 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionDiffuser: Controllable Multi-Agent Motion Prediction using Diffusion
Jun 05, 2023



We present MotionDiffuser, a diffusion based representation for the joint distribution of future trajectories over multiple agents. Such representation has several key advantages: first, our model learns a highly multimodal distribution that captures diverse future outcomes. Second, the simple predictor design requires only a single L2 loss training objective, and does not depend on trajectory anchors. Third, our model is capable of learning the joint distribution for the motion of multiple agents in a permutation-invariant manner. Furthermore, we utilize a compressed trajectory representation via PCA, which improves model performance and allows for efficient computation of the exact sample log probability. Subsequently, we propose a general constrained sampling framework that enables controlled trajectory sampling based on differentiable cost functions. This strategy enables a host of applications such as enforcing rules and physical priors, or creating tailored simulation scenarios. MotionDiffuser can be combined with existing backbone architectures to achieve top motion forecasting results. We obtain state-of-the-art results for multi-agent motion prediction on the Waymo Open Motion Dataset.
JFP: Joint Future Prediction with Interactive Multi-Agent Modeling for Autonomous Driving
Dec 16, 2022



We propose JFP, a Joint Future Prediction model that can learn to generate accurate and consistent multi-agent future trajectories. For this task, many different methods have been proposed to capture social interactions in the encoding part of the model, however, considerably less focus has been placed on representing interactions in the decoder and output stages. As a result, the predicted trajectories are not necessarily consistent with each other, and often result in unrealistic trajectory overlaps. In contrast, we propose an end-to-end trainable model that learns directly the interaction between pairs of agents in a structured, graphical model formulation in order to generate consistent future trajectories. It sets new state-of-the-art results on Waymo Open Motion Dataset (WOMD) for the interactive setting. We also investigate a more complex multi-agent setting for both WOMD and a larger internal dataset, where our approach improves significantly on the trajectory overlap metrics while obtaining on-par or better performance on single-agent trajectory metrics.
Narrowing the Coordinate-frame Gap in Behavior Prediction Models: Distillation for Efficient and Accurate Scene-centric Motion Forecasting
Jun 10, 2022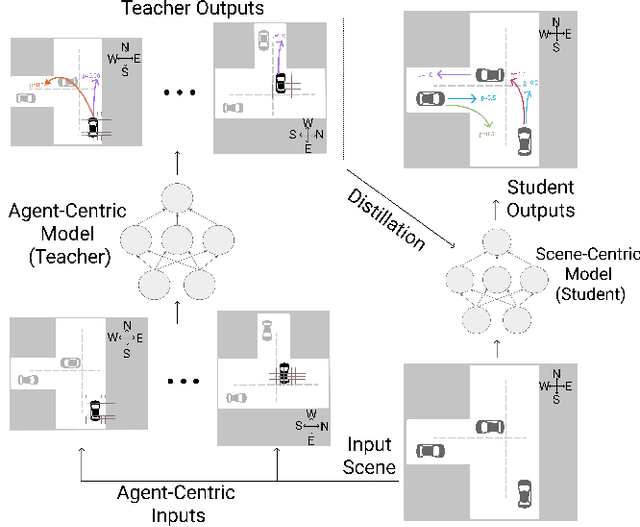
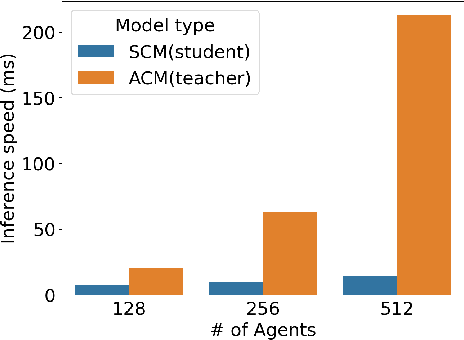
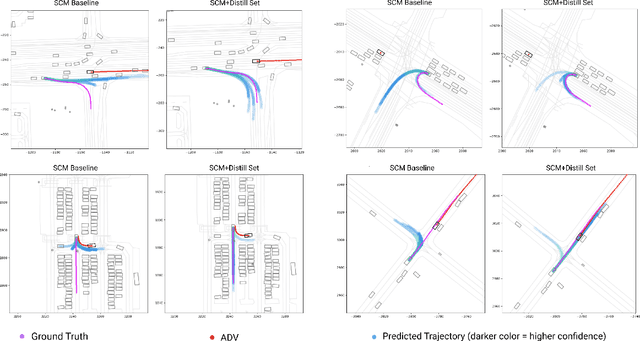
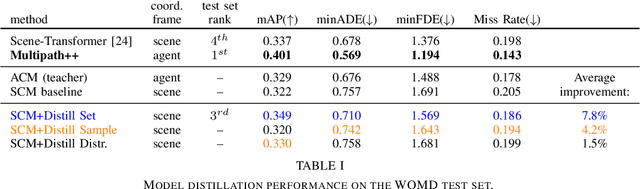
Behavior prediction models have proliferated in recent years, especially in the popular real-world robotics application of autonomous driving, where representing the distribution over possible futures of moving agents is essential for safe and comfortable motion planning. In these models, the choice of coordinate frames to represent inputs and outputs has crucial trade offs which broadly fall into one of two categories. Agent-centric models transform inputs and perform inference in agent-centric coordinates. These models are intrinsically invariant to translation and rotation between scene elements, are best-performing on public leaderboards, but scale quadratically with the number of agents and scene elements. Scene-centric models use a fixed coordinate system to process all agents. This gives them the advantage of sharing representations among all agents, offering efficient amortized inference computation which scales linearly with the number of agents. However, these models have to learn invariance to translation and rotation between scene elements, and typically underperform agent-centric models. In this work, we develop knowledge distillation techniques between probabilistic motion forecasting models, and apply these techniques to close the gap in performance between agent-centric and scene-centric models. This improves scene-centric model performance by 13.2% on the public Argoverse benchmark, 7.8% on Waymo Open Dataset and up to 9.4% on a large In-House dataset. These improved scene-centric models rank highly in public leaderboards and are up to 15 times more efficient than their agent-centric teacher counterparts in busy scenes.