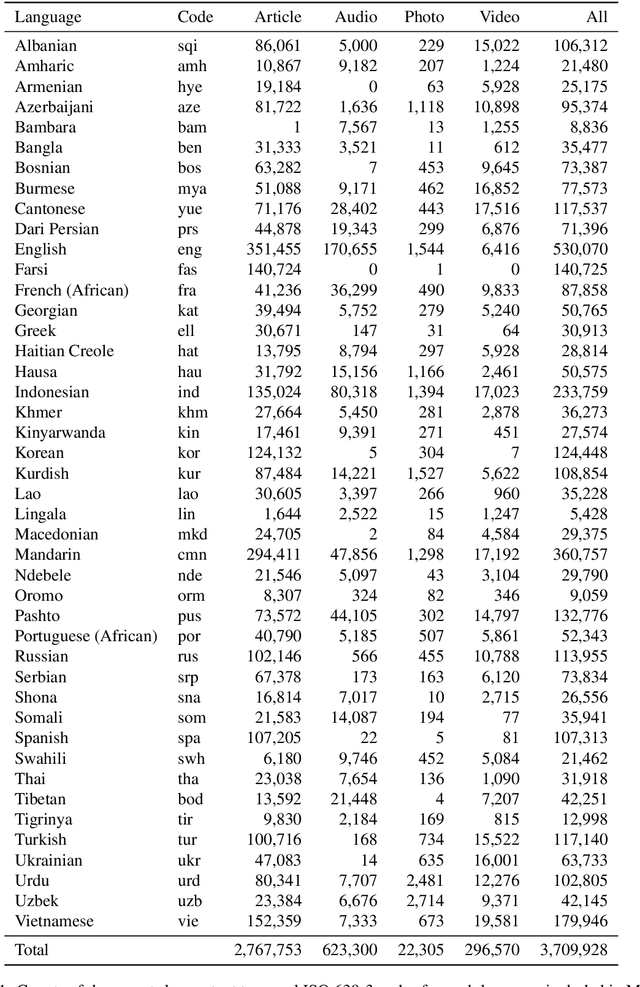
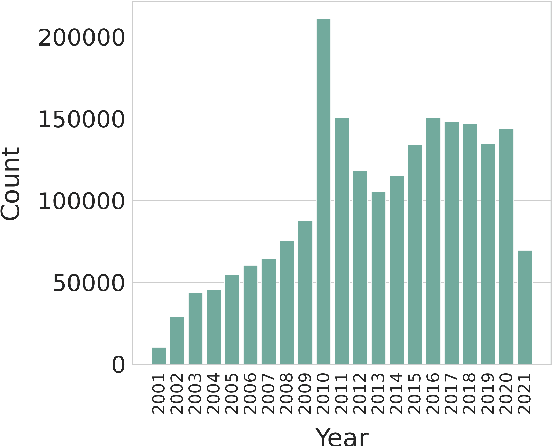

We present a new multilingual corpus containing text in 44 languages, many of which have relatively few existing resources for natural language processing. The first release of the corpus contains over 2.7 million news articles and 1 million shorter passages published between 2001--2021, collected from Voice of America news websites. We describe our process for collecting, filtering, and processing the data. The source material is in the public domain, our collection is licensed using a creative commons license (CC BY 4.0), and all software used to create the corpus is released under the MIT License. The corpus will be regularly updated as additional documents are published.
Addressing Barriers to Reproducible Named Entity Recognition Evaluation
Jul 29, 2021
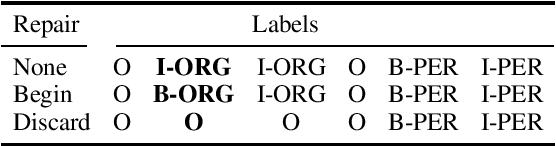

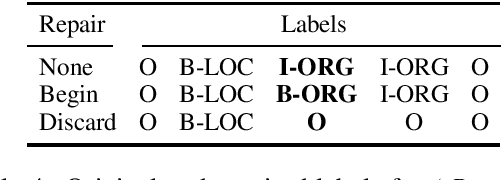
To address what we believe is a looming crisis of unreproducible evaluation for named entity recognition tasks, we present guidelines for reproducible evaluation. The guidelines we propose are extremely simple, focusing on transparency regarding how chunks are encoded and scored, but very few papers currently being published fully comply with them. We demonstrate that despite the apparent simplicity of NER evaluation, unreported differences in the scoring procedure can result in changes to scores that are both of noticeable magnitude and are statistically significant. We provide SeqScore, an open source toolkit that addresses many of the issues that cause replication failures and makes following our guidelines easy.
MasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021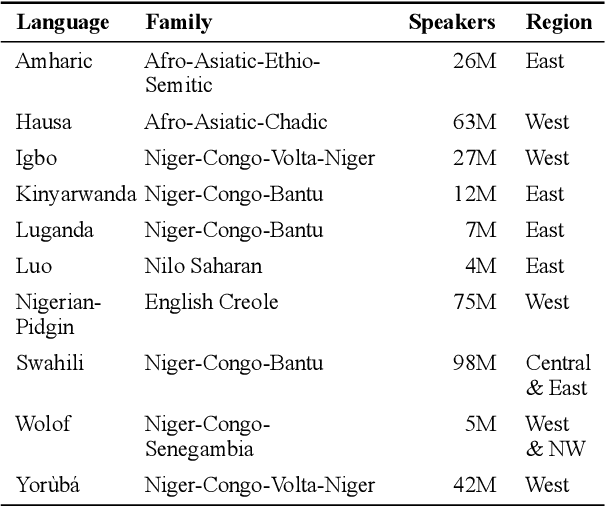

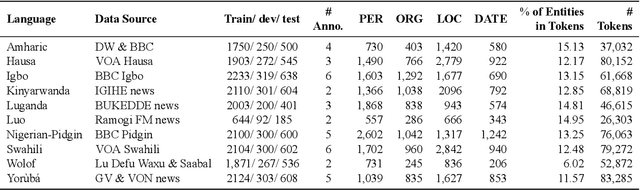
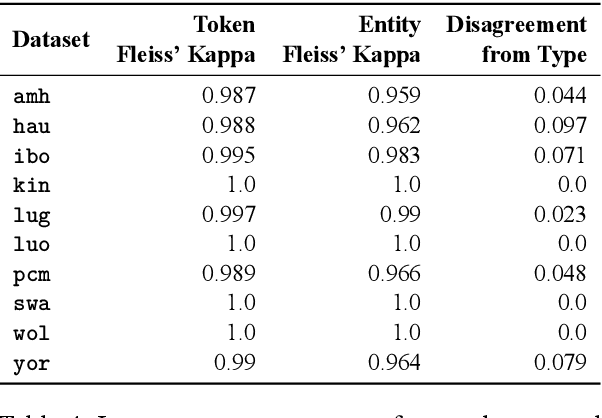
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.